使用Python将Utzoo-Wiseman Usenet磁带转换为PostgreSQL后端
最近,我偶然看到一个资源,它允许我下载UTZOO网络新闻档案中最早的Usenet帖子的全部集合。这些基本上是已经连接到互联网的各个大学的工作人员在互联网上发布的最早的可用讨论。这些档案馆在1981年2月至1991年6月期间设立了大约210万个职位。本文描述了如何将这些磁带转换成完全可搜索的PostgreSQL数据库,然后再转换到usenetArchives.com网站。
直到2001年,这些早期的Usenet讨论都被认为是丢失的,但神奇的是,多伦多大学动物系的亨利·斯宾塞(Henry Spencer)奇迹般地将其备份到磁带上,并将其保存了这么多年(显然花费了很大的代价)。
H·斯宾塞一共有141盘这样的磁带,但都没有用,所以最终,他和大卫·怀斯曼(他用一辆皮卡来回拖着141盘磁带)、兰斯·贝利、布鲁斯·琼斯、鲍勃·韦伯、布鲁斯特·卡勒和苏·蒂伦等几个积极进取的人开始了一个将所有这些磁带转换成常规格式的过程,每个人都可以接触到这些磁带。
好吧,没那么快,在我解压数据之后,我意识到TGZ格式实际上包含数百万个小文本文件(每个帖子都在它自己的文件中)。虽然这本书很棒,但它不是我或任何人都能读懂的。当然不是在讨论形式的论坛上。目前还不清楚哪个帖子是引发讨论的帖子,也不清楚哪些帖子是对该帖子的回复。忘了搜索这些文件吧,那是完全不可能的。简单地说,我花了5个多小时才解开档案。
也就是说,没过多久,我就决定开发一个基于Python的转换器,使我能够将整个集合从数百万个平面文件转换成一个完全可搜索的PostgreSQL数据库。下面的帖子将讨论这一过程,并包括作为开源发布的解决方案的Python代码。
下载后,您将看到归档文件包含161x个tar归档文件。它看起来是这样的:
于是,我从https://www.7-zip.org那里拿了一份7-Zip压缩包,开始解压缩文件。
我最终在56,988个文件夹中得到了超过2104,828个纯文本文件,这是亨利·斯宾塞的Usenet档案的完整副本。
对于那些喜欢数字的人,这里有每个Utzoo磁带及其大小、文件和文件夹的数量:
在检查解压文件时,我意识到磁带118解压在\utzoo-Wiseman-Usenet-ARCHIVE\news 118f1文件夹中,名为tape118,所以我将其重命名为Tape118.tar并手动解压,结果才意识到它是我已经拥有的文件的副本。创建原始存档的人忘记删除该文件。这些文件夹中有3个文件需要添加并解压缩.tar扩展名:
如果您打开其中一个文件夹并向下导航到众多子文件夹中的一个,您会发现包含该邮件的文件。例如,进入\utzoo-wiseman-usenet-archive\news006f1\b15\net\aviation文件夹,我现在显然是在net.Aviation Usenet组中。但唯一能找到答案的方法就是打开其中一个文件,看看里面的内容。我在这里强调了它看起来是什么样子。正如您所看到的,每个文件似乎都包含一个标题,然后是一个空行和消息正文:
因此,我决定构建一个Python解析器,它遍历所有这些文件,读取每条消息的头部分,并将所有唯一的结果组合在一起,给出所有可能的头信息,例如(From、Subject、Newsgroup等)。我发现大约有79种不同类型的标题。因此,似乎并不是所有的信息都遵循相同的基本结构。通过查看标题,所有帖子都采用了所有帖子通用的标准设置。
一旦我有了公共字段,我就创建了一个名为‘utzoo’的Postgres数据库。
上述数据库和架构是先决条件。其他所有事情,如创建表、插入帖子等,都是Python脚本的一部分,并且是完全自动化的。
在创建表方面,该脚本自动为每个检测到的新闻组创建5个表:
创建表ALL_MESSAGES。GroupName_Headers(id bigSerial NOT NULL约束GroupName_Headers_pk主键,日期解析时间戳,subj_id bigint,ref mall int,msg_id text,msg_from bigint,enc text,contype text,Proceded Timestamp Default Current_Timestamp);将表all_Messages.GroupName_Headers Owner更改为Postgres;创建表all_Messages。GroupName_refs(id bigint,ref_msg text Default NULL);将表all_Messages.GroupName_refs Owner更改为Postgres;创建表all_Messages。GroupName_Body(id bigint主键,数据文本默认为NULL);将表ALL_Messages.GroupName_Body Owner改为Postgres;创建表ALL_MESSAGES。GroupName_from(id序列非空约束GroupName_from_pk主键,数据文本);将表ALL_Messages.GroupName_from Owner更改为Postgres;创建表ALL_MESSAGES。GroupName_Subjects(id序列非空约束GroupName_Subjects_PK主键,主题文本);将表ALL_Messages.GroupName_Subjects Owner改为Postgres;
这些表将是Python解析器将转储所有数据的表,并确保表之间的POST排列正确。
Python脚本还创建了索引,以便更快地插入和稍后阅读帖子:
在all_Messages.GroupName_Headers(Id)上创建唯一索引GroupName_Headers_uiidx;在all_Messages.GroupName_Headers(Msg_Id)上创建唯一索引GroupName_Headers_umidx;在all_Messages.GroupName_Body(Id)上创建唯一索引GroupName_body_idx;在all_Messages.GroupName_from_idx上创建唯一索引GroupName_from_idx。
下面的屏幕截图解释了它是如何连接在一起的。我没有做任何硬编码的关系,但是如果你愿意,你可以改变脚本。
日期是每条消息不可或缺的一部分,我必须在Python中进行一些数据转换处理才能获得正确的日期,因为日期的格式多种多样。我尝试过各种库,但针对Python的dateutil.parser.parse标准日期和时间库做得最好。
然而,我仍然需要考虑标题中数据字段的各种标签,所以如果在“Date”标题中找不到数据,我就不得不查找其他标题部分,如“nntp-Posting-Date”、“X-文章-Creation-Date”、“Pasted”、“”或“Receive”字段。
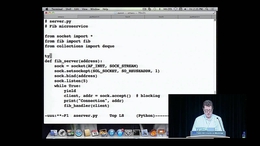
然后创建一个Python解析器,启动PostgreSQL,将其指向存档目录,然后等待:)。
本文的底部是Python解决方案的代码。它大约有1000行,总共花了大约1天的时间来创建和测试它。该脚本足够智能,可以跟踪它从哪里开始,因此如果需要中断,它将知道从哪里继续完成工作。
最终的解决方案构件名为‘utzoo2postgres.py’,并在Python3.8上进行了测试。
注意:如果您需要停止程序并稍后运行它,脚本最好从它正在处理的最后一个位置继续运行。
该脚本将在大约6小时内处理所有Utzoo存档消息(取决于您机器的速度)。
以下是仅转换几分钟后的数据库屏幕截图:
如您所见,转换实用程序为每个组生成一个包含5个表的数据库,其中消息通过自动创建的索引相互链接。
比方说,我们想要在网上查找所有讨论。物理讨论;并根据回复的数量对它们进行排序。
现在,我们可以通过ID来查找特定的讨论。例如,我们想要上面屏幕截图中的ID:1648,主题是“关于FTL和量子力学的问题”。这也不是很难:
拥有一个满是帖子的数据库固然不错,但以这种方式很难使用。我需要一些能让我轻松访问这些帖子的东西。
所以,当一切都完成后,我围绕这段代码构建了一个php脚本,并注册了https://usenetarchives.com,以便在一个易于阅读和搜索(类似论坛)的网站上提供所有这些档案。
PHP代码不是本文的一部分,但是您可以转到https://usenetarchives.com/groups.php?c=utzoo查看它是如何工作的:
所以现在一切都完成了,我不得不说,这是一次伟大的旅程。
对于那些想要玩代码的人,你可以从Github那里拿到它,然后根据自己的喜好进行调整。请不要评判代码,它不美观,也不格式化或注释掉(在很大程度上),因为我并不完全打算发布它。我这么做主要是出于子孙后代的原因。但是现在它已经发布了,我们非常欢迎您分叉repo,清理它并提交您的更改,这样其他人也可以从您的工作中受益。
作为本文的总结,下面展示了从每个文件获取信息到PostgreSQL数据库的过程。
7.结果:PostgreSQL完全可搜索到1981年2月和1991年6月丢失的所有Usenet帖子的数据库