半小时学习r
KarolisKoncevičius这篇文章受到类似于Rust(1)的类似教程的启发,试图在30分钟的时间跨度中跨越R语言的主要特征。介绍了vectorisation,回收,子集等大多数R特定概念。矩阵和数据。帧对象以及目前省略了Constrol语句和功能/对象声明的各种构建。
R在多种不同的对象类型中存储数据.Below是不同类型的某些对象:
nan#double"不是数字" inf#double"无限" -inf#double"负无限" na#逻辑"缺少" valuena_integer_#整数"缺少" valuena_real_#double"缺少" valuena_complex_#complex"缺少" valuena_character_#字符"缺少" Valuenull#特殊变量没有类型
+#添加 - #减法/#division *#乘法^#POWER **#替代电力符号! #否定& #逻辑和| #逻辑或==#等于!=#不是等于> #大于> =#大于或等于< #小于< =#小于或等于
真实|假2 + 2 3 * 103 + 0i + 0 + 1i 3 == 10 4< inf" a" !=" B"
10/0#INF -2 / 0#-INF 0/0#NAN-1 + 0i / 0#nan + nani
1 ^ na#12 ^ na#nana ^ 0#1true | na#truetrue& na#nafalse | na#nafalse& na#false.
由于键盘上的可用符号不足以覆盖所有必要的运算符,因此通过百分比符号%括起来定义了其他使用的运算符:
%/%#整数分割%%#剩余分割后(modulo)27%/%24#结果= 127 %% 24#结果= 3
变量名称必须以点或字母开头,只包含字母,数字,点和下划线。他们不能覆盖现有的特殊值,如na和true.threve赋值运算符来实现同一件事:
此外,r允许定义“非语法”标识符。标准变量名称必须遵循定义的规则,但反向点引号强制将任何字符串评估为标识符:
x< - 12< - 1#error`2< - 1#绕过正常评估和治疗" 2"作为可变名称x#标准方式引用名为&#34的变量; x"`x`#是指双层2`#的相同变量2#对象2。是指非语法变量" 2&# 34;
通过用传递的参数列表键入函数名称和括号来调用函数.Parameters可以由其职位或其名称指定。
以前展示的所有运算符也是功能,可以以相同的方式调用:
帮助(语法)#读取关于优先级别的precequeld leomshelp(保留)#r' s保留symbolshelp(numericConstants)#解析器规则的r'用于处理数字常量shelp(引用)#解析器规则以处理引用字符串的规则
R的几乎每个对象都是矢量化 - 它可以包含多个元素,并且具有称为“长度”的属性。
Vec1< - c(1,2)vec2< c(2,3)c(vec1,vec2)c(c(1,2),c(2,3))#samec(c(1,2 ,2,3))#也是samec(1,2,2,3)#也是
c(true,1l)#integerc(true,1)#doublec(1l,1 + 1i)#creadcc(true," a" a")#characterc(na_integer_,na_real_)#double
X< c(1,2,3)y y< c(0,10,1)x + 1#2 3 4x + y#1 12 4x> 2#false false truex> y#false true false
x< c(1,2,3,4,5)y y< c(2,1,3,1,5)平均值(x)和(y)log2(x)cor(x,y)粘贴(x,y)
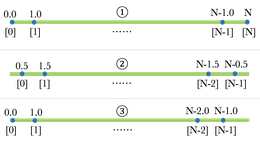
r可以在不同长度的矢量上应用二进制运算符。在这种情况下,发生回收 - 较短的向量扩展到通过从第一个启动的元素回收其元素来延长较短的向量,以匹配较长的矢量:
x< c(1,1,1,1)y y< c(0,1)#原始RecyLcingx + Y#x = 1 1 1 1 1 1 1 x = 1 1 1 1#y = 0 1 y = 0 1 0 1
#从XX x的每个元素中减去1(1,2,3,4)x-1#检查x的哪个元素大于2x&lt; c(1,2,3,4)x&gt; 2#将x到0x的每个第二元素转动,x至0x&lt; c(1,2,3,4)y < - c(0,1)x * y
当较长的向量不是较短的一个 - 回收的倍数时,会发生警告:
c(1,2,3) - c(0,1)#警告消息:#在c(1,2,3) - c(0,1)中:#较长的对象长度不是较短的对象长度的倍数
矢量可以作为元素数组被视为元素,因此我们可能希望仅通过选择这些元素的一小部分来子集。在使用[运算符。
可以通过指定所需位置来选择元素(R中的编号从1开始)。
x&lt; c(10,20,30,40)x [4] x [1:2] x [0]#选择&#34;没有#34; - 返回空vectorx [c(1,1)]#可以选择多个timex [5]#na(具有未知值的元素)
x&lt; c(10,20,30,40)x [-1] x [c(-1,-3)] x [c(-1,-1)]#相同元素是&#34;删除两次&#34; x [-5]#&#39; t以任何方式更改x
如果要返回元素,则可以通过指定true来选择元素,否则为false:
x&lt; c(10,20,30,40)x [c(true,false,false,false)] x [c(true,true,false,true)] x [c(false,true)]# c(false,true)回收 - 返回每个第二个元素#一个有趣的explatex [x&gt; 20]#1)x&gt; 20将X的每个元素与20(20是再循环)#2)进行比较。 20为X#3中的每个元素创建所获得的矢量的索引矢量的索引矢量,然后将所获得的向量用于子集x#4),结果仅返回大于20的x元素
x&lt; - c(a = 10,b = 20,c = 30,d = 40)x [&#34; a&#34;] x [c(&#34; a&#34;&#34; B&#34;)] x [c(&#34; e&#34;)]#na - 具有未知valuex [-c(&#34; a&#34;)]#错误 - 此语法不能用于丢弃元素#当名称不是唯一 - 第一匹配元素是返回x&lt; - c(a = 10,b = 20,b = 30,d = 40)x [&#34; b&#34;]#20
X&lt; - C(10,20,30,40)X [4]×[4]&lt; - C(51)X [C(1,3)]&lt; -c(12,32)x [0]&lt; - 0#DON&#39; t做任何物品x [5]&lt; - 50#附录&#34; z&#34;到VectorXX [10]的第五位置&lt; - 100#附录&#34; z&#34;到第10个位置,增加了第6次:9
X&lt; - C(10,20,30,40)X [-C(1,2,3)]&lt; - 41×[-1]&lt; - c(22,32,43)x [-5] &lt; - 100#将替换每个元素
x&lt; c(10,20,30,40)x [c(true,false,true,false)]&lt; - c(11,31)x [c(true,true,true,false)]&lt ; - C(11,31)#C(11,31)将被RECYCLEDX [C(FALSE,TRUE)]&lt; -c(22,42)#c(false true)将被回收x[x&lt; 10]&lt; - na
X&lt; - C(a = 10,b = 20,c = 30,d = 40)x [&#34; b&#34;]&lt; - 21x [c(&#34; a&#34;,& #34; d&#34;)]&lt; - c(11,41)x [&#34; z&#34;]&lt; - 2#将附加一个名为&#34; z&#34;#何时的新元素名称不是唯一的 - 第一匹配元素是替换x&lt; c(a = 10,b = 20,b = 30,d = 40)x [&#34; b&#34;]&lt; - 21#替换b = 20个元素
x&lt; c(10,20,30,40)x&lt; - 0#用0x []&lt; - 0#用0替换x的所有元素
x&lt; c(1,2,3,4)#x是双x [4]&lt; - &#34; e&#34; #x现在是个性
在向量中,所有元素都具有相同类型.List可以存储不同类型的多个元素。
l&lt;列表(C(&#34; a&#34;&#34; b&#34; b&#34;),c(true,false),1:100)长度(l)#长度是元素的赘述列表:3
列表(列表(1,3 + 0i),列表(&#34; a&#34;)列表(列表(1,3 + 0i),&#34; a&#34;)#一个列表可以有两个列表和简单的Vectorslist(列表(1,列表(&#34; a&#34;)))#列表可以嵌套两个以上的deeplist(a = true,b = 1:100)#列表元素可以有名称
特殊双括号[[操作员用于从列表中提取元素。但它只允许索引正数和名称:
l&lt;列表(a = true,b = c(&#34; a&#34;和#34; b&#34;),c = 1:100)l [[1] ##的第一元素listl [[c(1,2)]]#错误 - 无法返回两个对象,而无需列表以保存hemll [[ - c(1,2)]]#错误 - 负指数不能用于列表元素[[c (true,false,true)]]#错误 - 逻辑索引不能使用[[c(&#34; a&#34;)] l [[c(&#34; a&#34;&#34; B&#34;)]]
l&lt;列表(列表(true),列表(列表(1,2:3))l [[1]]#选择一个元素 - listl [[1]] [[1]#选择第二个元素从第一个元素(列表)l [[2]] [[1]] [[1]]#深度嵌套选择(难以描述,抱歉!)l [[2]] [[1] [2] ] [2]#选择深度嵌套矢量的元素
l&lt;列表(a = true,b = c(&#34; a&#34;,&#34; b&#34;),c = 1:100)l [[1]]&lt; - false#将第一个列表元素替换为falsel [1]&lt;列表(false)#与abovel [1]&lt; shall#也与abovel相同[[1]]&lt; list(false)#!用listl [2]替换第一个元素&lt; - null#从列表中删除第二个元素
l&lt; list(列表(true),列表(列表(1,2:3))l [[1]] [[1]]&lt; - falsel [[2]] [[1]] [[1]] [[ 1]]&lt; [2]] [[1]] [[2]] [[2]] [[2]] [[2]] [[2]] [[2]] [[2]] [[2]] [[2]] [[2]]&lt; - list()#替换整个嵌套列表
按名称从列表中选择单个元素是频繁的过程,因此它有一个快捷操作员:
l&lt; list(a = true,b = c(&#34; a&#34;和#34; b&#34;),c = list(c1 = 1,c2 = 2))l $ a#与l [[&#34; a&#34;]] l $ c#与l [&#34; c&#34;]] l $ c $ c1#与l [[&#34; c& #34;]] [[&#34; c1&#34;]]]
l&lt;列表(a = true,b = c(&#34; a&#34;&#34; b&#34;),c = list(c1 = 1,c2 = 2))l $ a&lt ; - false#替换元素&#34; a&#34; l $ c $ c $ c1&lt; - 0#替换&#34; c1&#34;列表&#34; c&#34; l $ c&lt; - na#替换整个&#34; c&#34;列表与对象na
矩阵是具有额外的尺寸的载体.Below是创建矩阵的多等同方式:
由于矩阵由vector构造 - 可以将包括列表的任何向量类型,可以变成矩阵:
矩阵(c(true,false,true,false),nrow = 2,ncol = 2)矩阵(1:4,nrow = 2,ncol = 2)矩阵(c(&#34; a&#34;,&# 34; B&#34;,&#34; C&#34;,&#34; d&#34;),nrow = 2,ncol = 2)矩阵(列表(true,2,&#34; a&#34; ,3 + 0i),nrow = 2,ncol = 2)
在引擎盖下,矩阵是一个向量,通过首先填充第一列,然后第二列,等等,将“折叠”成矩阵形式:
x&lt; 1:20matrix(x,ncol = 4)#[,1] [,2] [,3] [,4]#[1,] 1 6 11 16#[2,] 2 7 12 17# [3,] 3 8 13 13 18#[4,] 4 9 14 19#[5,] 5 10 15 20
所有运营商都在向量上处理矩阵作为向量。在向矩阵添加到矩阵时会发生什么:
x&lt; - 矩阵(1:8,nrow = 4)v&lt; - 1:2x + v#1)x被夷为载载体1 2 3 4 5 6 7 8#2)V被再循环以匹配X 1 2 11 2 1 2 1 2 1 2 1 2 1 2#3)元素的加法24 4 4 6 6 8 9 10#4)x再次被重新折叠成矩阵,按列列:#[,1] [,2]#[1,] 2 6#[2,] 4 8#[3,] 4 8#[4,] 6 10
x&lt; - 矩阵(1:20,nrow = 4)y y&lt;矩阵(runif(20),nrow = 4)x + 1#为每个数量的matrixx&gt添加元素; 2#将矩阵的每个元素与来自另一个矩阵的NumberX / Y#划分元素。 Y#比较两个矩阵元素-Wisex - Rowmeans(x)#减去每行矩阵的平均值
x&lt; - 矩阵(1:20,ncol = 4)长度(x)#20sum(x)#muthineSQrt(x)#的所有元素的#Square Root
x&lt;矩阵(rnorm(20),ncol = 4)y y&lt;矩阵(rnorm(20),nrow = 4)t(x)#ratixdiag(x)#的rative矩阵对角线x%*%y #矩阵乘法x%x%y#kronecker乘以两个矩阵
矩阵内的元素可以分发并替换为它们在向量中:
x&lt; - 矩阵(1:20,ncol = 4)x [1:2,]#前两个Rowsx [,3:4]#3和第4列[1:2,3:4]#的上索组合[1,]#选择单行返回一个简单的向量(不是矩阵)x [,2]#与列相同
x&lt; - 矩阵(1:20,ncol = 4)x [-1,]#drop first rowx [, - c(2,3)]#drop第二columnx [-1,-c(2,3)] #上一个[-1,c(2,3)]#删除行与ColumnSX [, - C(1:3)]#剩余的选择 - 返回载体时
x&lt;矩阵(1:20,ncol = 4)x [c(true,false,true,false,false),]#选择1st和3rd Rowsx [,c(true,false,true,false)]#选择1st和3nd columnsx [c(true,false,true,false,false),c(true,false)]#组合(带回收)x [,c(true,false,false,false)]#返回向量#更实用的explatex [reonmeans(x)&gt; 10,]#所有行为均高于10
矩阵的行和列也可以具有可用于选择的自己的名称:
X&lt; - 矩阵(1:20,ncol = 4)rownames(x)&lt; - paste0(&#34; r&#34; 1:5)colnames(x)&lt; - paste0(&#34; c& #34;,1:4)x [c(&#34; r1&#34;&#34; r2),]#行命名为&#34; r1&#34;和#34; r2&#34; x [,c(&#34; c1&#34;&#34; c3)]#列名称&#34; c1&#34;和&#34; c3&#34; x [c(&#34; r1&#34;&#34; r2&#34;),c(&#34; c1&#34;,&#34; c3)] #上面的组合[,&#34; c4&#34;]#返回矢量
x&lt; - 矩阵(1:20,ncol = 4)i&lt; - rbind(c(1,2),行1列2 c(2,2)中的#元素,行2列中的#元素2 c( 4,1)第4列中的#元素1)x [i]#在所有指定位置中选择元素
X&lt; - 矩阵(1:20,ncol = 4)rownames(x)&lt; - paste0(&#34; r&#34; 1:5)colnames(x)&lt; - paste0(&#34; c& #34;,1:4)I&lt; - rbind(c(&#34; r1&#34;,&#34; c2&#34;),c(&#34; r2&#34;和#34; C2&#34;),C(&#34; r4&#34;,&#34; c1&#34;))x [i]#与之前相同
矩阵内的元素可以使用上面的所有子集示例轮廓替换。但是要节省时间和空间,因此不会进一步说明这些。
R中的Dataframe在列表中实现为类,其中包含相同长度的列表中的每个元素的限制.such实现允许构造表,其中每个列表元素被解释为单独的列。结果矩阵,data.frame类可以包含不同类型的列。
l&lt; list(id = 1:5,name = c(&#34; a&#34;和#34; b&#34;,&#34; c&#34;,&#34; d&#34 ;,&#34; e&#34;),state = c(true,true,false,true,true)as.data.frame(l)#id name状态#1 1 a true#2 2 b true# 3 3 C FALSE#4 4 D TURE#5 5 E TRUE#与上面相同:DF&lt; - data.frame(ID = 1:5,name = c(&#34; a&#34;和#34; B&#34;,&#34; C&#34;,&#34; D&#34;,&#34; e&#34;),state = c(true,true,false,true,true))
df&lt; - data.frame(id = 1:2,name = c(&#34; albert&#34;,&#34; bob&#34;))df $对象&lt; - list(c(&#34 ; key&#34;,&#34; pin&#34;),c(&#34;球&#34;))#id name对象#1 1 albert key,pin#2 2 2 bob ball
df&lt; - data.frame(id = 1:3,name = c(&#34; albert&#34;&#34; bob&#34;,&#34; cindy&#34;))df [1] #first list元素(第一列)df [1:2]#前两个列表元素(第一和第二列)df [-1]#删除第一个列表元素(第一列)df [[2]] [2:3] #第二和第三矢量元素来自第二个Columndf $ ID#列表元素(列)由NamedF $名称[1:2]#前两个矢量元素&#34;姓名&#34;柱子
等效运算符可用于替换。提供了一些更实际的例子:
df&lt; - data.frame(id = 1:3,name = c(&#34; albert&#34;&#34; bob&#34;,&#34; cindy&#34;))df $ name [ DF $ ID ==&#34; 2&#34;]&lt; - &#34; bobby&#34; df $姓氏&lt; - c(&#34; thompson&#34; na,&#34;弗里德曼&# 34;)df $姓氏[df $ name ==&#34; bobby&#34;]&lt; - &#34;史密斯&#34;
由于数据帧被排列为矩阵,因此它还允许矩阵子集操作,其具有用于替换的等效表单:
df&lt; - data.frame(id = 1:3,名称= c(&#34; albert&#34;&#34; bob&#34;,&#34; cindy&#34;))df [,1 ]#First列(如矩阵,返回一个简单的向量)DF [1,]#数据帧的第一行(返回数据帧)df [df $ id == 2,]#id = 2df的所有条目[DF $ ID%IN%2:3,]#IDS 2和3的所有条目
就像矩阵一样,数据帧可以具有行名称,默认情况下通常提供列名称。这些名称可用于在矩阵样式中将行和列子集中为:
df&lt; - data.frame(id = 1:3,name = c(&#34; albert&#34;&#34; bob&#34;,&#34; cindy&#34;))rownames(df) &lt; c(&#34; a&#34; b&#34; b&#34;,&#34; c&#34;)#id name#a 1 albert#b 2 bob#c 3 cindydf [c( &#34; a&#34;,&#34; b&#34;),]#行命名为&#34; a&#34;和#34; B&#34; DF [,&#34;名称&#34;]#列名为&#34;姓名&#34; df [c(&#34; a&#34;&#34; b& #34;),&#34;姓名&#34;]#两者的组合
df&lt; - data.frame(id = 1:3,名称= c(&#34; albert&#34;&#34; bob&#34;,&#34; cindy&#34;))I&lt; - rbind(c(1,2),#第1行,第2列C(3,1)#3rd行,第1列)df [i]
替换整个条目(一行)是一个经常需要的过程。这些条目是数据帧的子集,它们是数据帧本身,需要用等效数据帧(或列表)替换。替换必须使用等元素名称:
df&lt; - data.frame(ID = 1:3,名称= C(&#34; albert&#34;&#34;鲍勃&#34;,&#34; cindy&#34;))df [df $ ID == 2,]&lt;列表(ID = 2,名称=&#34; Bruce&#34;)#deD = 2df [df $ id == 2,]&lt; - data.frame(ID = 2,名称=&#34;布鲁斯&#34;)#######Albert#2 2 Bruce#3 3 3 Cindy