QUIC能否与TCP的计算效率相匹敌?
我们已经分享了很多关于我们有多喜欢Quic(以及为什么我们要构建我们自己的称为Quicly的实现)。它承诺减少延迟、提高吞吐量、恢复客户端移动性,并提高隐私和安全性。令人兴奋的是,IETF的Quic工作组现在正准备完成Quic的第一个版本,并为在互联网上部署做好准备。虽然许多构建和计划使用它的人员和团队都渴望看到广泛的部署,但有一个问题一直令人担忧……。
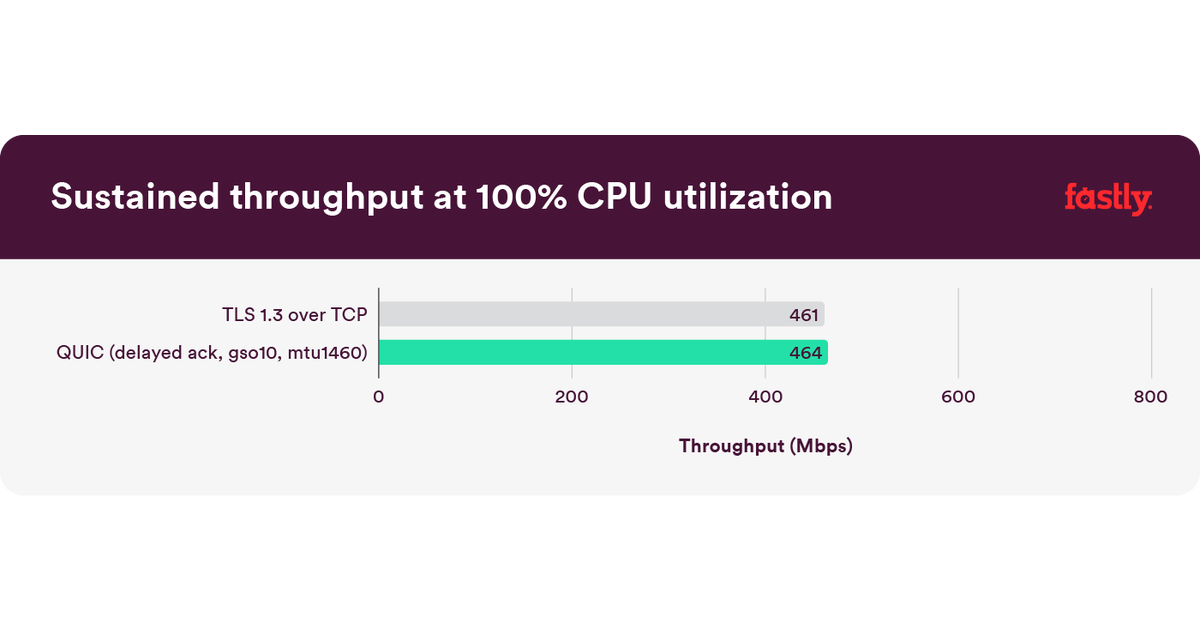
我们运行测试试图找到一些答案,这里是高级答案:是的,Quic的计算效率可以和TCP一样高!
在香槟的瓶子出来之前,我们将承认一个很快就会变得显而易见的事情:我们有一个简单的设置和基准,我们需要用更现实和更具代表性的硬件和流量场景进行更多的测试。重要的是,我们没有为TCP或QuIC启用任何硬件卸载。我们的目标是使用一个带有合成流量的简单场景来消除一些更明显的计算瓶颈,并深入了解如何降低Quic的成本。
也就是说,我们惊讶地发现,即使在我们的简单场景中,Quic也做得和TCP一样好。
你可以认为这篇文章中的练习相当于让我们的汽车在赛道上与一辆法拉利(Ferrari)进行良好的比赛。赛道是一个高度人工的环境,在上面驾驶我们的车的体验并不能代表你每天的体验(除非你是一名赛车手)。然而,解决在那条赛道上很好地比赛的问题有助于我们发现瓶颈。这里重要的和可转让的东西是我们将采取的措施,以消除.。
很长一段时间以来,TCP一直是Web的主力,多年来,人们在优化其实现方面付出了大量努力,以使其在计算上更有效率。然而,Quic仍然是一个新兴的协议;它还没有被广泛部署和调整,以提高计算效率。与古老的TCP相比,这样的新协议会有什么不同呢?重要的是,在不久的将来,Quic能像TCP一样高效吗?
确认处理:典型TCP连接中的很大一部分数据包仅携带确认。TCP确认在内核中处理,发送方和接收方都是如此。Quic在用户空间执行这些操作,从而产生更多跨越用户内核边界的数据副本和更多上下文切换。此外,TCP确认采用明文,而Quic确认是加密的,这增加了以Quic发送和接收确认的成本。
每包发送器开销:内核知道TCP连接,并且可以记住和重用连接中发送的所有包预计保持不变的状态。例如,内核通常只需要在连接开始时查找目的地址的路由或应用一次防火墙规则。由于内核没有Quic连接的连接状态,因此这些内核操作将在每个传出的Quic数据包上执行。
由于Quic在用户空间中运行,因此使用Quic比使用TCP的成本更高。这是因为Quic发送或接收的每个数据包都跨越了用户内核边界,这称为上下文切换。
为了开始回答我们前面提出的问题,我们开始做一个简单的基准测试。我们使用Quicly作为Quic服务器和Quic客户端。Quic数据包总是使用TLS1.3进行加密,并且出于此目的,Quicly使用了H2O的TLS库picotls。我们的参考TCP设置将使用使用原生Linux TCP的picotl,以最小化参考TCP设置和Quic设置之间的差异。
计算效率可以用以下两种方法之一来测量:通过测量使网络饱和所需的计算资源量,或者通过测量所有可用计算能力可持续的吞吐量。使网络饱和会因数据包丢失以及随后的丢失恢复和拥塞控制器操作而引入易变性。虽然在测量性能时包括这些内容很重要,但我们希望避免这种可变性,因此选择了.。
发送者的计算效率很重要,还有两个原因。首先,在传输协议中,发送者往往首当其冲地承担计算成本。这是因为发送器负责大多数计算昂贵的传输功能,例如运行定时器以检测丢弃在网络中的分组并重新发送它们,监视网络的往返时间,以及运行带宽估计器以使其不会拥塞网络。第二,服务器是.。
在深入研究结果之前,简单介绍一下我们的实验设置。我们的发送者在Intel Core m3-6Y30上使用Ubuntu19.10(Linux内核版本5.3.0),限制为单核和单线程。发件人已三次连接到本地网络