NoSQL(与RDBMS)敏捷性的神话
。使用NoSQL和半结构化数据库有很好的理由。而且也有很多错误和迷思。如果人们因为错误的原因从RDBMS迁移到NoSQL,他们会有一个糟糕的体验,这最终是当之无愧的NoSQL声誉。这些神话被一些没有学习SQL和关系数据库的数据库新手打破了。而且,他们并没有学习数据建模的基础知识,也没有学习SQL语言处理数据集的能力,而是认为他们发明了下一代持久性…。当他们真正回到RDBMS发明之前的东西时:分层的半结构化数据模型。现在遇到了关系数据库40年前解决的同样问题。这篇博文是关于其中一个神话的。
这句话我已经读过和听过太多次了。像这样的想法:RDBMS和SQL不能灵活地跟随数据领域的发展。或者:NoSQL数据存储,因为它们在数据结构上很松散,所以更容易添加新属性。错误但不幸的是,向SQL表添加新列是一项代价高昂的操作,因为所有行都必须更新。这里有一些例子(随便举几个例子来说明这个想法是如何在聪明的专家和良好的声誉论坛上广泛传播的):
Twitter上的一条评论是:“向JSON添加KVS比更改RDBMS表(尤其是大表)添加新列要容易得多。”
是的,但他们更多指的是能够将KV添加到JSON中,这比更改RDBMS表(尤其是大型表)来添加新列要容易得多。如果您选择创建一个新的数据库并将数据移动到它上面,那将会以不同的方式影响您的体验。
关于StackOverflow的一个问题:“与MySQL这样的关系型数据库相比,‘列添加’(模式修改)是NoSQLMongoDB数据库的主要优势吗?”https://stackoverflow.com/questions/17117294/is-column-adding-schema-modification-a-key-advantage-of-a-nosql-mongodb-da/17118853.。他们说这次行动要花几个月的时间!
Medium上的一篇文章:“在RDBMS中添加新列的迁移不需要DynamoDB的这种扫描和更新风格的迁移”https://medium.com/serverless-transformation/how-to-remain-agile-with-dynamodb-eca44ff9817.。
这些只是一些例子。人们都听到了。人们会重复它。人们相信这一点。而且他们不做测试。而且他们不会学习。它们不会与文档交叉核对。他们不使用当前数据库进行测试。当这件事这么容易做到的时候。
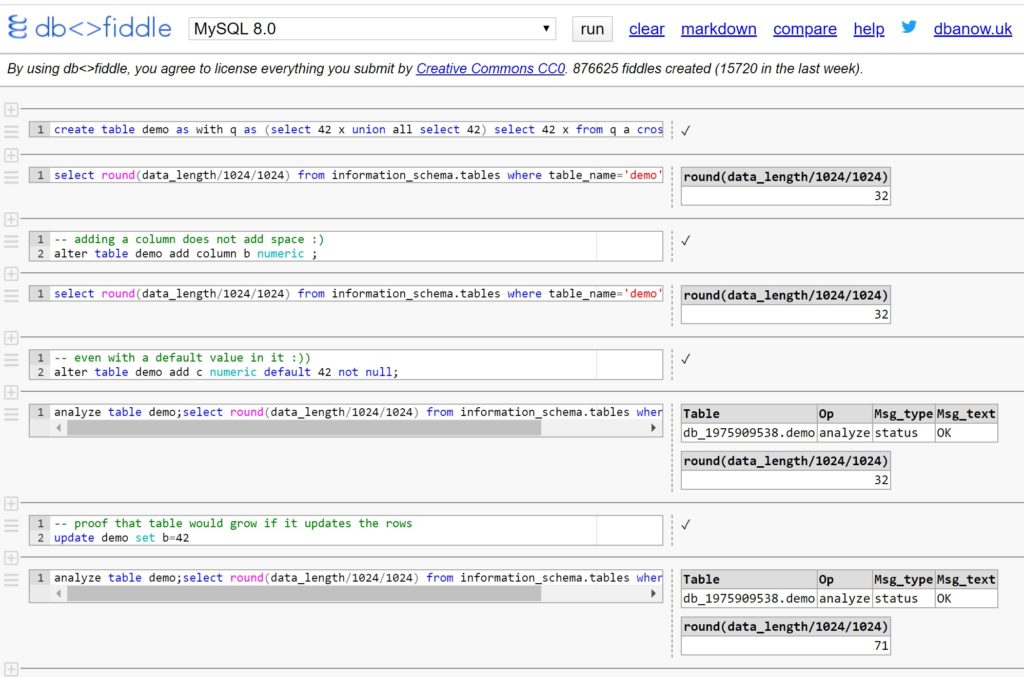
实际上,在主要的现代关系数据库中,添加列是一种快速操作。我会创建一张桌子。检查一下尺寸。然后在没有默认值的情况下添加一个可以为空的列。检查一下尺寸。然后添加具有默认值的列。再检查一下尺寸。大小保持不变意味着不更新任何行。当然,您可以进一步测试:查看大型表上运行的时间、读取的数量以及生成的重做/WAL,…。您将在当前主要的RDBMS中看不到任何内容。然后实际更新所有行并进行比较。在那里,您将看到大小、时间、读取和写入,并了解使用显式UPDATE时,行实际上是更新的。但不是用DDL来添加一列。
@PostgreSQL在添加列方面也非常聪明:不接触元组。即使向现有元组添加值,大小也不会改变:pic.twitter.com/FT2H7KuLIp。
您的甲骨文体验是什么时候?添加一个可为空的列一直是(至少从24年前的Oracle7开始)。与12c(7年前)以来的NOT NULL列(默认)相同:pic.twitter.com/pmoPFX9Q7o。
是的,我甚至在Oracle7中进行了测试,当时,添加一个带有默认值的非空列实际上扫描了表。有了视图,解决方法很容易。添加一个可为空的列(这就是您在NoSQL中所做的)已经是一项快速的操作,那是40年前的事了!
看起来我使用的表对于dbfiddle来说太大了,但是我已经在我的笔记本电脑上运行了同样的表:
1>;Set Statistics time on;2>;go 1>;create table demo(X Numeric);2>;go SQL Server解析和编译时间:CPU时间=0毫秒,运行时间=0毫秒。SQL Server执行时间:CPU时间=2毫秒,运行时间=2毫秒。1>;,Q为(选择42 x联合全部选择42)2>;插入到演示3中>;s Join Qj交叉联接Qk交叉联接Ql交叉联接Qm交叉联接Qn交叉联接Qo交叉联接Qp交叉联接Qr交叉联接Qs交叉联接Qt交叉联接Qu;4>;Go SQL Server解析和编译时间:CPU时间=11ms,运行时间=12ms。SQL Server执行时间:CPU时间=2374毫秒,运行时间=2148毫秒。(1048576行受影响)1>;ALTER TABLE DEMO ADD B NUMBERIC;2>;执行SQL Server解析和编译时间:CPU时间=0毫秒,运行时间=0毫秒。SQL Server执行时间:CPU时间=0毫秒,运行时间=3毫秒。1>;ALTER TABLE DEMO ADD C NUMBERIC DEFAULT 42 NOT NULL;2&gT;GO SQL Server解析和编译时间:CPU时间=0毫秒,运行时间=0毫秒。SQL Server执行时间:CPU时间=1毫秒,运行时间=2毫秒。2>;执行SQL Server解析和编译时间:CPU时间=0毫秒,运行时间=0毫秒。x b c-42 null 42(3行受影响)SQL Server执行时间:CPU时间=0毫秒,运行时间=0毫秒。3>;执行SQL Server解析和编译时间:CPU时间=0毫秒,运行时间=0毫秒。SQL Server执行时间:CPU时间=3768毫秒,运行时间=3826毫秒。(1048576行受影响)。
2毫秒,用于添加在所有百万行上都可见的具有值的列(并且可能更多)。
在分布式数据库中,必须在所有节点中更新元数据,但无论表大小如何,这仍以毫秒为单位:
我没有使用非空值和默认值显示测试,因为我遇到了一个问题(添加列速度很快,但是没有选择默认值)。我没有最新版本(YuaByte DB是开源的,正在积极开发中),这个问题可能会被修复。
Tibero是一个与Oracle具有非常高兼容性的数据库。我运行过相同的SQL。但此版本6似乎与Oracle 11兼容,在Oracle 11中,使用DEFAULT添加非空列必须更新所有行:
--CTAS CTE交叉连接是我发现创建一百万行CREATE TABLE DEMO的最好方法(选择42 x Union ALL SELECT 42)从Q中选择42 x a交叉连接Q b交叉连接Q c交叉连接Q d交叉连接Q e交叉连接Q f交叉连接Q g交叉连接Q h交叉连接Q i交叉连接Q j交叉连接Q k交叉连接Q l交叉连接Q m交叉连接Q n交叉连接Q o交叉连接Q p交叉连接Q r交叉连接Q s交叉。--检查添加一列的时间ALTER TABLE DEMO ADD ADD b NUMBERIC;--检查具有为所有现有行设置的值的列的时间ALTER TABLE DEMO ADD C NUMERIC DEFAULT 42 NOT NULL;--检查所有行是否显示此值SELECT*FROM DORDER BY x FETCH前3行;--与真正更新所有行更新演示集c=42的时间进行比较;
请不要犹豫评论这篇博客文章或下面的推文和你的结果:
如果我再一次听说NoSQL半结构化数据存储比RDBMS更敏捷,我会写一篇关于SQL add column和Codd规则#9的博客文章。
这个神话来自一些数据库的旧版本,它们没有实现ALTER TABLE。以最佳方式添加。而NoSQL的发明者可能只知道MySQL,它在这一领域起步较晚。谁说MySQL EVERVATION因被甲骨文收购而蒙受损失?它们缩小了与其他数据库的差距,比如本专栏增加了优化。
如果您继续使用这些过时的知识,您可能会认为使用半结构化集合的NoSQL更敏捷,对吗?是的,当然,您可以在插入新项目时添加新属性。它是零成本的,而且你不需要向任何人申报。但是,对于我在所有这些SQL数据库中测试的第二种情况,您也希望为现有行定义一个值,那该怎么办呢?正如我们已经看到的,SQL通过DEFAULT子句允许这样做。在NoSQL中,您必须扫描和更新所有项目。或者您需要在应用程序中实现一些逻辑,比如“If null则value”。这根本不是敏捷的:作为新功能的副作用,您需要更改所有数据或所有代码。
关系数据库使用逻辑视图封装物理存储。除此之外,当现有应用程序代码演变时,此逻辑视图可保护现有应用程序代码。这条E.F代码规则编号9:逻辑数据独立性。您可以向结构传递声明性更改,而无需修改任何过程代码或存储的数据。现在,谁是敏捷的呢?
它怎麽工作?。RDBMS字典保存有关行结构的信息,这不仅仅是简单的列名和数据类型。此处定义了默认值,这就是添加列是立即列的原因。这只是元数据的更新。它不涉及任何现有数据:性能。它向应用程序展示了一个虚拟视图:敏捷性。使用Oracle,您甚至可以将这些视图版本化并无中断地将它们交付给应用程序。这称为基于版本的重定义。
在RDBMS字典中还有其他聪明的东西。例如,当我添加一个具有NOT NULL属性的列时,这个断言是可以保证的。我不需要任何代码来检查值是否已设置。约束也是如此:中央字典中的一个声明使所有代码都更安全、更简单,因为断言不需要额外的测试就能得到保证。无需检查数据质量,因为它是由设计强制执行的。如果没有它,您需要在代码中添加多少理智假设,以确保错误数据不会破坏周围的一切?我们已经看到添加一个列,但是想一想更简单的事情。在IT领域,命名是最重要的。允许自己认识到自己犯了一个错误,或者某些业务概念发生了变化,并将列的名称修改为更有意义的名称。这很容易做到,即使是为了保持与以前代码的兼容性。更改大型JSON项集合中的属性名并不那么容易。
让我引用CERN在1982年决定将Oracle用于LEP(大型强子对撞机的祖先)的原因:Oracle是LEP的数据库管理系统:“关系系统将复杂的数据结构转换为易于可视化的简单二维表。这些系统是为预先计划困难的应用而设计的(…)。“。
不需要预先计划…。这不就是20世纪词语对敏捷的定义吗?
另一本澄清某些谬论的好读物:E.F.Codd著的“关系数据库:生产力的实用基础”关系数据库解决的一些问题是“程序员对数据的(逻辑)视图和(存储中的)数据的(物理)表示之间缺乏区别”,“数据描述中的后续更改”迫使代码更改,以及由于缺乏集合处理,“程序员被迫按照迭代循环进行思考和编码”。谁说SQL和连接很慢?您的迭代循环是否比散列连接、嵌套循环和排序合并连接更智能?
我不是说NoSQL是好是坏,是好是坏。只有当决定是基于神话而不是事实时,这才是糟糕的。如果您想要数据域结构上的敏捷性,请保持关系。如果您希望允许任何未来的查询模式,请保持关系。但是,也有一些用例可以放在关系数据库中,但也可能受益于另一个在键值查找中具有最佳性能的引擎。我看到过充满会话状态的表,其中有一个主键(用户或会话ID)和一个包含一些数据的原始列,这些数据只对一个应用程序模块(登录服务)有意义,没有持久的目的。如果您处理物理模型(您不希望在具有许多并发登录的上下文中聚集这些行),那么它们在SQL表中是可以接受的。但是键值可能更合适。我们仍然看到具有LONG数据类型的Oracle表。如果您喜欢这样,您可能需要一个键值NoSQL。数据库可以存储文档,但这是奢侈品。他们受益于一致的备份和高可用性,但代价是运行一个非常大且不断增长的数据库。时间序列或图表不容易存储在关系表中。像AWS DynamoDB这样的NoSQL数据库对于这些特定的使用案例非常有效。但这是从设计中知道所有访问模式的时候。如果您了解您的数据结构,并且无法预测所有查询,那么关系数据库系统(这意味着不仅仅是一个简单的数据存储)和SQL(按集合操作数据的第四代声明性语言)仍然是敏捷性的最佳选择。