使用Kafka实现弹性和灾难恢复
高可用性、弹性和可扩展性已经成为构建面向用户的应用程序的标准。云计算一直是促成这一点的一个因素。
以前,拥有多个数据中心是一项主要的前期资本投资-无论是在技术方面还是在硬件方面。今天,多亏了云计算,制定灾难恢复计划需要的工作量更少,而且不需要前期投资。因此,许多面向消费者的应用程序现在都是以地理上分散的方式设置的。在发生重大故障的情况下,用户不受影响,并且减少了全球用户的延迟。
Motors垂直团队是易趣分类广告集团(ECG)的一部分。作为一家全球性组织,我们在地理上分散的多地区(多数据中心)设置中运行我们的软件。我们会时不时地进行故障转移操作,关闭整个区域,以验证系统对停机的响应情况。我们还具有自动故障转移功能,因此如果服务在一个区域出现问题,我们可以将所有流量转移到另一个区域。我们使用的许多技术使我们能够非常高效、轻松地在多区域设置中运行应用程序,而一小部分技术使我们很难做到这一点。
我们基础架构中最关键的组件之一是Apache Kafka®。-但是,尽管它在我们的架构中很重要,但运行多群集主动/主动的Kafka设置并不是那么容易。
虽然最近发布的Kafka 2.4版本大大提升了对多个Kafka集群与MirrorMaker 2.0的支持,但还是可能会让你头疼不已,这取决于你的使用案例。
在本文中,我将概述一个需要有序事件的技术场景,强调几个挑战,并提供运行多区域Kafka设置的可能解决方案。
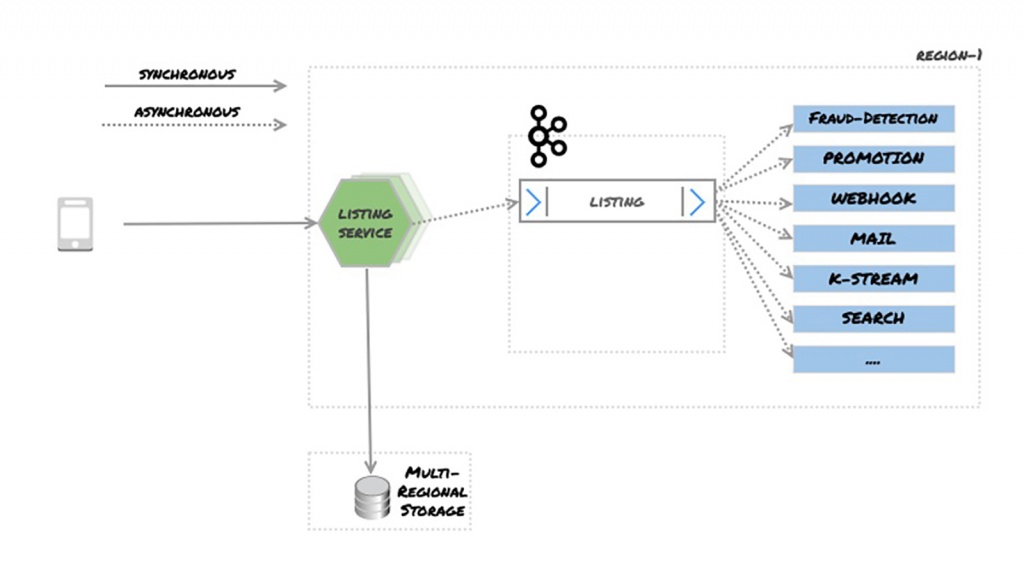
在Motors Vertical(Move),我们处理产品列表。列表(或“广告”)是一种非个人的促销或销售产品的信息,由想要销售单一商品的个人或以更高数量销售的专业组织发布。列表是大多数分类广告的核心数据结构,我们系统中的所有内容都依赖于它们。
根据列表是否已创建、更新、删除等,该列表会变得更长。因此,列表所处的每个状态都可能触发不同的操作。
列表服务有其数据存储,该数据存储存储列表并充当该域的真实源。一旦客户发布了列表,它就会存储在NoSQL数据存储中,并发布给Kafka经纪人。有一组客户端使用这些消息并采取适当的操作。
如果我们在单个区域运行我们的系统,上面的设置就可以了。如果我们在多个地区运行我们的软件,我们可能会将我们在一个地区运行的所有软件复制到另一个地区,所以如果地区1出现故障,地区2可能会接管。
这样的设置可以让iOS、Android、Web和API客户端连接到多个地域。根据负载均衡规则将流量路由到不同区域。为简单起见,我们假设这里使用的是最小轮询和负载均衡方法。因此,同一客户端的请求将由多个区域处理。
在Region-1(区域1)中接收的任何事件都在Region-1(区域-1)中处理。这种方法的问题在于,有些服务需要完整的数据集才能正常运行。例如,要使搜索API提供正确的结果,它必须为所有清单编制索引。搜索索引不是共享的,因此每个区域都必须拥有自己的搜索索引。所有数据都必须可用,才能在两个地区提供相同的结果。
因为我们依赖于所有的Kafka流,所以对于一些Join操作,我们需要整个数据集。否则,联接将不会发生,并且生成的数据将具有误导性。
1.取消至少需要从所在区域消费一次数据的服务。
1.确保事件发生在由本地服务中心处理的区域内(由上面的设计完成)。
在我们继续之前,值得注意的是,Kafka集群为您提供了以下保证:
生产者发送到特定主题分区的消息将按照发送的顺序附加。也就是说,如果记录M1与记录M2由同一生产者发送,并且M1首先被发送,则M1将具有比M2更小的偏移量,并且在日志中出现得更早。(见“卡夫卡担保”)。
值得强调的是,此保证是针对单个群集的,而不是针对多群集设置的。记住这一点很重要,稍后我们将回到这一点,…。
因此,考虑到我们的使用案例和技术挑战,我们想要回答的问题是:
当事件排序是必备功能时,如何在多区域设置中运行多集群Kafka?
虽然运行主动/主动的Kafka集群是可能的,但对于有序的事件来说,这是非常有问题的。在内部,我们在Move这里有我们自己的定制Kafka-Mirror-Service,这是因为MirrorMaker 1.0不能满足我们的需求而产生的。但在本文中,我将重点介绍MirrorMaker 2.0的功能。
使用MirrorMaker 2.0,可以在集群之间镜像主题。MirrorMaker自己处理主题创建和同步,这非常非常方便。例如,如果“Region-1”和“Region-2”中存在一个名为Listing的主题,MirrorMaker会在这两个Kafka集群上创建新主题,并以定义的名称为前缀:
现在,来自Region-1的所有列出的项目都将镜像到Region-2,反之亦然。这解决了访问完整数据集的问题,因为需要访问完整数据集的服务现在可以在主题名称中使用正则表达式来消费多个主题,如返回整个数据集的.*\.listings。
这看起来像是一个解决方案。我们可以满足这两组服务,包括1)至少消费本地区域内的事件一次,以及2)跨区域消费所有数据。
我们确实有一些事件顺序无关紧要的用例,这个解决方案可以很好地解决这一问题。但是清单场景要求以正确的顺序使用事件。此外,我们对列表主题使用主题压缩,所以这个解决方案变得相当有问题。
例如,假设列表客户端正在启动对列表的更新,其中每次更新都与前一次不同,并且包含比以前更多的数据,例如:
#1代表列表ID,我们将使用它作为Kafka消息键,而有效负载是事件的更新版本。事件由不同的区域处理:v1、v3在区域-1中结束,而v2和v4在区域-2中结束。
图7-在不同地区使用相同密钥的消息的不同版本。
我们确实使用日志压缩,因此假设主题变得足够脏,可以在一段时间后进行日志压缩,那么一旦发生日志压缩,系统状态将如下所示:
图8-日志压缩后,不同区域中具有相同键的消息的不同版本。
现在Kafka客户端将读取这些主题中的数据,但是Kafka客户端无法保证不同主题之间的排序。
因此,虽然这种方法很棒,但它解决了无序事件的问题,而不是有序事件。
当您开始使用逻辑删除时,此设置会出现问题。让我们假设地域2的用户获得了删除请求事件,并且服务请求被路由到本地的Kafka集群。复制事件时,我们在两个区域仍有旧版本(甚至不是最新版本)的副本,如下所示:
图9-Tombstone事件之后,不同区域中具有相同密钥的消息的不同版本。
虽然MirrorMaker 2.0完成了繁重的任务,但它不能解决此场景中的有序事件问题。
这种设置相对简单--事件的顺序很重要的主题被写入单个Kafka集群,而不管它们是在哪个地区产生的。数据将通过MirrorMaker 2.0复制到不同地区的其他群集。它将如下所示:
不同地区的服务将通过.*\.Listings消费多个主题,但由于生产者将只连接到一个地区,因此数据在单一地区排序。如果一个Kafka集群出现故障,这很方便-生产者只需要更换代理,消费者不需要做任何事情。
这会强制对两个区域中的所有事件进行排序,因为事件被写入单个Kafka集群,并且只复制数据。现在所有事件都已排序,但我们还有另外两个问题需要解决:
1、数据丢失,一些应用程序现在不必要地消费和处理数据。例如,对于WebHook,我们至少消费同一事件两次。至少一次很棒,但至少两次会带来财务后果:我们依赖第三方服务和按呼叫付费的模式,而我们刚刚将这些服务的成本翻了一番。因此,当我们解决排序问题时,我们现在被迫至少处理两次事件。
2.注意:在集群故障的情况下,存在两种不同场景下的潜在数据丢失。首先,发布消息的应用程序将无法与群集通信,这可能会导致数据丢失。其次,MirrorMaker 2.0数据复制是一个异步过程,因此当群集出现故障时,不能保证在群集出现故障之前所有数据都已复制。这让我们得出结论,从失败中恢复并不像看起来那么容易。
在此场景中,延迟也是一个大问题。群集之间的数据复制是异步的,这意味着当数据写入区域1时,需要一些时间才能将其复制到区域2。
因此,此解决方案会导致一个区域中立即可用的数据可能需要更长时间才能在第二个区域中可用的问题。
这相对容易,解决了一系列问题,但有其他警告。在此解决方案中,生产者和消费者连接到相同的Kafka集群,如下图所示。
在这种情况下,事件被排序,因为它们没有被写入到同一群集中,消费者可以访问完整的数据集,并且它们至少被使用一次。这相当容易。此方法的注意事项如下:
整个Kafka集群不得不在空闲状态下等待,这浪费了资源。它仅在出现故障时使用。区域之间有持续的数据流,以防某一天发生故障。
虽然处于活动状态的Kafka实例在同一地域的应用程序工作正常,但其他应用程序在读写时会受到延迟惩罚。根据区域之间的距离,此问题可能会变大,也可能会变小。
卡夫卡中的每条记录都被分配了一个偏移量编号,用于标识主题分区中的记录。因此,当消费者导入记录时,Kafka会存储一组偏移量,以指示哪些消息已被消费。这很有帮助,因为下次同一消费者试图读取数据时,Kafka只能发送新记录。这就是所谓的消费者群体补偿。但是,即使通过MirrorMaker 2.0复制数据,主题的偏移量也不能保证相同,这意味着两个群集之间的消费者组偏移量可能不同-即使它们包含100%相同的数据。因此,不直接共享偏移。
如果出现故障,所有服务现在都必须连接到Region-2的Kafka集群,问题是因为它们一直在消费Region-1的数据,偏移量是Region-1分配的。因此,服务必须从与实际偏移量相差甚远的偏移量开始读取消息。这意味着某些消息可能会被多次消费。
但是,MirrorMaker 2.0会将使用者组偏移检查点从一个群集发送到另一个群集。MirrorMaker 2.0使用内部检查点主题来存储目标群集的源群集中每个使用者组的偏移量。此外,它使用一个独立的偏移同步主题来存储每个正在复制的主题分区的群集到群集的偏移映射。因此,尽管群集之间的偏移量不同,但MirrorMaker 2.0会跟踪最近的消费者组偏移量。
此过程不是自动化的,因此服务仍必须负责在连接到不同群集时找到正确的偏移量,以防出现故障。MirrorMaker 2.0提供部分数据,因此服务可以在需要时执行此操作。为此,Kafka 2.4.0提供了RemoteClusterUtils,如KIP-382中所述:
实用程序类RemoteClusterUtils将利用上述内部主题来帮助计算可达性、群集间延迟和偏移转换。不可能直接转换任何给定的偏移量,因为并非所有偏移量都会在检查点流中捕获。但对于给定的消费群体,将有可能找到消费者不能寻求()的高水位。这对于群集间消费者迁移、故障转移等非常有用。
您有两个区域。地区-1(或整个地区-1)的一个卡夫卡集群失败。
所有应用程序现在都必须连接到新群集。最有可能的情况是,服务在引导时加载集群配置,因此当配置更改时,您需要重新启动服务。
服务必须具有适当的代码-它们必须知道Region-1群集出现故障,并且它们现在正在连接到Region-2群集,并且必须在RemoteClusterUtils的帮助下查找偏移量,以从新的Kafka群集获得适当的偏移量。
服务应该只需要这样做一次-如果您重新部署服务,它不应该再次执行相同的操作。
此规则适用于您的所有服务,因此它们都需要知道它们正在连接的区域以及在出现故障时将连接到的区域。这是一个有效的场景(假设您的集群不是每天都出现故障),但是如果配置不正确,服务最终可能会重新读取队列开头的所有数据。
我绝对可以看到群集之间同步偏移的用例,所以我相信RemoteClusterUtils对于集成场景和其他挑战将非常有用。但是使用它来处理集群故障需要大量的工作、编码和自动化,而且这样的工作的优点是值得怀疑的。
这是一个相当昂贵的解决方案,是否真的值得这样做还值得商榷,但为了完整起见,我们将在这里概述它。这是解决方案1的扩展方案,其中消息被写入本地群集。每个本地群集都有一项利用所有Kafka流的服务。该服务的工作是对事件进行排序,并将其写入新主题。
在此场景中,每个文档都有一个版本。每次更新时,此版本号都会增加。当文档发布到Kafka时,版本号作为Kafka消息头发送(参见KIP-82)。应用程序可以根据标题值对消息进行排序,并将其写入新主题。最初,消息将按下图所示进行分发:
图13-在不同地区使用相同密钥的消息的不同版本。
在服务处理和订购消息之后,最新版本将被写入一个名为Listing.ordered的主题。
标记要删除的项目的墓碑事件也是版本化的,因此最新的消息将是墓碑。
这乍看起来是个好主意,但来自不同地区的墓碑可能会带来问题。尽管生成的主题会有一段时间的墓碑消息,但最终这些墓碑消息将被删除。
或者,将其作为一种清理方式删除。政策框架而不是契约框架将是一个合理的决定,因为它解决了墓碑信息问题-甚至可能是一个更好的解决方案。
它会带来额外的延迟。在理想情况下,发布者发布数据,消费者使用数据。这是相对较快的。但是,将数据复制+数据处理附加到每条消息的管道会增加延迟。例如,MirrorMaker 2.0必须首先将数据复制到另一个区域(这是可以接受的延迟)。但是,Kafka Stream服务必须以正确的顺序消费和发布数据。Kafka Stream应用程序需要对Kafka Stream的工作原理进行一些微调和深入了解,例如数据存储以及如何最大限度地减少任务故障转移的延迟(参见备用副本)。
在高吞吐量场景下,Kafka Stream需要大量资源才能运行,长期来看可能会比较昂贵。
一个类似的解决方案可以使用消息时间戳和消息键来实现-但是时间是一个非常棘手的概念,所以我不推荐它(参见“现在没有时间”)。
在多区域设置中运行Kafka以跨区域共享数据有多种可能性。然而,其中每一个都有应该承认的后果。使其启动和运行的工程工作、测试、基础设施成本、损失的时间等等。我不会争辩说这种努力是不必要的,但它应该经过深思熟虑。
还可以在单个地区运行单个Kafka集群,并在两个地区之间共享数据。大多数云区域都有三个或更多可用区(AZ)。每个AZ都是隔离和物理隔离的,具有独立的电源和冷却,并通过冗余网络连接。对于某些业务使用情形,这可能是足够高的可用性和可接受的延迟。不过,对于我们的时延敏感型业务来说,多地域架构是更好的选择。
鉴于此,值得一提的是,MirrorMaker 2.0做得不错。但还需要注意的是,复制是一个异步过程,这意味着如果源群集出现故障,仅靠MirrorMaker不能保证在目标群集中成功复制所有数据。
卡夫卡是一款很棒的软件。它具有高性能、良好的抽象性、非常便宜(意味着普通硬件每秒可以执行数百万次读/写操作),并为我们提供了极大的灵活性。卡夫卡的这些特点都是基于简单的设计选择。然而,这些设计选择在多区域主动/主动系统或主动/被动系统设计中并不起到很好的作用,原因非常简单:
区域间存在明显的数据传输延迟。在区域故障中幸存下来的同时实现低延迟和强一致性并不是一个容易解决的挑战。