国子监流行病学模式分析
帝国理工学院的建模人员几天前发布了关闭世界经济的模型的源代码。它不是原始的模型代码,而是被交给志愿者程序员的原始源代码,他们重新编写了它,使其更具可读性。我过去曾对金融模型做过一些模型审查,但如果没有源代码,我将无法对帝国理工学院的模型进行全面审查。现在我们有了源代码(某种程度上),我可以了。
任何这样的模型在用于真正的政策决策之前,都应该经过独立的审查。政策分析充斥着模型,但从来没有人真正检查过它们。展望未来,卫生政策制定者在使用任何模型的结果提出任何后果的建议之前,应该要求并披露对任何模型的独立验证。
通常,模型评审是很长的技术文档,但也会有总结部分。以下是我认为摘要应该是什么样子的。
--在“报告9-非药物干预措施降低冠状病毒死亡率和医疗保健需求的影响”中使用了审查中的模型,以预测未减轻和减轻的预测。英国和美国冠状病毒造成的死亡人数和其他统计数据。在那份报告中,该模型被用来预测,如果没有强制的社会疏远政策,美国将有超过200万人死亡,英国将有超过50万人死亡。然而,该模型估计,如果采取特定的社会疏远政策,死亡人数将显著减少。
在这篇综述中,我们检查了1)模型文档;2)模型实现;3)模型逻辑;4)代码正确性测试的有效性;5)与替代模型的基准比较;以及6)样本预测性能。在使用模型之前,这些类别中的任何一种的任何实质性缺陷都应该得到纠正。不幸的是,这种模式在每一类中都有严重的缺陷。
1.文件:用于冠状病毒估计的模型与其作者在大约15年前的前两篇论文中在以前的学术工作中使用的模型相同:“遏制东南亚新出现的流感大流行的策略”和“减轻流感大流行的策略”,这两篇论文都发表在“自然”杂志上。每篇论文都有记录模型的技术附录。
好的模型文档应该满足两个条件:1)文档应该足够详细,独立的、合格的建模人员应该能够从文档中重构结果,而不需要看到代码;2)代码应该实现文档中的内容。
文档在两个方面都失败了。虽然有足够的细节来理解模型是如何工作的,但我们不能重建报告的数字,因为没有提供该模型用于冠状病毒大流行的新用途的文件。此外,我们没有得到原始源代码,并且提供的源代码没有用于生成报告估计的原始输入数据。因此,我们无法验证代码是否如文档所说的那样做,或者它是否产生了报告9:非药物干预(NPI)降低冠状病毒死亡率和医疗需求的影响中报告的估计,即在没有政府强制社会距离的情况下,美国超过200万人和英国超过50万人将死亡。
不幸的是,我们没有原始源代码。我们有一些由帝国理工学院建模人员提供的代码,显然是用c编写的单个文件,然后由志愿者重新分解成更具可读性的代码,函数和文件被拆分,也是用c编写的。
由于我们没有原始源代码,我们不能很明显地对其进行评估。但是,由于所提供的是原始源代码的清理版本,我们可以在合理的假设下对其进行评估,即原始源代码可能会有更多问题。
虽然新版本中有许多项目可能会受到批评,但在本摘要中,我们强调广泛使用全局变量,特别是c语言结构来建模数据类型。全局变量和结构的使用使得程序逻辑很难遵循,并且它没有将数据与一般的程序算法隔离开来。这两种做法都会导致错误。难以遵循的逻辑会产生错误,即使是非常了解程序的程序员也会犯错误。而且,使用非常大量的全局可访问变量为数据在不经意间更改提供了机会。
将类放入C++中是为了隐藏数据,并将类与操作类的函数相关联,这样数据结构就可以像对象一样工作。虽然帝国理工学院的程序员使用的是C++编译器,但他们没有利用它的任何面向对象的好处。至少,应该删除全局变量,并将结构更改为类,以便将程序使用和修改的大量数据与通用程序隔开,只允许特权函数修改这些数据。仅此微小的更改就会降低数据因程序逻辑中的错误而意外更改的可能性。一般来说,对于这种复杂的程序,应该大力考虑面向对象的编程技术。
回到代码应该实现文档所说的内容这一点,例如,我们找不到重写的代码实现文档中的声明,即传染性参数被建模为伽马分布。它可能就在那里,但是代码中缺少注释和代码逻辑的一般错综复杂的性质使得这种说法很难验证。但在编写良好的代码中,应该很容易验证。
随机数生成器的代码非常旧。它似乎是在20世纪80年代编写的,并且是从PASCAL或FORTRAN机器翻译过来的。现在有更好的随机数生成器可用。更新这部分代码将非常容易。
结论:在使用模型之前应该重写代码,并且应该验证代码实现了模型文档中的内容。
该模型基本上是对易感、传染病、恢复期(SIR)模型的离散时间微观模拟。标准SIR通常是在总体水平上制定的,而没有区分个人传染性、家庭人口结构、个人之间的距离等细节。在微观水平上制定模型的好处是可以直接进行社会距离实验。缺点是必须指定大量参数。不管怎样,如果模型的目标是量化社会疏远政策的效果,微观模拟方法似乎是实现SIR类型模型的合理方式。
然而,无论是在微观层面还是宏观层面,这些模型的致命问题是它们假设代理人是僵尸。在僵尸电影中,无论有多少僵尸被受害者击中头部,僵尸总是不断出现。他们似乎没有注意到。同样,这些SIR模型中的特工,帝国理工学院的模型也不例外,总是以完全相同的方式行事,即使他们周围有大量的人在死去。然而,这一假设与流行病历史(包括当前的大流行)相矛盾,历史表明,人们为了在流行病中保护自己,会显著改变自己的行为。
这些模型中的僵尸假设导致了一个错误的政策困境-要么我们接受数百万人的死亡,要么我们实施严格的政府限制,这可能会将预测的死亡人数减少75%。但这是一个无效的比较。社会疏远政策被比作是一种不可能也不会发生的僵尸替代方案。当人们观察到流行病时,他们会自己与社会保持距离。要真正有用,该模型应该比较如果人们内生的社会距离会发生什么,与如果政府施加额外限制会发生什么。由于它无法做到这一点,该模型无法帮助量化实际的权衡。
我们所依赖的任何产品质量代码都应该始终具有一系列测试,以验证代码在不同的初始条件下是否提供了预期的结果。这些测试对于检查代码是否正确实现以及对代码的更改是否没有引入新错误非常重要。代码似乎没有这样的测试。
尽管测试如此复杂的模型可能看起来很困难,但良好的测试对于获得对模型的信心是必要的。
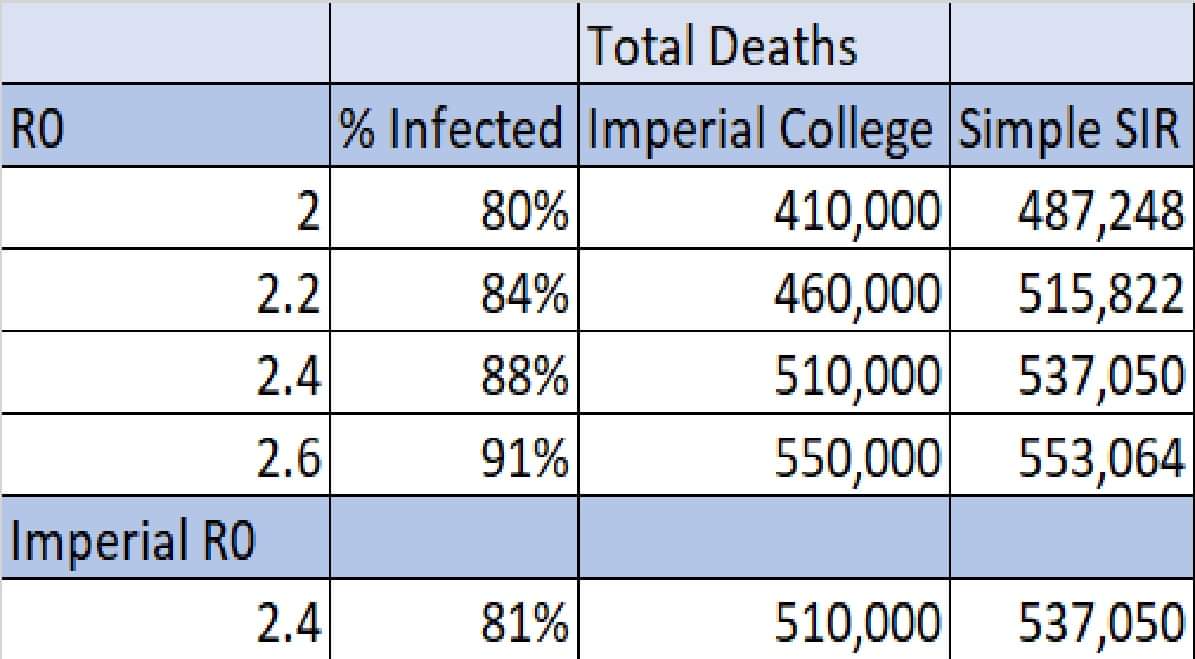
在判断输出模型时,重要的是实现替代基准模型。似乎还没有开发出这样的模型。然而,作为这项审查的一部分,我们实施了一个简单的基准来验证在完全不减轻的情况下由模型产生的死亡数字是否合理。
帝国理工学院模型也坚持这些SIR型模型中最重要的假设,即感染的概率服从指数分布。通过从微观仿真中抽象出来,我们使用了一个简单的宏观SIR基准模型,在该模型中,指数分布假设暗示了R0与最终感染百分比之间的关系。使用该模型0.9%的死亡率,我们可以使用该关系来近似英国基准模型中的总死亡人数,并将其与报告9:非药物干预(NPIs)降低冠状病毒死亡率和医疗保健需求的影响表4中报告的模型估计进行比较。我们不应期望简单的宏观基准给出与微观版本相同的答案,但它们应该具有相同的数量级。
从下表可以看出,帝国理工学院模型对英国在不同R0值的情况下死亡人数的估计是可信的,考虑到基准结果,这应该会让我们感到安慰,即使代码中有错误,该模型也可能给出合理的估计,至少对于不减轻的情况是这样。
任何一个模型的酸性检验都是看它是否能成功地预测出样本。目前还没有证据表明该模型具有预测能力。然而,我们确实有一个自然的实验可以依靠。
在针对冠状病毒的干预策略及其对瑞典医疗保健能力的估计影响中,该研究的作者重新实施了帝国理工学院的模型,并将其应用于瑞典。对模型文档和模型源代码(也是用c语言和GitHub编写的)的检查表明,这是同一个模型。瑞典版的模型清楚地预测了,如果瑞典遵循其宣布的自由放任的社会疏远政策,瑞典将发生的死亡人数,以及如果遵循与美国和英国类似的各种其他政策,这些死亡人数将减少多少。在论文图4的图表A中,到5月9日撰写本综述时,该模型预测,如果瑞典遵循其宣布的政策,将有大约10万人死亡,如果瑞典采取最严格的社会疏远政策,将有大约25K人死亡。5月9日,瑞典的实际死亡人数为3175人。因此,该模型大量高估了死亡人数。僵尸假设可能是问题所在。
总体结论:不能依赖该模型来指导冠状病毒政策。即使文档、编码和测试问题得到修复,模型逻辑也存在致命缺陷,这从其糟糕的预测性能中可见一斑。