几行代码中的Linux容器

这篇文章的意思是与上一篇KVM文章相对应,但它是关于容器的。我们的想法是通过在我们自己的小型容器运行器中运行Busybox Docker映像来显示容器的确切工作方式。
与VM不同,容器是一个非常模糊的术语。通常,我们将容器称为独立的代码包及其依赖项,它们可以一起发布,并在某个主机操作系统内的隔离环境中运行。如果它听起来仍然类似于VM,那么让我们深入研究一下,看看容器是如何实现的。
我们的最终目标是运行一个普通的Busybox Docker映像,但没有docker。Docker使用btrfs作为其映像的文件系统格式。让我们尝试拉取图像并将其解压到一个目录中:
现在,我们将busybox映像文件系统解压到rootfs文件夹中。当然,我们可以运行./rootfs/bin/sh并获得一个工作的shell,但是如果我们查看那里的进程、文件或网络接口的列表,我们将看到我们可以访问整个操作系统。
由于我们希望控制子进程可以看到的内容,因此我们将使用克隆(2)而不是分叉(2)。Clone的功能大致相同,但允许您传递标志,定义您想要共享的资源。
在我们的实验中,我们将尝试隔离进程、IPC、网络和文件系统,因此我们开始:
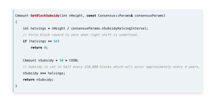
静态字符CHILD_STACK[1024*1024];INT CHILD_MAIN(void*arg){printf(";Hello from Child!PID=%d\n";,getPID();return 0;}int main(int argc,char*argv[]){int flag=CLONE_NENS|CLONE_NEWUTS|CLONE_NEWPID|CLONE_NEWIPC|CLONE_NENet;INT PID=CLONE(CHILD_Main,CHILD_STACK+sizeof(CHILD_STACK),FLAGS|SIGCHLD,argv+1);if(PID<;0){fprintf。}waitpid(PID,NULL,0);返回0;}。
这给出了一个已经很有趣的结果:子进程PID是1。我们都知道PID 1通常是init,但在本例中,我们看到子进程有自己的独立进程列表,其中它已成为第一个进程。
为了更容易地熟悉新环境,让我们在子进程中运行一个shell。实际上,让我们运行任意命令,很像docker run:
现在,使用“/bin/sh”参数运行我们的应用程序将打开一个真正的shell,我们可以在其中键入命令。这表明我们关于孤立的看法是多么错误:
#ECHO$$1#ps PID TTY时间CMD 5998分/31 00:00:00:00 sudo 5999分/31 00:00:00:00 Main 6001分/31 00:00:00 sh 6004分/31 00:00:00:00 ps。
正如我们所看到的,shell进程本身的PID为1,但实际上可以从主机操作系统查看和访问所有其他进程。原因是进程列表是从procfs读取的,它仍然是继承的。
现在,运行shell会中断ps、mount和其他命令,因为没有挂载procfs。还是比泄露父母的通行证要好。
在过去,chroot对于大多数用例来说是一个“足够好”的隔离,但是在这里,我们改用PIVOT_ROOT。此系统调用将现有的rootfs移到某个子目录中,并使另一个目录成为新的根目录:
int Child_main(void*arg){/*unmount procfs*/umount2(";/proc";,mnt_disach);/*透视根*/mount(";./rootfs";,";./rootfs";,";;bind";,MS_bind|MS_REC,";);mkdir(";。./rootfs";,";./rootfs/oldrootfs";);chdir(";/";);umount2(";/oldrootfs";,mnt_disach);rmdir(";/oldrootfs";);/*重新挂载procfs*/mount(";proc";,";/proc。/*运行进程*/char**argv=(char**)arg;execvp(argv[0],argv);返回0;}。
将tmpfs挂载到/tmp中,将sysfs挂载到/sys中并创建一个有效的/dev文件系统是有意义的,但为了简短起见,我将跳过它。
不管怎么说,现在我们只看到busybox图像rootfs中的文件,就好像我们对其进行了chroot:
/#lsbin dev etc home proc root sys tmp usr var/#mount/dev/sda2 on/type ext4(rw,relatime,data=order)proc on/proc type proc(rw,relatime)/#psPID用户时间命令1 root 0:00/bin/sh 4 root 0:00 ps/#ps axPID用户时间命令1 root 0:00/bin/sh 5 root 0:00 ps ax。
在这一点上,它看起来或多或少是孤立的,也许太孤立了-我们无法ping通任何东西,网络似乎根本无法工作。
创建新的网络命名空间只是个开始。我们需要为其分配网络接口,并对其进行设置以执行正确的数据包转发。
如果您没有br0接口,让我们手动创建(brctl是Ubuntu上bridge-utils包的一部分):
brctl addbr br0ip addr add dev br0 172.16.0.100/24ip链路集br0 upsudo iptables-A FORWARD-I wlp3s0-o br0-j ACCEPTsudo iptables-A ward-o wlp3s0-I br0-j ACCEPTsudo iptables-t nat-A POSTROUTING-s 172.16.0.0/16-j伪装。
在我的例子中,wlp3s0是我的主要WiFi网络接口,172.16.x.x是容器的网络。
我们的容器启动器应该做的是创建一对对等接口veth0和veth1,将它们链接到br0,并在容器内设置路由。
system(";IP link add veth0 type Veth Peer Name veth1";);system(";IP link set veth0 up";);system(";brctl add f br0 veth0";);
现在,如果我们在容器外壳中运行“ip link”,我们将看到一个环回接口和一些veth1@xxxx接口。但是网络仍然不起作用。让我们在容器中设置唯一的主机名,并配置路由:
int Child_main(void*arg){.。sethostname(";Example";,7);System(";IP link set veth1 up";);char IP_addr_add[4096];snprintf(IP_addr_add,sizeof(IP_Addr_Add),";IP addr add 172.16.0.101/24 dev th1";);system(Ip_Addr_Add);system(";route add default。execvp(argv[0],argv);返回0;}。
/#IP link1:LO:<;loopback>;mtu 65536 qdisk noop qlen 1 link/loopback 00:00:00:00:00:0047:veth1@if48:<;Broadcast,Multicast,Up,Low_Up,M-Down>;MTU 1500 qdisk noqueue qlen 1000链路/以太72:0A:f0:91:d5:11 brd ff:ff/#hostname示例/#ping 1.1.1.1 PING 1.1.1.1(1.1.1.1):56数据字节1.1.1.1:SEQ=0 ttl=57 time=27.161 ms 64字节from 1.1.1.1:seq=1 ttl=57 time=26.048 ms 64 bytes from 1.1.1.1:seq=2 ttl=57 time from 1.1.1.1:seq=2 ttl=57 time:seq=1 ttl=57 time=26.048 ms64 byte from 1.1.1.1:seq=2 ttl=57 time。
完整的源代码可以在https://gist.github.com/zserge/4ce3c1ca837b96d58cc5bdcf8befb80e.上找到。如果您发现错误或有什么建议,请在此留言!
显然,Docker做的远不止这些。但令人惊讶的是,Linux内核拥有这么多方便的API,而且使用它们来实现操作系统级虚拟化非常容易。