硬件商店消除
我并不打算再写一篇关于零的帖子,但是当生活抛给你一个零的时候,让你做零援助,或者诸如此类的事情。我们开始吧!
如果你想跳过曲折的揭示,只需阅读总结和建议,现在就是你的机会。
在编写简单的内存基准测试时,我始终认为写入内存的值无关紧要。最近,在运行一个简单的基准测试1来探测AVX-512商店和读取所有权之间的交互时,我遇到了奇怪的性能偏差。这就是那个故事2。
在当前主流CPU上,大多数指令的时序与数据无关。也就是说,无论指令的输入值如何,它们的性能都是相同的。与您3或我不同,您的cpu加1+2所需的时间与加68040486+80866502所需的时间相同。
整数除法依赖于大多数x86CPU的数据:较大的输入通常需要较长的时间,尽管细节在不同的微体系结构中差别很大4。
在AMD Zen和Zen2芯片上,BMI2指令PDEP和pext具有出了名的糟糕且依赖于数据的性能。
遇到非规格化数字时,浮点指令的性能通常较慢,尽管某些舍入模式(如刷新为零)可能会避免这一点。
这个列表并不是详尽的:还有其他依赖于数据的性能情况,特别是当您开始深入研究复杂的微代码指令(如cpuid)时。尽管如此,假设上面没有列出的大多数简单指令在固定时间内执行并不是不合理的。
当然,地址很重要。毕竟,地址决定了缓存行为,缓存可以很容易地解释两个数量级的性能差异5。另一方面,我认为加载或存储的数据值并不重要。除了在x86上没有广泛部署的硬件压缩缓存等场景之外,没有太多理由期望内存或高速缓存子系统关心加载或存储的位值。
GitHub上提供了与这篇文章相关的完整基准(包括一些此处未提及的其他基准)。
让我们从一个非常简单的任务开始。编写一个函数,该函数接受一个int值val,并用该值的副本填充给定大小的缓冲区。就像memset一样,只是值是int值,而不是char值。
void ill_int(int*buf,size_t size,int val){for(size_t i=0;i<;size;++i){buf[i]=val;}}。
void ill_int(int*buf,size_t size,int val){for(int*end=buf+size;buf!=end;++buf){*buf=val;}}。
在C++中,我们甚至不需要那么多:我们可以简单地直接委托给std::Fill,它做的事情与一行程序8:
STD::Fill没有什么神奇之处,它还使用了一个循环,就像上面的C版本一样。不足为奇的是,GCC和克兰将它们编译成了相同的机器代码9。
有了正确的编译器参数(在我们的例子中,-march=NATIVE-O3-funroll-loops),我们希望这个std::Fill版本(以及所有其他版本)能够使用AVX向量指令来实现,事实的确如此。对于大型填方,执行繁重提升工作的部分如下所示:
。L4:vmovdquYMMWORD PTR[rax+0],ymm1 vmovdquYMMWORD PTR[rax+32],ymm1 vmovdquYMMWORD PTR[rax+64],ymm1 vmovdquYMMWORD PTR[rax+96],ymm1 vmovdquYMMWORD PTR[rax+128],ymm1 vmovdquyMMWORD PTR[rax+128],ymm1 vmovdquYMMWORD PTR[rax+128],ymm1 vmovdquyMMWORD PTR[rax+128]。L4。
它使用8条32字节的AVX2存储指令在每次迭代中复制256字节的数据。Full函数要大得多,它有一个用于小于32字节的缓冲区的标量部分(并且在矢量化部分完成之后还可以处理奇数元素),以及一个矢量化跳转表,可以在主循环之前处理多达7个32字节的块。没有努力对齐目的地,但是我们会在基准测试中将所有内容都对齐到64字节,所以这不会有什么问题。
前戏够多了:让我们把C++版本拿出来转一转,完全随机选择两个不同的填充值(Val):0(填充0)和1(填充1)。我们将使用上面提到的GCC 9.2.1和-march=ative-O3-funroll-loops标志。
我们对其进行组织,以便对于两个测试,我们调用相同的非内联函数:执行完全相同的指令,只是值不同。也就是说,编译器没有进行任何依赖于数据的优化。
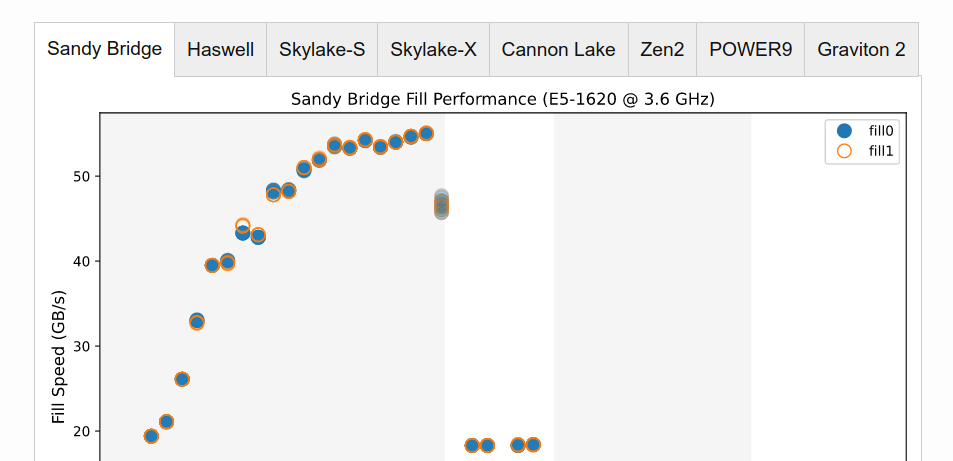
以下是这两个值的填充吞吐量(GB/s),区域大小从100到100,000,000字节。
图1毫不奇怪,性能在很大程度上取决于填充区域适合的缓存级别。
当缓冲区适合L1或L2缓存(最高可达~256 KiB 12)时,一切都相当正常。对于非常小的区域大小,相对较差的性能可以通过矢量化实现的序幕和结尾来解释:对于小的区域大小,在这些一次一次的整数循环中花费了相对大量的时间:我们不是每个周期最多复制32字节,而是仅复制4个字节。
这也解释了在~1,000到~30,000字节之间速度最快的区域性能参差不齐的原因:这是高度可重复性的,并且没有噪音。这是因为一些采样值具有更大的余数mod 32。例如,740字节的样本以大约73 GB/s的速度运行,而下一个字节为988的样本以较慢的64 GB/s运行。这是因为740%32是4,而988%32是28,因此后一种大小需要进行的清理工作是前13的7倍。本质上,我们是对锯齿函数进行半随机采样,如果您以更精细的粒度绘制此区域(选择它或只需单击此处14),您可以非常清楚地看到它。
奇怪的是,我们看到零店和一店之间有明显的分歧。请记住,这是完全相同的函数、执行相同指令流的相同机器代码,只是传递给STORE指令的ymm1寄存器的值有所不同。无论是在L3覆盖的区域(在我的系统上最高可达6MiB),还是在我们预期RAM未命中的区域(看起来RAM区域的差异会缩小,但这主要是肉眼上的把戏),存储0始终比存储1快17%到18%:相对性能差异大致相同)。
这里发生了什么事?为什么CPU关心存储的是什么值,为什么零是特殊的呢?
当我们关注适合L2或L3的区域时,我们可以通过测量L2_LINES_out.Silent和L2_Lines_out.non_Silent事件来获得一些额外的洞察力。这些事件以静默或非静默方式测量从L2逐出的线路数量。
统计由L2缓存填充触发时由L2缓存静默丢弃的行数。这些线路通常处于共享或独占状态。
统计由二级缓存填充触发时由二级缓存逐出的行数。这些线路处于修改状态。修改后的行写回到L3。
这里所指的状态是MESI高速缓存状态,通常缩写为M(已修改)、E(独占,但未修改)和S(可能是共享的,未修改)。
第二个定义并不完全准确。具体地说,它意味着只有修改后的行才会触发非静默事件。但是,我发现处于E状态的未修改行也可以触发此事件。粗略地说,未修改行的行为似乎是,在L2和L3中未命中的行通常以非静默方式被填充到L2中,但是在L2中未命中并且在L3中命中的未修改行通常将被静默地逐出15。当然,被修改的行必须被非静默地逐出以便用新数据更新外层。
总而言之:静默逐出与处于E或S状态的未修改的线路相关联,而非静默逐出与M、E或(可能)S状态的线路相关联,对E和S的静默与非静默的选择是在某些未知事物中做出的。
让我们看一下填充0和填充1情况下的静默逐出和非静默逐出:
图2两种情况的逐出总数(静默和非静默)是相同的:当区域适合L2时接近于零17,然后迅速增加到每个存储的高速缓存线~1逐出。在L3中,填充1的行为也与我们预期的一样:基本上所有的驱逐都是非静默的。这是有意义的,因为必须非静默地逐出已修改的行,以将其已修改的数据写入高速缓存子系统的下一层。
对于填充0,情况就不同了。一旦缓冲区大小不再适合L2,我们看到从L2收回的总数相同,但其中63%是静默的,其余的是非静默的。请记住,只有未经修改的行才有被无声驱逐的希望。这意味着至少63%的时间,L218能够检测到写入是冗余的:它不改变线路的值,因此线路被静默地逐出。也就是说,它永远不会写回L3。这大概就是导致性能提升的原因:L3上的压力降低了:尽管所有隐含的读取19仍然需要通过L3,但这些行中只有1行最终会被写回。
一旦测试开始超过L3阈值,即使在填充0的情况下,所有驱逐也变为非静默状态。这并不一定意味着零优化停止发生。正如前面提到的15,这是一种典型的模式,即使对于只读工作负载也是如此:一旦行作为L3未命中而不是命中的结果到达L2,它们随后的逐出就变成非静默的,即使从未写入也是如此。因此,我们可以假设这些行可能仍被检测为未修改,尽管我们至少在L2_LINES_OUT事件发生时失去了对效果的可见性。也就是说,尽管所有逐出都是非静默的,但部分逐出仍指示传出数据未修改。
事实上,我们可以确认,当使用一组不同事件移入RAM时,这种明显的优化仍然会发生。有几个可供选择-我试过的所有这些都讲述了相同的故事。我们将重点介绍unc_arb_trk_requests.write,文档如下:
重要的是要注意,这些事件监视器由L3和内存之间的数据流使用,而不是L2和L3之间的数据流使用。因此,这里的写入通常是指将到达内存的写入。
下面是此事件如何针对我们一直在运行的同一测试进行缩放(为了将焦点转移到感兴趣的区域,大小范围已改变)20:
图3当缓冲区超过L3的大小时,行为良好的填充1的写入次数接近每个高速缓存线一次写入-同样,这也是预期的。对于更叛逆的填充物来说,几乎正好是这个数字的一半。对于基准测试写入的每两行,我们只向内存写回一行!如果我们测量集成存储器控制器21处的存储器写入,也会反映相同的2:1比率:写入零仅导致存储器控制器处的写入次数的一半。
这一切都相当奇怪。有一个“冗余写入”优化来避免写回相同的值,这并不奇怪:这似乎可以使一些常见的写入模式受益。
它似乎只适用于全零值,这可能有点不寻常。这可能是因为零覆盖零是最常见的冗余写入情况之一,并且检测零值可以比完全比较更廉价地完成。还有,“是零吗?”状态可以作为单个位进行通信和存储,这可能很有用。例如,如果L2参与重复检测(L2_LINES_OUT结果显示是这样),那么检测可能在线路被逐出时发生,此时您想要与L3中的线路进行比较,但是您肯定不能将整个旧值存储在L2中或其附近(这将需要与L2本身一样大的存储空间)。但是,您可以将该行为零的指示符存储在单个位中,并将现有行作为驱逐过程的一部分进行比较。
然而,最奇怪的是,根据不同的参数22,优化并不是100%地启动,而是只对40%到60%的代码行起作用。是什么导致了这种效果呢?可以想象,可能存在某种类型的预测器,其根据例如优化最近是否有效(即,冗余存储最近是否常见)来确定是否应用该优化。或许该预测器还考虑了诸如出站队列23的占用率之类的因素:当总线接近容量时,与总线上几乎没有明显压力的情况相比,搜索消除冗余写入可能更值得功率或等待时间损失。
在此基准测试中,任何预测者都会发现优化是100%有效的:每次写入都是冗余的!因此,我们可能会猜测,第二个条件(队列占用率)会导致只消除一些商店的行为:随着更多的商店被消除,总线上的负载会降低,因此在某个点上,预测器不再认为删除商店是值得的,并且您会达到一种稳定状态,即根据预测器阈值只消除一小部分商店。
我们可以在某种程度上检验这一理论:在这个模型中,任何商店都可以被淘汰,但被淘汰商店的比率受到预测者行为的限制。因此,如果我们发现纯冗余零商店的基准以60%的比率被消除,我们可能会预期任何至少具有60%冗余商店的基准可以达到60%的比率,而如果比率较低,您将看到所有冗余商店被完全消除(因为现在总线始终保持足够的活动以触发预测器)。
让我们尝试一个基准测试,它添加了一个新的实现alt01,它在写入0的缓存行和写入1的缓存行之间交替。所有写入都是冗余的,但只有50%是零,因此在涉及预测器的理论下,我们预计可能会消除50%的存储(即,100%的冗余存储被消除,它们占总数的50%)。
这里我们关注L3,类似于上面的图2,显示了静默驱逐(非静默驱逐构成了其余部分,与前面一样加起来为1):
图4我们没有看到50%的消除。相反,我们看到全零情况的消除率还不到一半:27%对63%。L3区域的性能比All One的情况要好,但只是稍微好一点!因此,这并不支持预测器能够消除任何商店并主要根据出站队列占有率进行操作的理论。
类似地,我们可以检查缓冲区仅适合RAM的区域,类似于上面的图3:
图5回想一下,这些行显示了到达存储器子系统的写入次数。在这里,我们可以看到alt01再次划分了0和1之间的差异:大约75%的写入到达内存,而在全零的情况下只有48%,因此消除的效果同样大约是一半。在本例中,性能还划分了全0和全1之间的差异:它几乎正好介于其他两种情况之间。
所以我不知道到底是怎么回事。似乎只有一小部分的线条有资格被淘汰,这是由于一些未知的内部机制在UARCH中的原因。
最后,下面是各种其他Intel和AMDx86架构以及IBM的POWER9和Amazon的Graviton 2 ARM处理器的性能结果(与图1相同),每个选项卡一个。
在测试的任何其他非SKL硬件的性能配置文件中,冗余写入优化并不明显。甚至没有像哈斯韦尔或Skylake-X这样密切相关的英特尔硬件。我还用性能计数器做了一些现场测试,没有看到任何写操作减少的证据。因此,就目前而言,这可能只是Skylake客户端的一件事(当然,Skylake客户端可能是部署最广泛的英特尔客户端,即使是因为有许多名称不同的变体:Kaby Lake、Coffee Lake等)。请注意,Skylake-S在这里的结果是一个与本文其余部分不同的(台式机i7-6700)芯片,所以我们至少可以确认这发生在两个不同的芯片上。
除了RAM区域,沙桥的吞吐量是其后继者的一半:尽管支持32字节AVX指令,但内核中只有16字节的加载/存储路径。
AMD Zen2在L2和L3区域具有出色的写入性能。所有英特尔芯片在L2中的写入吞吐量都下降到大约一半:略高于16字节/周期(对于大多数芯片来说,大约是50 GB/s)。Zen2保持其L1吞吐量,实际上在L2中有最高的结果:超过100 Gb/s。在此测试中,Zen2在L3中也管理超过70 Gb/s,远远好于Intel芯片。
Cannon Lake和Skylake-X在L2居住区都表现出相当大的样本间方差。我在这里的理论是预取器干扰,它的行为与早期的芯片不同,但我不确定。
Skylake-X的L3设计与其他芯片不同,L3填充吞吐量相当低,约为当代Intel芯片的一半,不到Zen2的三分之一。
POWER9的表现既不差也不好。最有趣的部分可能是高L3填充吞吐量:L3吞吐量与L1或L2吞吐量一样高或更高,但仍不在Zen2范围内。
亚马逊的新Graviton处理器非常有趣。它似乎被限制在每个周期24个16字节的存储,使其可能的存储吞吐量达到40 GB/s的峰值,因此与可以达到100 GB/s或更高的竞争对手(他们有更高的频率和32字节的存储)相比,它在L1区域表现不佳,但它一直保持着40 GB/s的RAM大小,RAM结果足够平,可以在其上提供饮料,而这是在共享的64个CPU主机上,我只支付了单个内核25的费用!RAM性能是所有测试的硬件中最高的。
以下是我们发现的简要总结。如果你刚读完整篇文章,这会有点多余,但我们需要容纳每个刚刚跳到这一部分的人,对吗?
当将全零高速缓存线写入已经全零的高速缓存线时,英特尔芯片显然可以消除一些冗余存储。
此优化至少最早应用于L3的L2写回,因此适用于工作集不适合L2的扩展。
根据工作集大小,该效果消除了对L3的写入访问和对内存的写入。
对于这里讨论的纯存储基准,此优化的效果是写入次数减少了~63%(到L3)和~50%(到内存),运行时间减少了15%到20%。
那么有没有什么是真正有用的呢?我们能利用这一发现将计算中真正重要的事情的速度提高四倍吗?这些任务包括比特币挖掘、高频交易和实时定向广告。
没有这样的事情,没有-但它可能会对某些情况起到小小的提振作用。
这些案例中的许多可能在没有任何特别努力的情况下获得了好处。毕竟,零已经是一个特定值:对于某些语言,它是内存从操作系统到达的方式,并且是在语言分配级别。因此,许多可能获得这种好处的案例,可能已经是这样了。
冗余的零过零可能也不像您想象的那么罕见:考虑到在低级语言中,内存通常在从分配器收到后被清除,但是在许多情况下,这个内存直接来自操作系统,所以它已经是零26了。
如果您正在进行大量冗余写入,您可能要做的第一件事是。
..



