Spleeter-音乐源-分离引擎
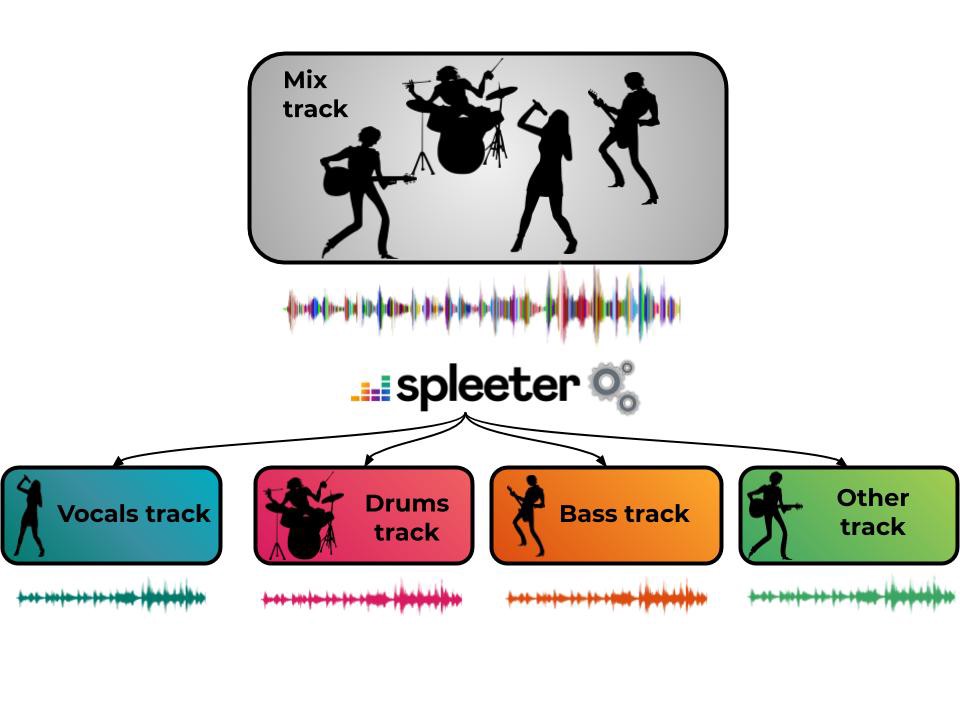
我们将发布Spleeter,以帮助音乐信息检索(MIR)研究团体利用最先进的源分离算法的力量。它以基于TensorFlow的Python库的形式出现,带有用于2、4和5个词干分离的预先训练的模型。Spleeter将在代尔夫特举行的2019年ISMIR会议上进行展示和现场演示。
虽然不是一个广为人知的话题,但几十年来,源分离问题已经引起了大量音乐信号研究人员的兴趣。它从一个简单的观察开始:音乐录音通常是几个单独的乐器轨道(主唱、鼓、贝斯、钢琴等)的混合。音乐源分离的任务是:给定一个混合,我们可以恢复这些单独的音轨(有时称为词干)吗?这有许多潜在的应用:思考混音、混音、主动倾听、教育目的,但也有其他任务的预处理,如转录。
有趣的是,我们的大脑非常善于分离仪器。只要专注于这首曲子中的一种乐器(比如说主唱),你就能非常清晰地听到它与其他乐器的声音。然而,这并不是真正的分离,你仍然可以听到所有其他的部分。在许多情况下,可能无法准确恢复混合在一起的各个磁道。因此,挑战是要尽可能地接近它们,也就是说,在不造成太多扭曲的情况下,尽可能地接近原件。
多年来,来自世界各地的数十个才华横溢的研究团队探索了许多策略。如果你对这段迷人的旅程感兴趣,你应该去阅读这篇文献概述,或者这篇。最近,进展的速度取得了一些巨大的飞跃,这主要是由于机器学习方法的进步。为了保持跟踪,人们一直在国际评估活动中比较他们的算法。这就是我们如何知道Spleeter的性能与最好的建议算法的性能相匹配的原因。
此外,Spleeter速度非常快。如果您运行的是GPU版本,那么可以预期分离速度比实时快100倍,这使得它成为处理大型数据集的一个很好的选择。
我要说的可不少。如果您是从事音乐信息检索的研究人员,并且一直认为源分离工件不适合作为管道中的预处理步骤……。嗯,你也许应该重新考虑一下,试试斯普莱特。如果你是一名音乐黑客,想要用Spleeter构建一些很棒的东西,那就去做吧。实际上,Spleeter是麻省理工学院授权的,所以你可以自由地以任何你想要的方式使用它。不用说,如果您计划在受版权保护的歌曲上使用Spleeter,请确保您事先获得了版权所有者的适当授权。
在引擎盖下,Spleeter是一个相当复杂和精心制作的引擎,但我们已经努力使其真正易于使用。实际的分离可以通过单个命令行来实现,它应该可以在您的笔记本电脑上工作,而不管您的操作系统是什么。对于更高级的用户,有一个名为Separator的python API类,您可以将其直接操作到您常用的管道中。
我们已经竭尽全力拿出一份详尽的文件。请不要犹豫通过传统的GitHub工具向我们反馈、指出问题或提出改进建议!
我们致力于源代码分离已经有很长一段时间了(我们已经在ICASSP 2019上有了一份出版物)。我们已经将Spleeter与Open-unMix(Inria的一个研究团队最近发布的另一个开源模型)进行了基准比较,并报告了速度提高后性能略有提高(请注意,训练数据集不同)。
和平号研究人员面临的硬限制之一是由于版权问题缺乏公开可用的数据集。在Deezer这里,我们可以访问一个相当大的目录,我们一直在利用它来构建Spleeter。因为我们不能共享这些数据,所以把它变成一个可访问的工具是我们让每个人都可以复制我们的研究的一种方式。站在更道德的立场上,我们认为研究人员之间不应该因为他们获得或缺乏受版权保护的材料而进行不公平的竞争。
最后但并非最不重要的一点是,培训这类模型需要大量的时间和精力。通过做一次并分享结果,我们希望省去别人的一些麻烦和资源。
自从我们发布Spleeter以来,我们已经收到了很多反馈,其中大多数都是非常积极的,我们很高兴看到人们对我们的工作给予了如此多的关注。然而,这些反应中的一些可能有点过度热情,所以让我们重申几件事。Spleeter是一个很好的工具,但是我们绝不能声称已经“解决”了源分离问题。数以百计的研究人员和工程师工作了几十年,取得了进展,并建造了Spleeter所基于的工具。这是我们对一个生动、不断增长和开放的生态系统的贡献,希望其他人也能在此基础上建立起来。
最后,值得一提的是,混音是一门艺术,掌握音响工程师本身就是艺术家。显然,我们不打算以任何方式损害他们的工作或影响任何人的信用。当您使用Spleeter时,请负责任地使用。