虚幻世界:一张人工智能限制和偏见的地图
算法偏差(也称为机器偏差、统计偏差或模型偏差,Nocope图对此给予了特别关注)是机器学习算法对历史偏差和数据集偏差的进一步放大。偏差问题主要源于这样一个事实,即机器学习算法是最有效的信息压缩算法之一,这就产生了信息分辨率、衍射和丢失的问题。12自古以来,算法就是具有经济性质的程序,旨在以最少的资源(空间、时间、能量和劳动力)在最短的步骤中实现结果。13今天,人工智能公司的军备竞赛仍然关注的是寻找最简单、最快的算法来利用数据。如果信息压缩在企业AI中产生最大的利润率,从社会角度来看,它就产生了歧视和文化多样性的损失。
虽然人们普遍在偏见问题下理解人工智能的社会后果,但对技术限制的普遍理解被称为黑匣子问题。黑匣子效应是深层神经网络的一个实际问题(它过滤信息如此之多,以至于它们的推理链无法逆转),但它已经成为认为人工智能系统不仅高深莫测、不透明,甚至是“异类”和失控的普遍借口。14在开发的早期阶段,黑匣子效应是任何实验机器的本质的一部分(人们已经注意到,蒸汽机的功能在一段时间内仍然是一个谜,即使在成功测试之后)。真正的问题是黑箱言论,它与阴谋论情绪密切相关,在阴谋论情绪中,人工智能是一种无法研究、了解或政治控制的神秘力量。
大规模数字化在20世纪90年代随着互联网的发展而扩大,并在21世纪头10年随着数据中心的发展而升级,它提供了历史上第一次免费和不受监管的海量数据资源。知识非激进主义(当时称为大数据)制度逐渐采用有效的算法,从这些开放的数据来源中提取“情报”,主要用于预测消费者行为和销售广告。知识经济演变成一种新的资本主义形式,被不同的作者称为认知资本主义,然后是监督资本主义。互联网信息泛滥、庞大的数据中心、速度更快的微处理器和数据压缩算法为21世纪人工智能垄断的崛起奠定了基础。
构成AI源头的数据集是什么样的文化技术对象?训练数据的质量是影响机器学习算法提取的所谓“智能”的最重要因素。有一个重要的视角需要考虑,才能理解人工智能是一种虚幻的东西。数据是价值和情报的第一来源。算法是第二位的;它们是将这样的价值和智能计算到模型中的机器。然而,训练数据从来都不是原始的、独立的和不偏不倚的(它们本身就是“算法”)。16训练数据集的切割、格式化和编辑是一项费力而精细的工作,这对最终结果可能比控制学习算法的技术参数更重要。选择一个数据源而不是另一个数据源的行为是人类干预“人工”思维领域的深刻标志。
训练数据集是一种文化构造,而不仅仅是一种技术构造。它通常包括与理想输出数据相关联的输入数据,例如带有其描述的图片,也称为标签或元数据。17典型的例子是博物馆藏品及其档案馆,其中的艺术品由元数据组织,如作者、年份、媒介等。为图片指定名称或类别的符号学过程从来都不是公正的;这一行动在机器认知的最终结果上留下了另一个深刻的人类印记。机器学习的训练数据集通常通过以下步骤组成:1)生产:产生信息的劳动力或现象;2)捕获:通过工具将信息编码成数据格式:3)格式化:将数据组织成数据集:4)标记:在监督学习中,将数据分类为类别(元数据)。
机器智能是在大量的数据集上进行训练的,这些数据集的积累方式既不是技术中立的,也不是社会公正的。原始数据不存在,因为它依赖于通过扩展的网络和有争议的分类在很长一段时间内积累的人类劳动、个人数据和社会行为。18机器学习的主要训练数据集(NMIST、ImageNet、野外标记的人脸等)。O
模式识别的原型机器是弗兰克·罗森布拉特(Frank Rosenblatt)的感知器(Perceptron)。感知器于1957年在纽约州布法罗市的康奈尔航空实验室发明,它的名字是“感知和识别机器人”的缩写。26假设感知器的视觉矩阵是20x20的光感受器,它可以学习如何识别简单的字母。视觉模式被记录为人工神经元网络上的印象,这些人工神经元随着相似图像的重复而被激活,并激活一个单一的输出神经元。如果给定图像被识别,则输出神经元触发1=TRUE,或者如果给定图像未被识别,则输出神经元触发0=FALSE。
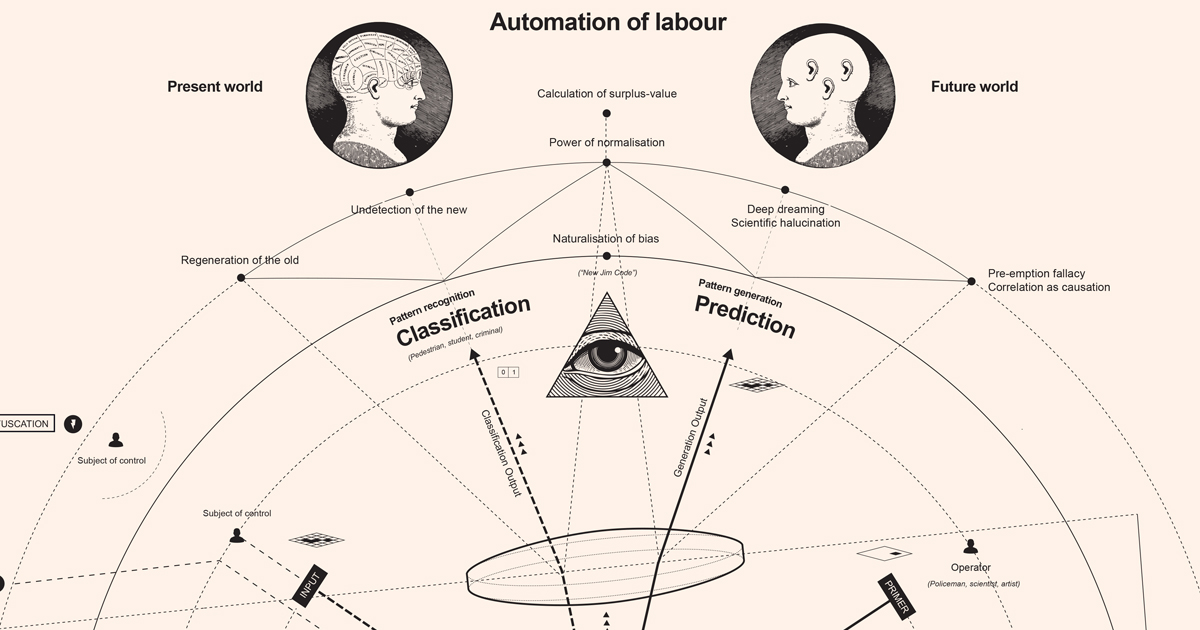
感知的自动化,就像计算机装配线上像素的视觉蒙太奇一样,最初是麦卡洛克和皮特隐含的人工神经网络的概念。27一旦视觉模式识别算法挺过了“人工智能的冬天”,并在本世纪头十年末被证明是有效的,它也被应用于非视觉数据集,适当地开创了深度学习的时代(模式识别技术应用于所有类型的数据,而不仅仅是视觉数据)。今天,在自动驾驶汽车的情况下,需要识别的模式是道路场景中的对象。在自动翻译的情况下,需要识别的模式是跨双语文本的最常见的单词序列。不管它们的复杂性如何,从机器学习的数值角度来看,图像、运动、形式、风格和伦理决策等概念都可以描述为模式的统计分布。从这个意义上说,模式识别真正成为一种新的文化技术,应用于各个领域。出于解释的目的,Noscope被描述为一台运行在三种模式上的机器:训练、分类和预测。用更直观的术语来说,这些模态可以称为:模式提取、模式识别和模式生成。
罗森布拉特的感知器是第一个为当代意义上的机器学习铺平道路的算法。在“计算机科学”还没有被采用为定义的时候,这个领域被罗森布拉特自己称为“计算几何”,具体地说是“连接主义”。然而,这些神经网络的业务是计算统计推断。神经网络计算的不是确切的模式,而是模式的统计分布。仅仅在人工智能拟人化营销的表面上,人们发现了另一个需要审视的技术和文化对象:统计模型。机器学习中的统计模型是什么?它是如何计算的?统计模型和人类认知之间有什么关系?这些都是需要澄清的关键问题。就需要做的去神秘化工作而言(也是为了消除一些天真的问题),重新表述“机器能思考吗?”这个老生常谈的问题会很好。理论上更合理的问题是“统计模型能思考吗?”、“统计模型能发展意识吗?”等等。
人工智能的算法经常以炼金术公式的形式出现,能够提炼出“外星人”形式的智能。但是海藻是怎么回事呢?
..