适用于S3兼容对象存储的英特尔和ARM性能特征
AWS最近宣布他们新的ARM驱动的Graviton2服务器正式上市,这让我们重新审视了这些ARM服务器的性能。在这篇博客文章中,我们描述了你可能会感到惊讶的结果。
Minio是一款Apache许可的开源S3兼容对象存储服务器,特别注重高性能。它能够使用普通硬盘每秒读写10 GB,或者结合使用SSD或NVMe驱动器,使用100 Gbit网络,每秒可以读写100 GB。
为了实现这些高水平的性能,Minio利用了Golang(Minio的主要开发语言)紧密集成的汇编语言功能。
Minio的两个核心算法对计算要求很高,它们是擦除编码(用于数据持久性)和散列(用于比特腐烂检测)。这两种算法都使用SIMD(单指令多数据)指令进行了大量优化,不仅适用于Intel平台(AVX2和AVX512),还适用于ARM(NEON)和PowerPC(VSX)。
Minio依赖的第三种密钥算法是(每个对象)加密。由于Golang的标准库通过优化的代码为各种加密技术提供了强大的支持,Minio简单地使用了这些实现。
由于其核心算法的高度优化特性,Minio是在不同CPU架构之间进行比较基准测试的一个很好的目标。但是,为了消除任何系统影响,如网络速度和/或存储介质吞吐量,我们选择进行单独的基准测试,如下所述。
为了比较新的Graviton2 CPU与英特尔的堆叠情况,我们对两种不同类型的EC2实例进行了测试。对于英特尔,我们选择了c5.18xLarge实例,而对于ARM/Graviton2,我们使用了新的m6g.16Large类型。
英特尔Skylake服务器是双插槽,每个CPU有18个内核。这导致每个CPU具有超线程的36个VCPU,或者两个CPU加在一起总共有72个VCPU。ARM服务器只使用一个64核插槽,没有超线程。有关更多详细信息,请参阅下表:
|架构|x86_64|aarch64||CPU|72|64||每核线程|2|1||每插槽核|18|64||插槽|2|1||NUMA节点|2|1||L1d缓存|32K|64K||L1i缓存|32K|64K||二级缓存|1024K|1024K||三级缓存|25344K|32768K。
由于与ARM芯片相比,英特尔CPU多了8个(超线程)vCPU,因此我们将测试中的最大线程数限制为64个,以创造一个平等的竞争环境。
下面的组合图表在左侧显示了运行8个数据和8个奇偶校验(里德·所罗门)擦除编码步骤的单核性能,作为从1MB到25MB的不同数据碎片大小的函数。英特尔Skylake Here与ARM Graviton2 CPU相比具有明显且巨大的性能优势。它会随着数据分片大小的增加而略有降低,而ARM性能几乎保持不变。
如果我们查看右侧的多核性能图(所有64核都100%忙于在两个平台上进行擦除编码),我们基本上可以看到一幅倒置的图景。与英特尔相比,ARM的聚合性能非常平坦,速度大约快2倍,随着数据分片大小的增加,差距实际上也在不断扩大。
将我们的注意力转向Minio用于比特腐烂检测的散列算法,我们可以看到一个类似的模式。在单核性能方面,随着块大小的增加,英特尔明显占据上风,但优势较小。
关于多核性能,在所有不同的块大小下,ARM的性能几乎是英特尔的两倍多,这一点再次出现了逆转。
最后,对于加密,模式也是相同的。在单核上,英特尔显然更优秀,尽管差距随着块大小的增加而减小(而且ARM在性能方面也几乎完全一致)。
然后,当谈到多核性能时,ARM再次以两倍多的优势击败了英特尔。
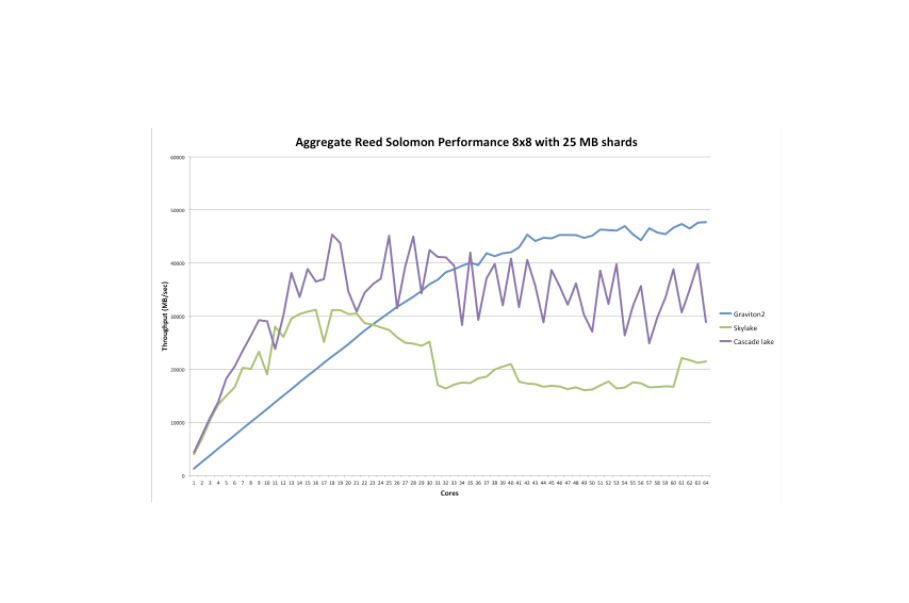
基于我们收集的数据,我们能够制作另一个有趣的对比图。它显示了(聚合的)Reed Solomon擦除编码性能(8个数据和8个奇偶校验,25MB分片)与Graviton2相比,它是Skylake(和Cascade Lake;下面详细介绍)核心数量的函数,范围从单个核心到64个核心。
这更详细地证实了我们上面观察到的结果。Intel Skylake CPU高达约20个内核,击败了Graviton2,但此后(聚合)性能大致持平(甚至有所下降)。
另一方面,Graviton2在30多个内核之前具有完全的线性性能可伸缩性,之后性能提升开始逐渐减弱。
由于Skylake不是最新一代的Intel CPU,我们决定也在Cascade Lake服务器上运行此测试。为此,AWS提供c5.24xLarge实例类型,该实例类型具有双级联湖CPU,每个CPU总共提供96个VCPU和36608K的L3缓存。为了进行更好的比较,我们再一次没有超过64个同步内核。
可以看出,在我们的测试中,与Skylake相比,Cascade Lake的速度要快得多,尽管它显示的图形更加参差不齐。它的峰值性能在20到30个内核范围内(可能并不令人惊讶,因为它有24个物理内核),与Skylake相比,内核数量越多,下降的幅度就越小。
如果我们同样将喀斯喀特湖与引力2进行比较,那么在低核心数时,它的速度要快得多,但对于更高的核心数(如果你要做某种移动平均数),它就位于Skylake和Graviton2之间。因此,Cascade Lake显然比Skylake提供了更多的性能,但它无法满足Graviton2的要求。
如上所述,对于(双)Intel CPU的结果有些不令人满意,这促使我们再做一次测试,以查看在单插槽服务器上的性能会是什么样子。
事实证明,c5.9xLarge和c5.12xLarge实例类型正是我们要寻找的类型,因此我们在这些实例类型上重复了上面的线性可伸缩性测试。因为我们现在运行在单个CPU上,所以Skylake的限制是36核,而Cascade Lake的限制是48核。为便于比较,Graviton2的图表重复使用了多达64个内核(当然也包括单个插槽)。
生成的图形在形状上非常相似,但与前面显示的双插槽图形相比要平滑得多。同样,英特尔CPU在较低的核数下提供出色的性能,在接近最大核数之前会在物理核数附近达到峰值。
此图详细说明的是,双插槽服务器(基本上)没有额外性能表明,双插槽服务器可能在内存访问方面存在严重争用,这严重影响了性能。事实上,Mino的代码库是高度优化的性能无疑将在很大程度上归因于这一现象。
我们首先要说的是,出于所有实际目的,英特尔和ARM平台都提供了足够的计算能力,即使是最快的网络速度和NVMe驱动器也会饱和。因此,从这个意义上说,两者都完全能够满足对Minio对象存储服务器的最高性能要求。
话虽如此,但显而易见的是,随着AWS推出Graviton2处理器,ARM架构已经缩小了与英特尔的性能差距,甚至在多核性能上超越了英特尔。
特别是在大量多线程的环境中,Graviton2CPU看起来状态很好。由于云工作负载要求服务器应用程序处理(许多)多租户场景,这可能是一个真正的好处。此外,随着Fireracker(用于轻量级虚拟化和无服务器计算)等技术变得越来越流行,这些最新的ARM芯片是一个很好的补充。
最后,考虑到ARM来自移动计算领域的背景,Graviton2的功耗很可能相对较低(尽管具体细节尚不清楚)。
亚马逊并不是唯一一家关注这个新的ARM平台的公司,其他一些需要关注的发展包括:
安培计算:具有80个内核的安培Altra处理器与多达128通道的第四代PCIe支持相结合,有望成为高性能、可扩展且高能效的平台。
Nuvia等初创公司将推出新一代处理器,提供推动下一代计算所需的性能和能效(考虑到他们的背景,想必是在ARM?)