薛定谔丢包
对带宽的需求正在推动像Niometrics这样的网络软件供应商支持100 GbE网络接口控制器(NIC)。我们的网络探测器使用数据平面开发工具包(DPDK)绕过Linux内核,将流量定向到用户空间。这消除了NIC中断的开销,以实现高带宽处理速率。然而,100GbE网卡带来了新的挑战。我们面临的问题之一是处理器间中断(IPI)导致较低带宽的零星数据包丢弃,没有明显的拥塞。在这篇文章的第一部分,我们将简要讨论不同类型的中断、中断处理硬件和内存管理单元。在第二部分中,我们将简要介绍由于多套接字系统中的中断处理而导致的故障排除、调试和修复问题。
在开始之前,我们先介绍一下本文涉及的硬件和软件环境:
6TB内存(使用hugepagesz=1G和hugepages=1024个内核命令行参数为每个插槽保留256个1G大型页面,为大型页面保留1 TB)。
使用Isolcpus、NOHZ_FULL、RCU_NOCBS和RCU_NOCB_POLL内核命令行参数隔离所有关键内核并使其几乎无抖动。
在使用DPDK的网络探测中,数据包接收由轮询模式下的RX线程处理。这些线程在紧密循环中不断轮询NIC RX环中的数据包。通过将上下文切换到内核空间来处理中断,从而中断“中断”用户空间任务的执行。这会引入抖动,这种抖动非常罕见,不会影响吞吐量,但在100GbE网卡上可能会导致丢包。增加NIC RX环大小(或RX环的数量)可以缓解此问题,但并非总是如此。
在我们描述每种类型如何影响高性能系统之前,让我们先来看看APIC的内幕。
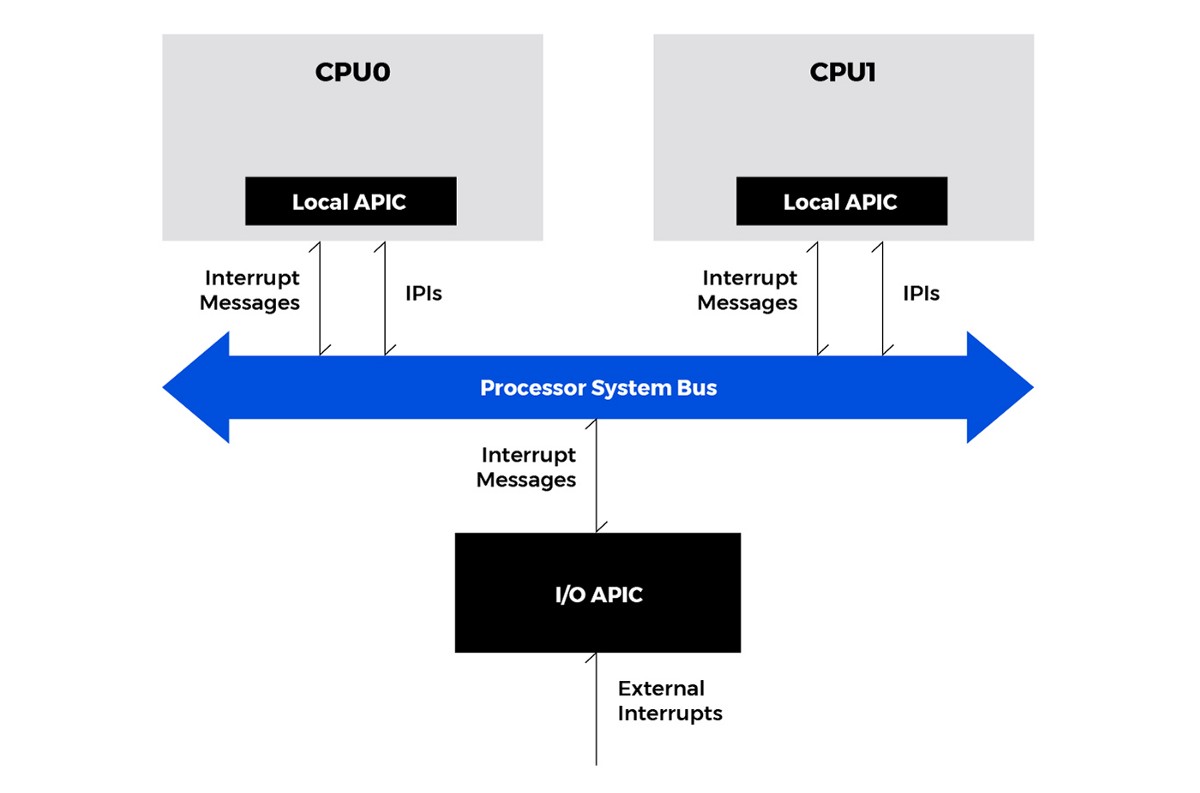
APIC代表高级可编程中断控制器。在x86-64系统中,通过以下方式处理中断:
每个CPU的本地APIC接收中断,并将这些中断发送到处理器内核进行处理。中断可能来自处理器的中断引脚、内部源和外部I/O APIC(或其他外部中断控制器)。
在对称多处理(SMP)系统中,本地APIC向系统总线上的其他逻辑处理器发送IPI消息,或从系统总线上的其他逻辑处理器接收IPI消息。IPI消息可用于在系统中的处理器之间分配中断或执行系统范围的功能(例如启动处理器或在一组处理器之间分配工作)。
I/O APIC是Intel系统芯片组的一部分,它从系统及其关联的I/O设备接收外部中断事件,并将它们作为中断消息中继到本地APIC。
在SMP系统中,I/O APIC还提供了一种机制,用于将外部中断分配给系统总线上选定处理器或处理器组的本地APIC。
我们使用irqBalance守护进程将所有外部中断处理从参与数据包处理的隔离核心移至一组保留用于中断处理的核心。这可确保外部中断不会对隔离内核上的任务造成抖动。它还确保为IRQ亲和性分配的核心“最接近”设备的NUMA节点。IRQBALANCE_BANDIRED_CPUS环境变量必须设置为隔离内核的掩码,以确保没有为它们分配中断。以下是一些示例来说明这一点。
在内核2.6.21之前,计时器滴答以CONFIG_HZ(默认情况下为1000/秒)的速率在每个内核上运行。
无计时内核(在内核2.6.21+中)禁用了空闲内核上的内核计时器计时器计时。调度时钟中断用于强制繁忙的内核调度多个任务,而空闲的内核没有要调度的任务,因此它不需要调度时钟中断。
NOHZ_FULL内核命令行参数(在内核3.9+中引入)是在无计时内核之上的优化,它将无计时行为扩展到只有一个运行任务的内核。仍然需要为进程管理操作(如计算核心负载、维护调度平均值等)每秒安排一个滴答。
处理器间中断允许CPU向系统中的任何其他CPU发送中断信号。它们由ARCH/x86/include/asm/entry_arch.h中的BUILD_INTERRUPT宏定义。对于SMP内核,“SMP_”位于函数名的前面。例如,对于BUILD_INTERRUPT(CALL_Function_Interrupt,Call_Function_Vector),调用函数中断向量由SMP_CALL_Function_Interrupt()处理。通过调用send_ipi_all()、send_ipi_allbutself()、send_ipi_self()、send_ipi_ask_allbuself()&;send_ipi_ask()函数指针所指向的函数来引发中断。
呼叫功能中断是可以发送到多个CPU的IPI。它是通过调用NATIVE_SEND_CALL_FUNC_IPI()引发的。
呼叫功能单次中断是一次可以发送到一个CPU的IPI。它是通过调用NATIVE_SEND_CALL_FUNC_SINGLE_IPI()引发的。
TLB击落是一种特殊类型的CAL中断,它有自己的计数器,即/proc/interrupts中的TLB行。CAL计数器不包括TLB击落。
要理解TLB击落中断的目的,我们需要简要讨论分页是如何工作的,因为它们用于支持多处理器系统上的分页。
逻辑地址-包括在机器语言指令中。它由线段和偏移组成。
线性地址(虚拟地址)-单个48位无符号整数,最高可用于寻址256TB。
MMU(存储器管理单元)的分页单元将线性地址转换为物理地址。下图说明了到4KB页的线性地址转换与到1 GB页的线性地址转换。
简而言之,将线性地址转换为4KB物理页地址涉及访问4个存储器位置(PML4E、PDPTE、PDE&;PDE),而1 GB物理页面访问涉及访问2个存储器位置(PML4E&;PDPTE)。这就是访问1 GB大页面比访问4KB页面更快的原因,因此推荐DPDK使用。
转换后备缓冲器(TLB)是用于加速线性地址转换的缓存。当第一次使用线性地址时,通过缓慢访问主存储器中的分页表来计算相应的物理地址。然后将物理地址存储在TLB条目中,从而可以快速转换对相同线性地址的进一步引用。在多处理器系统中,每个CPU都有自己的本地TLB。与硬件高速缓存相反,TLB的相应条目不需要同步,因为在不同CPU上运行的进程可能将相同的线性地址与不同的物理地址相关联。
在同一CPU上的两个进程之间切换时,会发生TLB刷新。当两个进程共享相同的页表(例如,同一进程的线程)时,不会发生这种情况。从常规进程切换到内核线程时不会发生这种情况。
在多处理器系统上,当刷新CPU上的TLB时,内核还必须刷新使用相同页表集的CPU上的相同TLB条目。这是由TLB击落中断完成的。
现在,我们继续回顾在排除与中断相关的性能问题时所经历的步骤。
我们必须找到发送到运行关键RX线程的内核的中断。这可以通过监视内核的中断计数器来实现。可以使用一个简单的脚本来监视/proc/interrupts。
从脚本的输出中,我们可以看到LOC在运行单个用户线程的NOHZ_FULL内核上每秒传递一次。这是意料之中的。正在传送的TLB中断(每秒6个中断)是需要进一步调试的中断。
要确定处理中断的CPU+内核函数,我们必须计算出中断计数器递增的位置。可以在以下位置找到中断计数器符号:ARCH/x86/kernel/irq.c:arcshow_interrupts()。处理程序是使用incirqstat()递增计数器的函数。在某些情况下,只有一个中断处理程序。例如,TLB击落处理程序为FLUSH_TLB_FUNC()(由CAL的中断处理程序调用)。在其他情况下,我们需要进一步查看调用堆栈,以找出中断中正在执行哪些工作。例如,CAL中断可以调用许多不同函数中的一个。
使用trace-cmd录制时,使用“trace-cmd show”查看输出。使用“trace-cmd report”查看trace-cmd记录完成后保存的输出。
要查看内核上中断处理程序的成本,我们可以使用trace-cmd,如下所示。
从上面的输出中我们可以看到,每秒钟我们得到7个上下文切换,其中6个用于TLB击落IPI处理程序,占用了关键RX线程大约30-35微秒的时间。注意:TLB IPI是CAL IPI的一种形式,因此它的处理程序从SMP_CALL_Function_INTERRUPT()开始。
在仅执行一个线程的隔离NOHZ_FULL内核上LOC-1/秒的情况下的时间段。
在I/O中断的情况下的I/O请求-由于不平衡,我们应该看不到这些。
在IPI情况下引发中断的CPU+内核函数查找中断向量的符号,并通过调用send_ipi_*函数找到引发中断的函数。
从上面的输出可以看出,munmap(2)的系统调用负责TLB击落中断。
步骤3-调试代码以找出负责中断的线程或任务正在做什么。
从上面的输出中,获取Mellanox NIC统计信息的DPDK调用(使用FILE*操作)负责TLB击落中断!
从上面的调试输出中,我们发现fclose(3)在读取NIC的Out_Of_Buffer计数器(MLX5PMD的imiss计数器)时调用了munmap(2)。零星发生的数据包丢弃是由于读取数据包丢弃计数器造成的。使情况更加复杂的是,这些液滴是由另一个名为rx_discards_phy的计数器计数的。就像薛定谔著名的思维实验一样,这些液滴直到读到液滴计数器后才出现。
fscanf(3)调用导致文件被mmap‘化。随后的fclose(3)导致调用munmap(2),通过对调用fclose(3)的内核执行TLB刷新操作,从TLB释放与文件缓冲区的物理地址相关联的线性地址。这还会将TLB击落发送到执行同一进程的所有线程(包括关键RX线程)的所有内核。修复方法是用open(2)/read(2)/close(2)调用替换文件流操作。向DPDK和Mellanox报告了该错误及其修复,并接受了该补丁。
避免调用上述任何系统调用的C库函数,或者找出解决办法以继续使用这些C库调用。例如,File*C库调用可以与使用setvbuf(3)设置的用户缓冲区一起使用。
TLB击落的影响随着内核和插槽数量的增加而增加,因为击落的启动器内核必须等待它向其发送IPI的所有内核的确认。我们注意到,由于TLB击落双插槽机器导致的丢包率较低,该机器的内核数量是本文所述设置的一半。
“谁照看着看守人?”注意您的度量工具和代码会给关键线程带来更多的中断和抖动。例如,trace-cmd和perf等工具本身使用IPI进行跟踪和测量。