在Apache Pinot中创建全文搜索引擎
Apache Pinot是一个实时分布式OLAP数据存储,旨在以低延迟提供可扩展的实时分析。
Pinot通过其在非BLOB列上的索引支持超快的查询处理。具有精确匹配过滤器的查询通过字典编码、倒排索引和排序索引的组合高效运行。但是,任意文本搜索查询不能利用索引,需要全表扫描。
在这篇文章中,我们将讨论在Pinot中新增的对文本索引的支持,以及如何将它们用于高效的全文搜索查询。
在上面的查询中,我们对没有索引的FirstName列进行精确匹配。执行引擎将查找匹配的docID(也称为rowId),如下所示:
如果FirstName列上有倒排索引,则将使用dictionaryId查找倒排索引,而不是扫描正向索引。
如果表按FirstName列排序,我们将使用dictionaryId查找排序后的索引,并获得值为“John”的所有行的开始和结束docID。
下图显示了在具有5亿行和选择性(通过筛选器的行数)1.5亿行的数据集上使用和不使用索引的精确匹配查询的延迟。
如果用户对进行任意文本搜索感兴趣怎么办?目前,Pinot通过内置函数REGEXP_LIKE支持此功能。
谓词是正则表达式(前缀查询)。与精确匹配不同,索引不能用于评估正则表达式过滤器,我们求助于全表扫描。对于每个原始值,使用正则表达式“John*”进行模式匹配,以查找匹配的docID。
对于落入BLOB/CLOB范围的任意文本数据,我们需要的不仅仅是精确匹配。用户对对类似BLOB的数据进行正则表达式、短语和模糊查询很感兴趣。正如我们刚才看到的,REGEXP_LIKE效率非常低,因为它使用全表扫描。其次,它不支持模糊搜索。
在Pinot 0.3.0中,我们添加了对文本索引的支持,以便在字符串列上高效地执行任意文本搜索,其中每个列值都是一个异构文本的BLOB。执行标准的过滤操作(相等、范围、介于、in)不适合文本数据。
在支持文本索引的情况下,让我们比较一下有索引和没有索引的文本搜索查询在5亿行和1.5亿筛选选择性的数据集上的性能。
与其他数据库索引一样,文本索引的目标是进行高效的过滤处理以提高查询性能。
为了有效地支持正则表达式、短语和模糊搜索,文本索引数据结构应该具有较少的基本构建块来存储关键信息。
字典将每个索引项(词)映射到相应的字典ID,以允许使用固定宽度的整数代码与原始值进行有效比较。
倒排索引将每个索引项的dictionaryId映射到相应的docID。精确匹配词查询(单个或多个词)可以通过字典和倒排索引高效地回答。
短语查询(例如查找与短语“机器学习”匹配的文档)是精确术语查询的扩展,其中术语在匹配文档中的顺序应该完全相同。这些查询需要位置信息以及字典和倒排索引。
正则表达式查询(包括前缀、通配符)和模糊查询将需要与字典中的每个术语进行比较,除非前缀是固定的。必须有一种方法来修剪这种比较。
如果我们可以将输入正则表达式表示为有限状态机,使得状态机是确定性的并接受一组术语,那么我们可以将状态机与字典结合使用,以获得状态机接受的所有匹配术语的字典ID。
模糊编辑距离搜索也可以通过将查询表示为基于Levenshtein自动机的状态机并将自动机与字典相交来有效地完成。
如前所述,Pinot的字典和倒排索引可以帮助高效地回答精确匹配术语查询。然而,短语、正则表达式、通配符、前缀和模糊查询需要位置信息和有限状态自动机,这是目前Pinot中没有维护的。
我们了解到Apache Lucene有必要的缺失部分,并决定使用它来支持Pinot中的全文搜索,直到我们增强我们的索引结构。
让我们讨论在Pinot中创建Lucene文本索引作为一系列关键设计决策和挑战。
皮诺的表格存储格式是柱状的。表的索引结构(正向、倒排、排序、字典)也是在每个列、每个段(碎片)的基础上创建的。对于文本索引,我们决定坚持这种基本设计,原因如下:
进化和维护更容易。用户可以自由启用或禁用表的每一列上的文本索引。
我们的性能实验表明,在Lucene中跨表的所有启用文本索引的列创建全局索引会影响性能。全局索引大于每列索引,这会增加搜索时间。
与其他索引一样,文本索引是作为创建皮诺片段的一部分创建的。对于表中的每一行,我们获取启用了文本索引的列的值,并将其封装在文档中。
文本字段-包含表示应编制索引的文本正文的实际列值(DocValue)。
存储字段-包含一个单调递增的docId计数器,将Lucene中索引的每个文档反向映射回其在Pinot中的docID(RowId)。此字段未标记化并编制索引。它只是存储在Lucene中。
存储的字段非常重要。对于添加到文本索引的每个文档,Lucene会为该文档分配一个单调递增的docID。稍后,索引上的搜索操作将返回匹配的docID列表。
Lucene索引由多个独立的子索引组成,称为段(不要与Pinot段混淆)。每个Lucene子索引都是一个独立的、自包含的索引。根据索引的数据大小、将索引中的内存文档刷新到磁盘表示形式的频率,单个文本索引可以由多个子索引组成。
这里需要注意的关键一点是,Lucene的内部docID是相对于每个子索引的。这可能会导致添加到Pinot表中给定行的文本索引的文档与Pinot docID不具有相同的Lucene docID。
对于具有文本搜索筛选器的查询,这将导致不正确的结果,因为我们的执行引擎(筛选器处理、索引查找等)是基于docID的。因此,我们需要将添加到Lucene索引的每个文档与相应的Pinot docID唯一关联。这就是为什么将StoredField用作文档中的第二个字段。
纯文本用作索引生成的输入。分析器对提供的输入文本执行预处理步骤。
我们目前使用的StandardAnalyzer对于标准的英文字母数字文本已经足够好了,并且使用Unicode文本分割算法将文本分割成记号。在搜索文本索引时,也会在查询执行期间使用Analyzer。
皮诺支持实时摄取和查询数据。支持离线、实时和混合Pinot表的文本索引。
IndexWriter用于创建文本索引。它在内存中缓冲文档,并定期将它们刷新到磁盘上的Lucene索引目录。但是,在写入器提交并关闭fsync索引目录的索引并使索引数据对读取器可用之前,IndexReader(在搜索查询路径上使用)看不到数据。
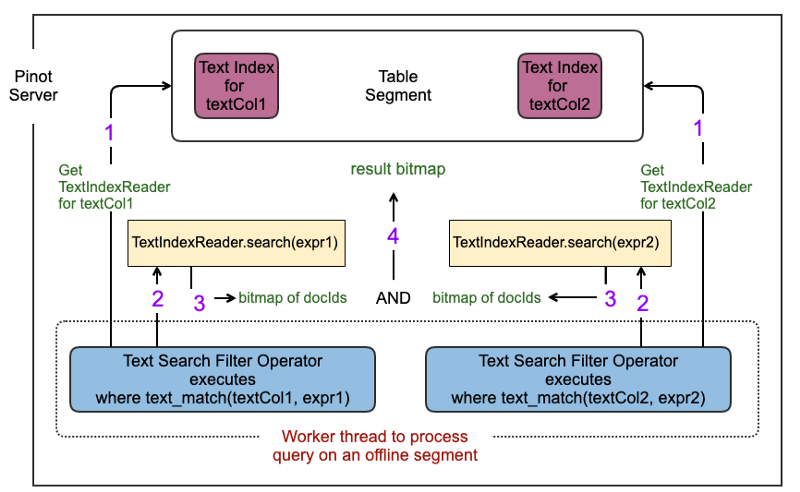
IndexReader始终查看从索引目录打开读取器时索引的时间点快照(已提交数据)。这对于离线表很有效,因为离线Pinot段在完全创建之前不会为查询提供数据,并且一旦创建就是不可变的。文本索引是在Pinot段生成期间创建的,并且在段完全构建并在Pinot服务器上加载(内存映射)之后,准备为查询提供数据。因此,查询路径上的文本索引读取器始终查看离线表的段的全部数据。
但是,上述方法不适用于实时或混合Pinot表,因为在使用数据时可以查询这些表。这需要能够搜索查询路径上的文本索引,因为IndexWriter正在处理未提交的更改。后续部分将详细讨论离线和实时的查询执行。
我们使用一个新的内置函数Text_Match()增强了查询解析器和执行引擎,该函数将用于查询的WHERE子句。语法为:
将查询日志和简历文本存储在Pinot表的两个字符串列中。
我们现在可以对查询日志和简历数据进行不同类型的文本分析:
从MyTable WHERE TEXT_MATCH(logCol,‘\“TIMECOL BETWEEN\”和\“GROUP BY\”’)中选择计数(*)。
统计拥有“机器学习”和“GPU处理”的考生人数。
从MyTable WHERE TEXT_MATCH(Resume,‘\“机器学习\”和\“GPU处理\”’)中选择计数(*)。
有关不同类型的文本搜索查询以及如何编写搜索表达式的详细指南,请参阅用户文档。
文本索引由IndexWriter在目录中创建,作为PINOT段生成的一部分。当Pinot服务器加载(内存映射)离线段时,我们创建一个IndexReader,它对文本索引目录进行内存映射。IndexReader和IndexSearcher的实例在每个具有文本索引的列的每个表段中创建一次。
我们选择使用MMapDirectory而不是RAMDirectory,因为前者使用高效的内存映射I/O,并且生成的垃圾更少。RAMDirectory对于内存驻留的小索引非常有效,但会显著增加堆开销。
在使用数据时,可以查询实时比诺片段中的文本索引。Lucene通过允许从实时写入器打开读取器来支持NRT(近乎实时)搜索,从而允许读取器查看来自写入器的所有未提交的索引数据。但是,就像Lucene中的任何其他索引读取器一样,NRT读取器也是快照读取器。因此,必须定期重新打开NRT读取器才能看到实时索引写入器所做的增量更改。
我们的实时文本索引读取器还充当写入器,因为它既将文档作为实时段消费的一部分添加到索引中,也被Pinot查询线程使用。
在Pinot服务器启动期间,我们创建单个后台线程。该线程跨所有表维护实时段的全局循环队列。
线程在可配置阈值之后醒来,轮询队列以获得实时段,并为具有文本索引的每一列刷新实时读取器的索引搜索器。
决定后台线程连续刷新之间的可配置阈值应该根据需求进行调整。
如果阈值较低,我们将经常刷新,并且使用TEXT_MATCH过滤器对使用段的查询将快速看到新行。缺点是大量的小I/O,因为刷新文本索引读取器需要实时写入器刷新。
如果阈值较高,我们刷新的频率就会降低,这会增加一行添加到消费片段的文本索引与使用TEXT_MATCH过滤器在查询的搜索结果中出现之间的延迟。
到目前为止,我们讨论了如何在Pinot中创建和查询文本索引。我们还谈到了一些设计决策和挑战。现在,让我们详细讨论为获得所需功能和性能而实现的优化。
对于搜索查询,Lucene的默认行为是进行评分和排名。调用indexSearcher.search()的结果是TopDocs,它表示按分数降序排序的查询的前N个命中。在皮诺,我们目前不需要任何评分和排名功能。我们只对检索给定文本搜索查询的所有匹配docID感兴趣。
我们最初的实验显示,Lucene中的默认搜索代码路径会导致很大的堆开销,因为它使用TopScoreDocCollector中的PriorityQuery。其次,堆开销随着匹配文档数量的增加而增加。
我们实现了Collector接口以提供对indexSearcher.search(查询、收集器)操作的简单回调。对于每个匹配的Lucene docID,Lucene都会调用我们的收集器回调,该回调将docID存储在位图中。
文本文档很可能有常见的英语单词,如a、an、the等。这些词称为停用词。停用词通常不会在文本分析中使用,但由于它们的出现频率很高,索引大小可能会爆炸,从而影响查询性能。我们可以自定义分析器,为输入文本创建自定义令牌筛选器。分析器中的过滤过程在建立索引时删除所有停止字。
如上所述,强烈需要在添加到Lucene索引的每个文档中存储Pinot docID。这将导致两遍查询执行:
迭代每个docID以获得相应的文档。从文档中检索Pinot docID。
从Lucene检索整个文档非常耗费CPU,并且成为吞吐量测试的主要瓶颈。为了避免这种情况,我们迭代文本索引一次,以获取所有<;Lucene docID、Pinot docID>;映射,并将它们写入内存映射文件中。
因为离线段的文本索引是不可变的,所以这很有效,因为当服务器加载文本索引时,我们只需支付一次检索整个文档的成本。稍后,在查询执行期间,收集器回调将使用映射文件来缩短搜索路径,并直接构造Pinot docIds的结果位图。
通过允许延迟随QPS的增加而扩展,这种优化与修剪停用字一起使我们的查询性能提高了40-50倍。下图比较了此优化前后的延迟。
Lucene有一个缓存,可以使用可重复的文本搜索表达式提高查询性能。虽然性能提升非常明显,但缓存会增加堆开销。我们决定在默认情况下禁用它,并让用户在每个文本索引的基础上启用(如果需要)。
Lucene的磁盘索引结构存储在多个文件中。考虑Pinot服务器上2000个表段的情况,每个Pinot表段在3列上具有文本索引,每个文本索引具有10个文件。我们看到的是60k打开的文件句柄。系统很可能会遇到“打开的文件太多”的问题。
因此,IndexWriter使用复合文件格式。其次,当为列完全构建文本索引时,我们强制将多个Lucene子索引(在Lucene术语中也称为段)合并到单个索引中。
当文档在Pinot段生成期间添加到文本索引时,它们会在内存中缓冲,并定期刷新到索引目录的磁盘结构中。默认的Lucene行为是在内存使用量达到16MB后刷新。我们对该值进行了实验,并进行了一些观察:
刷新会导致Lucene段。随着更多的这些被创建,Lucene可以决定在后台合并它们中的几个/全部。具有多个这样的段会增加文件的数量。
将默认阈值设为16MB并不意味着索引编写器在刷新之前将消耗16MB的堆。实际消耗要高得多(大约100MB),这可能是因为在Java中没有以编程方式跟踪使用的堆内存量的好方法。
较小的阈值会导致大量的小型I/O,而不是较少的大型I/O。我们决定保持此值可配置,并选择256MB作为默认值,以保持内存开销和I/O数量之间的良好平衡。
我们还运行了微基准测试,以比较Pinot表和包含100万行的单个段上TEXT_MATCH和regexp_LIKE的执行时间。使用了两种不同类型的测试数据:
日志数据:Pinot表中的字符串列,其中每个值都是来自Apache Access日志的一个日志行。
非日志数据:Pinot表中的字符串列,其中每个值都是简历文本。
下图显示,与基于扫描的模式匹配相比,使用文本索引的搜索查询速度要快得多。
另一个评估是使用Pinot的原生倒排索引,以了解使用文本索引可能不是正确的解决方案。
如果只需要精确的术语匹配(使用=、IN运算符),则文本索引不是正确的解决方案。皮诺的倒排索引可以比Lucene快5倍的速度进行精确的术语匹配。
但是,如果需要短语、正则表达式(包括前缀和通配符)或模糊搜索,则文本索引在功能和性能方面都是正确的选择。
预先构建的Lucene docID到pinot docID的映射适用于离线段,因为文本索引是不可变的。对于实时消费的细分市场,这种优化是不适用的,因为索引在服务查询时会发生变化。优化Lucene docID到Pinot docID的转换正在进行中。
微调后台刷新线程,以在每个表或每个索引的基础上工作。当前实现具有单个后台线程来管理所有实时段及其文本索引。
在这篇博客中,我们讨论了如何利用Lucene在Pinot中设计文本搜索解决方案,以满足我们的功能和性能(QPS和延迟)要求。请访问文本搜索的用户文档,了解有关使用该功能的更多信息。
如果您有兴趣了解更多关于皮诺的信息,请加入我们的松弛频道并订阅我们的邮件列表,成为我们开源社区的一员。
最后,以下是您在开始Apache Pinot之旅时可能会发现有用的资源列表。
我们要感谢皮诺团队的所有成员,感谢他们为使皮诺变得更好所做的不懈努力:Mayank Shriastava,Jackie酱,Li佳亮,Kishore Gopalakrishna,Neha Pawar,Seunghyun Lee,Subbu Subramaniam,Sajad Moradi,Dino Occhialini,Anurag Shendge,Walter Huf,John Gutmann,我们的工程经理Shraddha Sahay和SRE经理Prasanna。
我们还要感谢LinkedIn领导层Eric Baldeschwieler、Kapil Surlaker和Igor Perisic的指导和持续支持。