Xbox架构
看起来微软已经决定从世嘉停止的地方继续。他们的出价呢?熟悉的系统受到开发者的赞赏,在线服务受到用户的欢迎。
请注意,由于与其他来源的一致性,本文在公制前缀(即兆字节或‘MB’)和标准化的二进制前缀(即兆字节或‘MIB’)之间分隔存储单元,因此:
此控制台中包含的处理器是著名的Intel Pentium III(用于计算机的现成CPU)的略微定制版本,运行速度为733 MHz。有了这一点,人们可以假设这台主机只是一台幕后的PC&;mldr我不会告诉您答案,但我保证在本文结束时,您将能够得出您自己的结论。
无论如何,奔腾和英特尔设计和制造的其他系列CPU在计算机市场上都非常受欢迎。英特尔的市场占有率如此之高,以至于他们成为了事实上的质量参照点:作为一个典型的用户,如果你想要一台好的电脑,而且有足够的预算,你只需寻找搭载英特尔CPU的产品。到目前为止,我们都知道涉及的因素更多,但这是英特尔的营销人员设法预测的。
现在我们在地图中定位了Intel,让我们回到此控制台的主题。在我的研究过程中,我希望能找到与其他CPU(MIPS、Superh、ARM等)一样深度的文档,但是,我无意中发现了过多的营销术语,这些术语只会转移我的搜索方向。因此,在本文中,我想出了一个结构来组织所有必要的信息,这将有助于理解该CPU的工作原理。此外,我将尝试介绍英特尔用来为这款CPU打品牌的一些术语。
首先,Xbox的CPU被认定为奔腾III。那么这意味着什么呢?当时(00年代初),奔腾系列代表了下一代CPU。它们是“新的高端产品”,集合了所有让计算机速度超快的奇特技术,此外,它还帮助买家决定如果他们想要最好的CPU,他们必须购买哪种CPU。
奔腾III取代了奔腾II,奔腾II又取代了最初的奔腾。此外,当第一台奔腾问世时,它取代了80486,而80486又取代了80386&&mldr,你明白了吧。重要的是,“奔腾”主要是一个品牌名称,它与它的内部运作没有直接联系。因此,我们必须走得更深一些!
为了更深入,不会在路上迷路,我将信息分类成三个部分,这三个部分结合在一起,组成了芯片。第一个是指令集体系结构或“ISA”(用于命令CPU的指令组)、微体系结构(ISA是如何在硅中实现的)和核心(使用什么组件集来打包微体系结构以形成特定的CPU模型)。
事实上,在我提到Intel这个名字之后,我介绍著名的x86指令集只是个时间问题。
尽管x86在1978年随名为Intel8086的16位CPU的发布而首次出现,但随着更多的IntelCPU(80186、80286等等)的发布,指令集也在不断地扩展。因此,随着更多突破性功能的添加(即“实模式”、“保护模式”和“长模式”),x86开始碎片化。为了解决这个问题,现代x86应用程序通常将80386 ISA(也称为IA-32或i386)作为基准,其中包括在32位环境中运行。
随后,英特尔以扩展的形式展示了IA-32的增强功能,这意味着IA-32 CPU可能包含这些功能,也可能不包含这些功能。程序可以查询CPU以检查是否存在特定的增强功能。Xbox的CPU包括两个扩展:
MMX(多媒体扩展):添加57条SIMD指令和8个64位寄存器(仅限整数),可加快矢量运算。
SSE(SIMD流扩展):另一个SIMD类型的扩展,它解决了MMX的一些限制(缺乏浮点支持,不能并行使用浮点单元)。它增加了8个128位寄存器(称为“XMM”),这些寄存器包含4个32位浮点数;以及56条新指令。
好消息是,由于控制台将始终具有相同的CPU功能,程序员可以优化他们的代码来利用这些扩展,因为它们将始终存在。
当谈到构建能够解释x86指令的电路时,英特尔已经为他们的CPU设计了如此多不同的设计。一些设计在新奔腾系列(即奔腾4)的发布中亮相,而另一些设计则在英特尔发布奔腾“增强”版本(如“奔腾Pro”)时亮相。尽管如此,自从第一代奔腾发布以来,微体系结构的名称与CPU模型不同。例如,最初的奔腾包括“P5”微体系结构。
现在,Xbox CPU和其他奔腾III处理器一起使用P6微体系结构(也称为“i686”)。这是第6代(从8086开始计算),其特点是:
无序执行:如果可能,CPU会重新排序指令序列,以提高效率和性能。
推测性预测:类似于分支预测,但它还执行CPU预测它将被选择的分支。
话虽如此,还是仔细看看这些功能吧。巧合的是,它们与以前的游戏机非常相似,然而,其他CPU在设计方面与英特尔的CPU有很大的不同。从历史上看,人们可能会争辩说,英特尔永远不可能实现,比方说,流水线CPU。然而,他们还是做到了,所以让我们来看看为什么&;mldr。
之前分析的所有竞争对手的游戏机都包含RISC CPU,而英特尔的x86游戏机是CISC。众所周知,与CISC CPU相比,RISC CPU具有简化的指令集。例如,这包括不具有直接从存储器(与寄存器相反)运算值的指令。
RISC处理器的优势之一是其简单的方法使其CPU可以设计成模块化的,这反过来又可以利用并行技术来提高性能。这就是为什么我们看到像MIPS和PowerPC这样的CPU在流水线、超标量、无序、分支预测等方面首次亮相。另一方面,“CISC”处理器是在RISC处理器出现之前多年设计的,旨在解决不同的需求。因此,它们的设计不如RISC的灵活。
回到最初的问题,P6是一个有趣的设计,因为虽然CPU只理解CISC指令集(X86),但它使用微码(称为“微操作”)解释ISA,并且执行该代码的单元是根据RISC的准则构建的。总而言之,这使得英特尔可以应用RISC处理器的优化,同时保留与x86兼容的“CISC层”。
微码已经嵌入到硅中,但它可以打补丁,只要发现错误或安全漏洞,英特尔就可以在生产后修复其CPU。如果您阅读过以前的文章(即N64或PS2),请记住英特尔的微码不能公开访问(更不用说记录在案),英特尔是其唯一的“维护者”。
使用P6微体系结构发布了大量芯片。具体地说,Xbox包括一种名为铜矿的型号。这也是作为奔腾III的第二个修订版发布的(取代了‘Katmai’内核),包括以下组件:
32 KiB一级缓存:分为用于指令的16 KiB和用于数据的16 KiB。
集成128 KiB二级缓存:这很奇怪,因为现成的铜矿具有256 KiB的L2。事实上,Coppermine128(英特尔“赛扬”品牌,低端奔腾的替代品)也有相同数量的L2。这样做可能是为了降低制造成本,并使这款游戏机保持在一个有竞争力的价格。
133 MHz前端总线:这是连接二级缓存和内存控制器的总线,我们稍后会看到更多相关内容。英特尔将其命名为“前端总线”,以区别于连接L2(外部高速缓存)和L1(内部高速缓存)的另一条总线。后一种公交车被称为“Back-side bus”,是的,&;mldr,这是一个来自英国的不恰当的名字。
在最初实现的二级缓存的基础上,Coppermine还具有两个“增强功能”,即高级传输缓存和高级系统缓冲。总而言之,L2高速缓存是片上的,它们的总线更宽,这有助于减少前端总线中可能存在的瓶颈。
最后,该芯片使用“Micro-PGA2”插座将其连接到主板,但与任何其他控制台一样,Xbox将其与球栅阵列(BGA)焊接在一起。
这里有一个更多的历史:在P6问世几年后,英特尔计划用“NetBurst”微体系结构(奔腾IV中的特色)来接替它。然而,继承线也到此为止:微体系结构不能再改进了。这促使以色列的一个英特尔团队重新审视旧的P6,并开发出更高效的继任者。结果是奔腾M,最终扩展形成了核心微体系结构(和品牌)。“核心”是目前设计的基础。
在个人电脑历史上的某个时刻,主板变得如此复杂,以至于必须从头开始开发新的设计,以有效地满足新出现的需求。
开发的新标准依赖于两个专用芯片来处理大部分主板功能。这些芯片是:
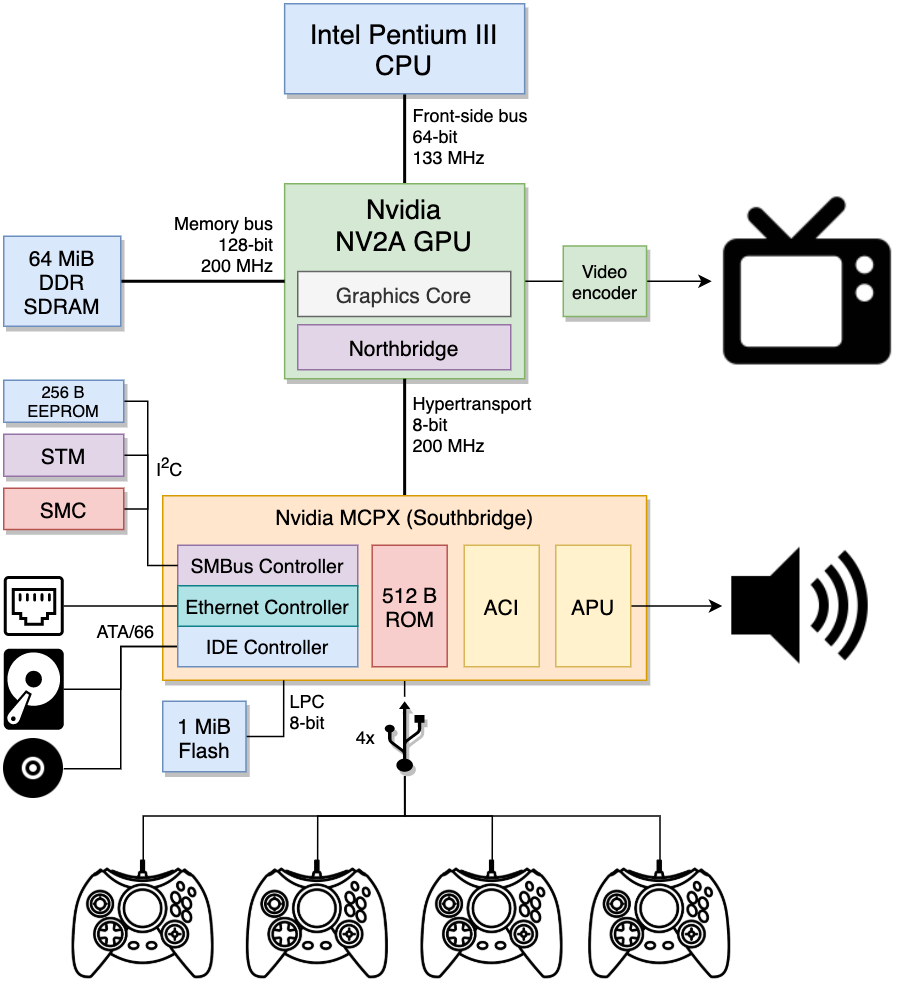
这些芯片的组合被称为芯片组,它们对于调节主板的功能和性能非常重要。Xbox离个人电脑如此之近,还包括两个芯片:NV2A,北桥和GPU的组合;以及MCPX,处理其余的I/O。
这两个芯片使用称为HyperTransport的专用总线互连。值得一提的是,一些PC主板也包含此技术,只是品牌不同(即MPCX→nForce MCP-D)。
Xbox总共包括64 MiB的DDR SRAM,与竞争对手提供的相比,这种类型的RAM速度非常快,但是它也可以在此系统的所有组件之间共享。因此,我们再次发现自己处于另一个统一内存架构或“UMA”布局的前面。
我们以前已经看到这种设计有时会有多麻烦。尽管如此,程序可以通过将其数据分布在不同的内存库中来解决这个问题。NV2A实现了一个交换网络,使不同的单元(CPU、GPU等)能够同时访问它们。
此外,控制台有一个内置硬盘,因此恰好有三个750MiB的分区保留用于临时存储:CPU可以从主RAM卸载一些数据,然后在需要的时候上传回来。请记住,这是一个手动过程,不涉及虚拟RAM。
正如我们以前看到的,图形处理器驻留在NV2A芯片中,就像MCPX一样,它是由NVIDIA制造的。
这家公司从事图形业务已有很长时间,他们的GeForce系列是计算机市场上最受欢迎的GPU品牌之一,与Artx/ATI的RADEON系列直接竞争。总体而言,考虑到这是微软在游戏机市场的首次尝试,这对Xbox中的图形质量提供了很好的杠杆作用。
现在,恐怕我们发现自己被很多术语和营销术语混杂在一起,就像CPU部分一样,但不要害怕!我将从基础知识开始。
NV2A上的GPU内核基于流行的“GeForce3”系列GPU,在NVIDIA的技术文档中也称为NV20。
请注意,虽然Xbox的GPU流水线基于NV20架构,但NV2A有一些修改与NV20系列的其他产品不兼容(最重要的是,它已被调整为在UMA环境下工作)。
所分析的单元包含更多超出本文范围的特性,因此如果这一节引起您的注意,我建议您查看源代码/参考资料。此外,由于与图形相关的术语不断演变(这可能会导致一些混淆),我决定使用Microsoft/Nvidia在Xbox时代选择的术语,所以如果您计划阅读其他来源的更多与图形相关的文章,请记住这一点。
话虽如此,让我们来看看框架是如何在Xbox中绘制的。有些解释与Gamecube的Flipper非常相似,所以我建议您先阅读那篇文章,以防您很难理解这篇文章。
首先也是最重要的是解释GPU如何接收来自CPU的命令。为此,GPU包含一个称为PFIFO的命令处理器,它以FIFO方式有效地获取和处理图形命令(称为Pushbuffer),解包后的命令随后被传送到PGRAPH(负责图形处理的块)和其他引擎。
与Flipper一样,几何体不必嵌入到命令中。PGRAPH提供了许多提交图形数据的方法。例如,CPU可以在RAM中分配包含顶点数据的缓冲区,然后指示GPU从该位置获取它们。此方法非常有效,因为它避免了必须嵌入重复的几何体。
对于这个GPU来说,这是一个特别有趣的部分。在此阶段,GPU提供了在几何体上应用顶点变换的功能。我们已经在Flipper上看到了这一功能,但与GPU不同的是,这一款使用了可编程引擎。这意味着开发者可以指定执行哪些顶点操作以及如何执行,而不是依赖于预定义的程序(尽管NV2A也可以在“固定”模式下操作)。
这一阶段由一个顶点单元处理,而NV2A具有其中的两个单元。每个都可以加载包含多达136条指令(也称为微码)的程序。这个程序被称为顶点程序,它在运行时加载。顶点程序可以执行以下操作:
简而言之,顶点单元通过在其寄存器中操作顶点来处理顶点。换句话说,一旦加载了程序,16个只读寄存器(称为“输入寄存器”)将用顶点的属性(每个向量包含四个分量)进行初始化。然后,该单元使用输入寄存器执行该组操作(由程序指示)。此外,还提供了12个可写寄存器和多达196个常量来协助计算。最后,将得到的顶点存储在另一个由11个可写寄存器组成的块中(每个寄存器仅限于特定用途),并将其传递到下一级。对接收到的每个顶点重复此过程。
在此阶段,顶点将转换为像素。该过程从一个光栅化器开始,该光栅化器生成像素来绘制每个三角形。NV2A的光栅化器每个周期可以产生4个像素。
然后,使用4个纹理着色器从内存中提取纹理,这些着色器还提供自动应用各向异性过滤、mipmap和阴影缓冲的功能。后者用于测试像素相对于光源是否可见或遮挡,因此可以应用正确的颜色。在这一点上,GPU还提供执行裁剪和早期Z测试(NV2A将Z缓冲区压缩为其原始大小的四倍,以节省带宽,从而大大提高了性能)。
得到的像素存储在一组共享寄存器中,然后循环通过8个寄存器组合器,每个组合器对其进行算术运算。使用像素着色器(另一种类型的程序)可以对此过程进行编程。在每个周期,每个组合器从寄存器组接收RGBA值(RGB+Alpha)。然后,根据着色器设置的操作,它将运算值并写回结果。最后,更大量的值被发送到最终组合器,该组合器可以独占地混合镜面反射颜色和/或雾。
寄存器组合器是可编程的,性质与纹理环境单元类似。也就是说,通过用特定的设置组合改变其寄存器。对于Xbox,PFIFO读取推送缓冲区以设置PGRAPH,其中包括寄存器组合器和纹理着色器。
在像素写入帧缓冲器之前,NV2A包含四个称为光栅输出单元或“ROP”的专用引擎,它们使用主内存中分配的块执行必要的测试(阿尔法、深度和模板)。最后,批次像素(每个周期4个)只有在通过这些测试时才会被写回。
此外,可以使用一种称为多重采样的技术对帧缓冲区进行抗锯齿处理。本质上,该技术使用过程中添加的不同偏移对多边形的边进行多次采样。然后,对所有样本进行平均,形成抗锯齿图像。这种方法取代了以前NVIDIA GPU使用的名为“超级采样”的抗锯齿功能(更耗费资源)。
我发现有必要强调NVIDIA向开发人员提供的新的可编程性模型的重要性。几年前,大多数图形流水线都是由CPU计算的,留下GPU来加速光栅化操作。随着着色器(指像素着色器和顶点程序)的引入,程序员可以利用GPU的资源来加速流水线中的许多计算,从而减轻CPU的大量工作负担。
“着色器”的概念是皮克斯在1989年引入的,作为一种扩展Renderman的方法,Renderman是他们用于3D渲染的开创性软件。这是在3D图形主要由工业设备处理的时代,后来,我们看到某些游戏机是如何融入类似的原则的,但直到NVIDIA发布了他们的GeForce3系列,着色器才成为消费市场的标准。
多亏了顶点程序,GPU现在可以加速模型转换、光照计算和纹理坐标生成。后者对于合成高阶曲面是必不可少的。有了这一点,CPU可以专注于提供更好的物理、人工智能和场景管理。
在像素着色器的情况下,程序员可以通过多种方式操纵和混合纹理,以实现不同的效果,如多纹理、镜面反射贴图、凹凸贴图、环境贴图等。
多亏了这种方法,出现了一个新的编程概念,即通用GPU或“GPGPU”,它包括将原本由CPU独占完成的任务分配给GPU。因此,不仅GPU已经接管了大部分图形流水线,而且现在还可以作为专门计算(即物理计算)的高效协处理器。这是一个新的领域,随着GPU变得更加强大和灵活,NV2A已经能够实现这一点,这要归功于硬件功能(顶点和放大器像素着色器)和开发的专门API(OpenGL的“状态程序”)的结合。
我有一种感觉,着色器将在以后的文章中定期重新讨论。请记住,在这篇文章中,它们可能被认为有点“原始”,有些人可能会争辩说,与现在GPU提供的相比,像素着色器甚至不是“着色器”。
游戏的标准分辨率是640x480,这几乎是第六代的标准。虽然,这个限制只是一个数字:GPU可以绘制高达4096x4096的帧缓冲区,但这并不意味着硬件可以提供可接受的性能。另一方面,控制台允许全局更改屏幕设置,这可能有助于推广这些独特的功能(宽屏和高分辨率),而不是等待开发人员。
..



