一种原则性的GraphQL查询代价分析方法
为什么应该衡量GraphQL查询的成本,以及应该如何衡量。
这是发表在ESEC/FSE 2020上的研究论文“GraphQL查询成本分析的原则方法”的摘要。艾伦·查在埃里克·维特恩、纪尧姆·鲍达特、我、路易斯·曼德尔和吉姆·拉雷多的帮助下领导了这项工作。这些作者中的大多数都隶属于IBM Research或IBM的产品团队,这是IBM持续参与GraphQL的一部分。
实践状况:WebAPI的格局正在发展,以满足新的客户需求,并促进提供商如何实现这些需求。最新的web API模型是GraphQL,客户端查询通过它来表达它们想要检索或更改的数据,而服务器正好用这些数据或更改进行响应。GraphQL减少了网络往返,并消除了不需要的数据传输。
有什么问题吗?GraphQL的表现力对服务提供商来说是有风险的。GraphQL客户端可以简明扼要地请求大量数据,响应这些查询可能代价高昂或中断服务可用性。最近的实证研究表明,许多服务提供商都面临风险。实践者缺乏一种原则性的方法来估计和衡量他们收到的GraphQL查询的成本。
我们做了什么?我们的静态GraphQL查询分析在不执行查询的情况下测量查询的复杂性。根据我们对GraphQL语义的形式化规范,我们的分析可以证明是正确的。与现有的静态方法相比,我们的分析支持影响查询复杂性的常见GraphQL约定。因为我们的方法是静态的,所以它可以应用于单独的API管理层,并与任意GraphQL后端一起使用。
我们的分析有效吗?我们使用一个新的GraphQL查询-响应语料库为两个商业GraphQL API演示了我们的方法。我们的查询分析始终获得复杂度上限,相对于服务提供商可操作的真实响应大小足够紧凑。相比之下,现有的静态GraphQL查询分析表现出高估和低估,因为它们不支持GraphQL约定。
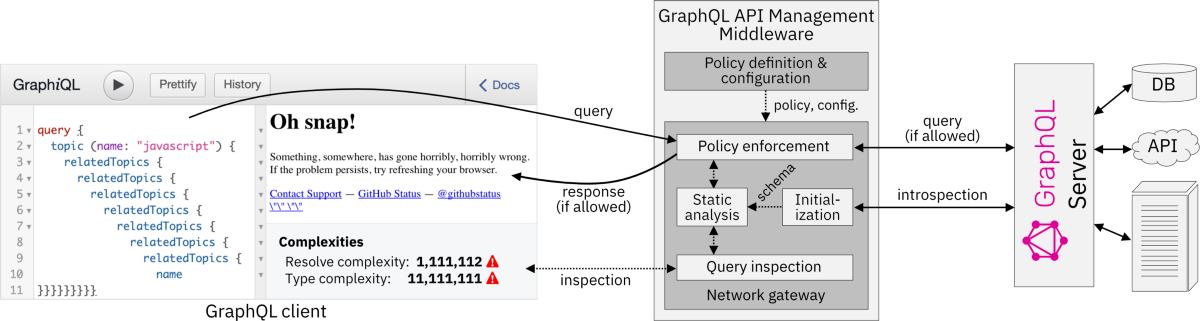
这在实践中会是什么样子呢?第一个图(上图)显示了我们的愿景。我们的成本分析可以应用于客户端和服务器端。它可以引导客户远离意外昂贵的查询。对于中间件/服务器,它可用于检测和响应可能代价高昂的查询。
如果你不熟悉GraphQL,可以看看我之前的帖子和里面的参考资料。网上还有很多其他的教程。
之前的两个实证研究描述了对GraphQL模式的分析,以了解它们是否存在“GraphQL查询拒绝服务”的风险[1,2]。他们想知道用户是否可以发送一个小问题,然后得到一个真正的大响应。他们报告说,这对于大多数GraphQL模式都是可能的;超过80%的商业或大型开源模式允许输入长度为指数大小的响应,而且多项式大小的响应也很常见。
我们手动研究了APIs.guru列出的30个公共GraphQL API的文档。令人不安的是,这30个提供程序中有25个既不描述静态查询分析,也不描述动态查询分析,以管理访问和防止误用。一些GraphQLAPI已经将定制的查询和/或响应分析合并到他们的管理方法中(GitHub、Shopify、Yelp、Content和TravelGateX),但是这些方法都有缺点。详情见白皮书(2.2美元和6.4.3美元)。
测量查询的成本很容易-只需执行它!但是,如果查询代价很高,可能会适得其反。成本分析测量查询的成本,而不完全执行该查询。与大多数成本分析一样,GraphQL查询的成本分析有两种类型:动态和静态。
研究人员提出了一种动态分析[1,3],它在将在其上执行查询的数据图的上下文中考虑查询。通过轻量级查询解析,它遍历查询以确定所涉及的对象数量,而无需解析它们。这一成本衡量标准是准确的,但获得的成本很高。它会产生额外的运行时负载,并且可能需要工程成本来支持廉价的对象计数查询[3]。
实践者已经提出了静态分析[4,5,6],其计算假设病态数据图(即将产生最大可能响应的图)的查询的最坏情况响应大小。因为静态分析做了最坏的假设,所以它可以有效地提供查询复杂性的上限,而无需与后端交互。静态查询分析的速度和通用性使其成为商业GraphQL API提供商的一种有吸引力的方法。
我们的静态方法遵循与现有静态分析类似的范例。我们在几个方面不同。最值得注意的是:
我们的分析建立在形式化的GraphQL语义上,并证明了我们的查询复杂度估计的正确性。
因为我们的目标是证明我们分析的正确性,所以这一节有点数学化。我试着捕捉高层次的想法,把数学问题留给论文去做。
GraphQL类似于SQL,但在我看来,它使数据之间的关系更加清晰。我将使用(内联)表示法来指出SQL类比。
GraphQL数据图(数据库实例)表示服务提供者已知的底层数据和关系。
GraphQL架构(数据库架构)定义了客户端可以查询的数据类型,以及可能对该数据执行的操作。
GraphQL查询(数据库查询)请求满足特定标准的数据子集,根据数据图中存在的关系进行组织。
对GraphQL查询的评估可以被认为是将连续的过滤器应用于最初对应于完整数据图的虚拟数据对象。这些过滤器由查询定义,并按照查询的结构递归应用(请参见本文中的图3)。使用解析器函数将数据图映射到后端存储,解析器函数解析模式中每种类型的每个字段的实体。
GraphQL响应由匹配查询的实体组成,根据查询的过滤器进行分类和组织。
GraphQL查询描述了响应数据的结构,还规定了必须调用才能满足它的解析器函数(哪个解析器,以什么顺序,多少次)。我们提出了两个查询成本定义:
类型复杂性表示响应的大小,由响应中的字段数衡量。您可以简单地计算每个条目,也可以根据表示它们的成本(例如,对每种类型的字段进行编码所需的字节数,如最大字符串长度或最大整数宽度)对这些条目进行加权。这一成本由每个人支付-服务提供商(生成和编组它)、网络运营商(发货它)和客户端(解组和处理它)。
响应复杂性表示GraphQL服务提供商生成响应的成本。如果提供商的最大成本是通过网络传输数据,那么类型复杂性可能就足够了。但是提供程序的计算成本也可能取决于调用哪些解析器函数以及每个解析器函数调用多少次。例如,也许某些解析器可以通过缓存来解析,其他解析器可以通过访问冷存储来解析,还有一些解析器可以通过第三方的API组合获得。GraphQL的后端不可知性可能会导致提供商在每个解析器的基础上产生不同的成本。我们对响应复杂性的概念包含了这些成本。
在我们的形式化下,这两个成本都可以使用加权递归和来计算,这类似于Facebook对GraphQL的定义。但是这个定义没有说明如何处理列表。如果我们简单地假设所有列表都是无限长的(或者包含底层数据图中该类型的所有条目),我们将不会得到非常有用的成本估计。令人高兴的是,社区遵循两个分页约定,因为返回无限长的列表对任何人都没有帮助。
我们考虑两个常见的分页约定:切片模式和连接模式。切片使用限制参数来限制返回列表的大小。Connections引入了间接层以实现更灵活的分页,并将限制参数应用于游标而不是列表本身。这些概念如下图所示。
我们根据查询的类型复杂性和响应复杂性来衡量查询的潜在成本。我们的分析实质上是加权的递归和,列表大小受到通过切片和连接模式规定的限制参数的限制。
因为我们的方法依赖于约定,所以模式必须伴随着解释它如何遵循这些约定的配置。此配置完成三件事:
它标记包含限制的字段以及应用这些限制的子字段(用于连接模式)。
它在限制字段未提供参数的情况下提供默认限制。
它可选地提供权重,以指示每种类型和每个解析器函数的成本。默认情况下,权重1可能比较合理。
在给定模式和配置的情况下,我们的分析总是根据查询的类型复杂性和响应复杂性得出查询成本的上限。此保证假设返回列表的所有字段都强制执行其限制参数,并且具有有限的默认限制。这些是上限,因为我们假设底层图是病态的-查询中请求的每个列表都将被完全填充。
时代周刊:我们的分析是以广度优先的方式“由外而内”进行的。它访问查询的每个节点一次,因为查询的内层不能增加响应外层的节点数。因此,它在时间上与查询的大小呈线性关系运行。
空间:必须携带递归查询的上下文,以便跟踪子字段的限制来处理连接模式。约定(和我们的实现)仅将这些限制应用于直接子代,空间开销不变。通常,空间复杂性与查询中的最大嵌套程度相匹配。
实现我们实现了此方法,但尚未说服IBM将其开源:-)。我们希望开源工具[4,5,6]能考虑纳入我们的想法。
我们的分析要求GraphQL模式伴随着限制参数、权重和默认限制的配置。
我们发现为这两种模式开发配置非常简单。由于GraphQL模式遵循命名约定[2],我们在配置语言中支持正则表达式来表示字段名,因此我们的配置比相应的模式小得多。
是!。我们开发了一个开源的GraphQL查询生成器[7],并为每个API生成了5000个查询-响应对。这里标出了预测的和实际的复杂性。我们保证上限,所以我们预测的成本总是在图中y=x线的上方。
这有点主观。我们的界限可能被高估了,但是使用静态的、数据不可知的方法,我们的界限是尽可能紧的。结果取决于底层数据图。
数据稀疏导致响应比其最坏情况下的潜在响应更简单。在上图中,我们的上限接近或等于实际类型,并解决了许多查询的复杂性-这可以从对角线附近的高密度查询中看出。对于更复杂的查询,我们的界限变得更加宽松。这遵循对底层图形的直觉:API的真实数据可能无法满足更大、更嵌套的查询。
是!。除了我们分析的功能正确性之外,我们还评估了它的运行时成本,看看它是否可以合并到现有的请求-响应流中,例如,在GraphQL客户端或API管理中间件中。
我们衡量了2017款MacBook Pro的价格(8核英特尔i7处理器,16 GB内存)。正如预测的那样,我们的分析以线性时间运行,是查询大小的函数。几乎所有查询都可以在5毫秒内完成分析。
开源我们将我们的方法与三个开源库的方法进行了比较[4,5,6]。下图汇总了结果。请注意,liba会过度高估,而libB和libC遵循相同的方法,容易被低估。
这些库的缺点可能与它们对GraphQL分页约定处理不当有关。有问题的是,这些库并不总是允许用户指定列表的长度,从而导致高估和低估。
利巴很容易高估。它只允许列表长度的全局最大值。由于这些API提供程序在默认长度(和支持限制参数)方面有很大的差异,因此产生的上限可能高估了很多。
libB和libC可能会低估。它们将未分页列表视为始终只返回一个元素。它们也不支持间接限制参数,因此不能处理连接模式。
我们考虑了GitHub和Yelp的静态分析,虽然它们不是开源的,但都有文档记录。
GitHub在我们研究的时候,GitHub分享了libB和libC的一个限制:它没有正确处理未分页列表的大小。第一张图使用未分页的relatedTopics字段说明了此问题。我们报告了这个问题,他们已经解决了。我们的分析仍然比他们修正后的分析更灵活。
Yelp Yelp遵循一个简单的规则:字段最多可以嵌套到四个级别。通过嵌套大列表仍然可以获得相对大的响应。我们更精确的分析与他们的分析具有相同的时间复杂性(两者都在单遍中处理查询)。
GraphQL是一种新兴的Web API模型。它的灵活性可以使客户端、服务器和网络运营商受益,但它的灵活性也是一种威胁:GraphQL查询可能非常复杂,对服务提供商的影响包括速率限制和拒绝服务。
对服务提供商的基本要求是一种廉价、准确的方式来估计查询成本。我们已经提出了一种原则性的、可以证明是正确的方法来应对这一挑战。通过正确的配置,我们的分析提供了严格的上限、较低的运行时开销以及独立于后端实现细节。
与这篇论文相关的人工制品可以在这里找到。亮点包括一个匿名查询-响应语料库和我们用来生成它的查询生成器。
我很高兴地告诉大家,IBM已经将我们工作的方方面面整合到IBMAPI Connectv10.x中。此产品有助于保护GraphQL服务提供商免受昂贵查询的影响。在发布链接底部的视频中,从1:45-3:30可以看到在配置过程中支持用户的GUI。从5:10到6:00,您可以看到如何将分析用于速率限制。