成为Python数据操作库Pandas的专业人士

PANAAS库是Python最流行的数据操作库。受R数据帧的启发,它提供了一种通过其数据帧API操作数据的简单方法。
很好地理解熊猫的关键之一是理解熊猫主要是一系列其他Python库的包装器。主要有Numpy、SQL炼金术、Matlot库和openpyxl。
数据框的核心内部模型是一系列NumPy数组和PANDA函数,例如现在不推荐使用的“as_Matrix”函数,它们以NumPy的内部表示形式返回结果。
熊猫利用其他库将数据传入和传出数据框。例如,SQL炼金术通过read_sql和to_sql函数使用,而openpyxl和xlsx编写器用于read_excel和to_excel函数。
而Matplotlib和Seborn则用于提供一个简单的界面,使用df.lot()等命令绘制数据框内可用的信息。
您经常听到的抱怨之一是Python速度慢或难以处理大量数据。大多数情况下,这是由于编写的代码效率较低造成的。原生Python代码确实比编译后的代码要慢。尽管如此,像Pandas这样的库提供了一个Python接口来编译代码,并且知道如何正确使用该接口,让我们充分利用Pandas/Python。
熊猫和它的底层库Numpy一样,执行矢量化操作比执行循环更有效。这些效率的提高归功于矢量化操作是通过C编译代码执行的,而不是通过本机Python代码执行的。另一个因素是矢量化操作能够在整个数据集上操作,而不仅仅是当时的一个子部分。
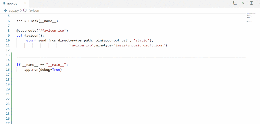
Apply接口允许通过使用CPython接口执行循环来获得一些效率:
但是,大部分的性能提升将从使用矢量化操作本身获得,无论是直接在熊猫中使用,还是通过直接调用其内部的Numpy数组来获得。
从上图中可以看到,使用矢量化操作处理它(3.53ms)和使用Apply进行加法循环(27.8s)之间的性能差异可能非常大。通过直接调用NumPy的数组和API可以获得额外的效率,例如:
Swifter:Swifter是一个Python库,可以轻松地向量化数据框上的不同类型的操作,其API与Apply函数的API有些类似。
在将数据帧加载到内存中时,无论是通过READ_CSV、READ_EXCEL或其他数据帧读取函数,PANDA都会进行类型推断,这可能被证明是低效的。这些API允许您显式地利用数据类型指定每列的类型。指定dtype允许在内存中更有效地存储数据。
Dtype是来自Numpy的本机对象,它允许您定义用于存储某些信息的确切类型和位数。
例如,Numpy的类型np.dtype(‘int32’)将表示一个32位长的整数。熊猫默认为64位整数,使用32位可以节省一半的空间:
MEMORY_USAGE()显示每列使用的字节数,因为每列只有一个条目(行),所以每个int64列的大小是8字节,int32是4字节。
Pandas还引入了分类dtype,它允许对频繁出现的值进行高效的内存利用。在下面的示例中,我们可以看到,当我们将字段POSTING_DATE转换为分类值时,它的内存使用率降低了28倍。
在我们的示例中,仅通过更改此数据类型,数据帧的总大小就减少了3倍以上:
使用正确的数据类型不仅允许您在内存中处理较大的数据集,而且还可以提高某些计算的效率。在下面的示例中,我们可以看到,使用分类类型可以将GROUPBY/SUM操作的速度提高3倍。
在PANDA中,您可以在数据加载期间定义数据类型(READ_),也可以将其定义为类型转换(ASTYPE)。
CyberPandas:Cyber Pandas是不同的库扩展之一,它支持IPv4和IPv6数据类型并有效地存储它们,从而支持更广泛的数据类型。
熊猫允许以块为单位加载数据帧中的数据。因此,可以将数据帧作为迭代器来处理,并且能够处理大于可用存储器的数据帧。
在读取数据源时定义块大小和get_chunk方法的组合允许熊猫作为迭代器处理数据,例如在上面所示的示例中,数据帧一次读取两行。然后,我们可以遍历这些块:
对于df_iter中的a,i=0:#do ome chunk=df_iter.get_chunk()i+=1new_chunk=chunk.Apply(λx:do_omething(X),new_chunk.to_csv(";chunk_output_%i.csv";=1)。
然后可以将其输出馈送到csv文件、腌制、导出到数据库等。…
Dask:是一个构建在Pandas之上的框架,构建时考虑到了多处理和分布式处理。它利用内存和磁盘上的熊猫数据帧块集合。
熊猫也建立在SQL炼金术的基础上,以与数据库连接。因此,它可以从各种SQL类型的数据库下载数据集,并向其中推送记录。使用SQL炼金术接口而不是熊猫的API直接允许我们执行某些在熊猫中不受本地支持的操作,例如事务或upsert:
熊猫还可以利用SQL事务来处理提交和回滚。佩德罗·卡佩拉斯特吉(Pedro Capelastegui)在他的一篇博客文章中特别解释了熊猫如何通过SQL炼金术上下文管理器利用事务。
使用SQL事务的优势在于,如果数据加载失败,事务将回滚。
Pandas有一些SQL扩展,比如Pandasql,这是一个允许在数据帧上执行SQL查询的库。通过panasql,可以像查询数据库表一样查询数据框对象。
PANDA本身不支持在支持此功能的数据库上向上插入到SQL的导出。熊猫的补丁存在,以允许这一功能。
有些Data Frame API已经集成了Matplotlib和Seborn,例如.lot命令。在熊猫的网站上,有一个相当全面的关于界面如何工作的文档。
扩展:存在不同的扩展,如Bokeh和Ploly,用于在Jupyter笔记本中提供交互式可视化,同时还可以扩展matplotlib以处理3D图形。
熊猫还有相当多的其他扩展,它们是用来处理非核心功能的。其中之一是tqdm,它为某些操作提供了进度条功能;另一个是Pretty Pandas,它允许我们格式化数据帧并添加摘要信息。
tqdm是Python中与熊猫交互的进度条扩展。用户在使用相关函数(PROGRESS_MAP和PROGRESS_APPLY)时,可以看到地图的进度,并对熊猫数据框进行操作:
PrettyPandas是一个库,它提供了一种简单的方法来格式化数据框并向其中添加表格摘要: