“连接不成比例”的神话
。我将参考Alex DeBrie的文章“SQL,NoSQL,and Scale:How DynamoDB Scale Where Relationship Database Not”,特别是关于“为什么关系数据库不能伸缩”的段落。但我想说明的是,我在这里的帖子并不反对本文,而是反对一个非常普遍的谬论,这个谬论甚至在NoSQL数据库之前就已经存在了。实际上,我之所以将这篇文章作为参考,是因为作者在他的网站和书中对NoSQL中的数据建模有非常好的见解。而且因为AWS DynamoDB可能是当今最强大的NoSQL数据库。我正在挑战一些广为流传的断言,更好的做法是基于高质量的内容和产品。
在许多用例中,NoSQL是正确的替代方案,但是从关系数据库系统迁移到键值存储可能不是一个很好的理由,因为您听说“联接不能伸缩”。您应该为它提供的功能(它解决的问题)选择一个解决方案,而不是因为您忽略了当前平台的能力。
本文的想法取自广受欢迎的Rick Houlihan演讲,即通过连接表,您可以读取更多数据。并且这是CPU密集型操作。根据Alex DeBrie的文章或Rick Houlihan幻灯片的“O(log(N))+Nlog(M)”,连接的时间复杂度是“(O(M+N))或更差”。这引用了“时间复杂性”和“大O”符号。你可以在书上读到这件事。但这假设联接的成本取决于所涉及的表的大小(由N和M表示)。对于未分区的表完全扫描,这是正确的。但是所有的关系数据库都带有B*树索引。当我们与键值存储进行比较时,显然检索的行很少,连接方法将是带有索引范围扫描的嵌套循环。这种访问方法实际上完全不依赖于表的大小。这就是为什么关系数据库是OTLP应用程序之王的原因。
这篇文章声称“关系数据库有一个很大的问题:性能就像一个黑匣子。影响您的查询返回速度的因素有很多。“。以查询为例:“SELECT*FROM ORDERS JOIN USERS on…。其中,user.id=…。按…分组。限制20“。它说“随着表的大小增加,这些操作将变得越来越慢。”
我将在这里用PostgreSQL构建这些表,因为这是我首选的开放源码RDBMS,并展示了这一点:
性能不是一个黑匣子:所有的RDBMS都有一个EXPLAIN命令,可以准确地显示所使用的算法(甚至CPU和内存访问),您可以很容易地从它估算成本。
Join和Group by在这里根本不依赖于表的大小,而只依赖于选定的行。在行数影响响应时间1/10毫秒之前,您需要将表乘以几个数量级。
我将在这里创建小桌子。因为在读取执行计划时,我不需要大表来估计成本和响应时间可伸缩性。如果您想要查看它的伸缩性,可以对较大的表运行相同的操作。然后可能会进一步研究大型表的特性(分区、并行查询、…)。。但是,让我们从非常简单的表开始,而不进行特定的优化。
\TIMING CREATE TABLE USERS(USER_ID BigSerial主键,FIRST_NAME TEXT,LAST_NAME TEXT);CREATE TABLE TABLE ORDERS(ORDER_ID BigSerial主键,ORDER_DATE时间戳,金额数字(10,2),USE。
我已经创建了我要连接的两个表。为简单起见,两者都使用自动生成的主键。
重要的是要像在现实生活中一样构建表格。用户可能是在没有具体订单的情况下来的。订单是按日期来的。这意味着来自一个用户的订单分散在整个表格中。有了集群数据,查询速度会快得多,每个RDBMS都有一些方法来实现这一点,但我想在这里展示在不进行特定优化的情况下连接两个表的成本。
INSERT INSERT USERS(FIRST_NAME,LAST_NAME)WITH RANDOM_WODS为(SELECT GENERATE_SELECTION id,Translate(md5(Random()::Text),';-0123456789';,';aeioughij';as word from GENERATE_SELING(1,100))select words1.word,words2.word from Random_words1交叉连接Random_Words2 ORDER BY words1.id+words2.id;INSERT 0 10000。用户名|名字|姓氏-+-+-1|ooifgiicuiejiareegiuccuiogib|iooifgiicuiejiareegiuccuiogib 2|iooifgiicuiejiareduciuccuiogib|dgdfeeiejcohfhjgcoigdeaubjbg 3|dgdfeeijcohfhjgcoigiedeaubjbg|iooifgiicuie。ooifgiicuiejiareduciuccuiogib|jbjubjcidcgubecfejidhoigdob 8|jbjubjcidcgugubecfejidhoigdob|iooifgiicuiejiareduciuccuiogib 9|ueuedijudifefoedbuojuoaudec|dgdfeeijcohfjgcoigiedeaubjbg 10|dgdfeeieddfeeijcohfjgcoigiedeaubjbg 10|dgdfeeiedfeeijcohfjgcoigiedeaubjbg 10|dgdfeeiedeaubjbg 10|dgdfeeie。
插入订单(ORDER_DATE,AMOUNT,USER_ID,DESCRIPTION),RANDOM_AMOMENTS为(-&>;这将生成10个随机订单金额SELECT 1e6*RANDOM()作为Amount from GENERATE_Series(1,10)),RANDOM_DATES AS(-&>;这将生成10个随机订单日期SELECT NOW()-RANDOM()*INTERVAL';1年';AS ORDER_DATE FROM GENERATE_RESERENCE(1,10))SELECT ORDER_DATE,Amount,USER_ID,MD5(RANDOM()::TEXT)DESCRIPTION FROM RANDOM_DATES交叉联接RANDOM_AMOUNS交叉联接USERS ORDER BY ORDER_DATE-&&我按日期对其排序,因为这就是现实生活中发生的情况。按用户进行群集将不是一个公平的测试。;插入0 1000000时间:4585.767毫秒(00:04.586)。
我现在有一百万个订单,每个用户在过去的一年里产生了100个订单。您可以玩弄这些数字以生成更多数据,并查看其扩展情况。这很快:5秒就能在这里生成100万个订单,如果您觉得需要在非常大的数据集上进行测试,有很多方法可以更快地加载。但问题并不在于此。
对订单(USER_ID)创建索引ORDERS_BY_USER;创建索引时间:316.322毫秒ALTER TABLE ORDERS添加约束ORDERS_BY_USER外键(USER_ID)引用用户;ALTER TABLE TIME:
因为在我的数据模型中,我想从用户导航到订单,所以我为它添加了一个索引。我声明引用完整性是为了避免逻辑损坏,以防我的应用程序中存在错误,或者在某些临时修复过程中出现人为错误。一旦声明了约束,我就不再需要在代码中检查此断言。约束还通知查询规划器知道这种一对多关系,因为它可能打开一些优化。这就是关系数据库的美妙之处:我们声明这些内容,而不必编码它们的实现。
真空分析;真空时间:429.165毫秒,选择版本();x86_64-PC-linux-gnu上的-PostgreSQL12.3版,编译:GCC(GCC)4.8.5 20150623(红帽4.8.5-39),64位(1行)。
我使用的是PostgreSQL版本12,运行在只有2个CPU的Linux机器上。我已经运行了手动吸尘器来获得可重现的测试用例,而不是依赖于在那些桌子加载之后自动吸尘器启动。
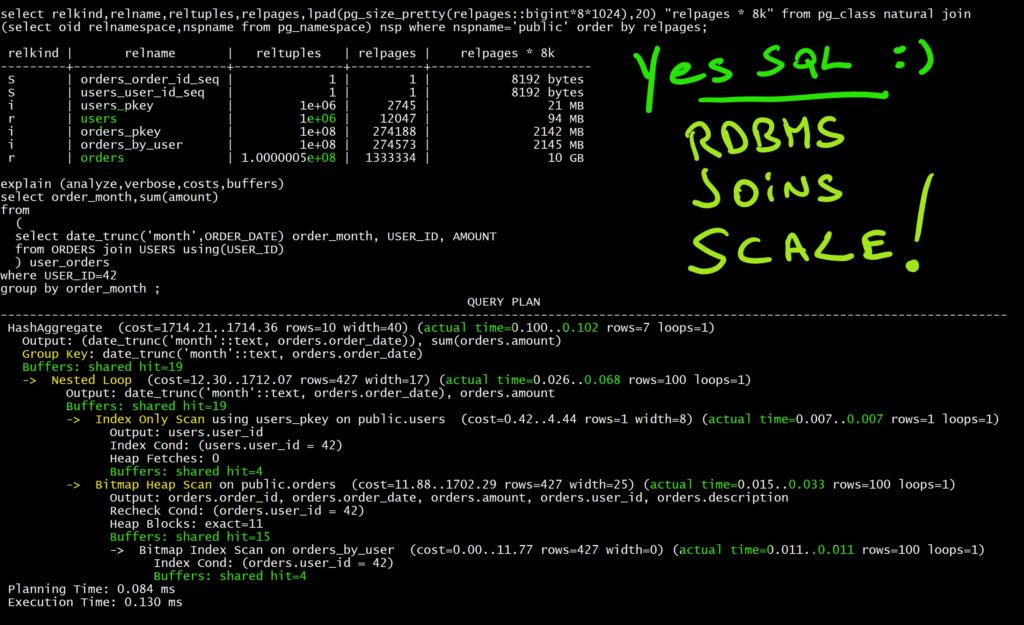
从PG_CLASS自然连接(SELECT OID RENAME SPACE,NSPNAME FROM PG_NAMESPACE)nsp where lpad(pg_size_pretty(relpages::bigint*8*1024),20)=#39;public';order by relpage;relKind|relname|reltuples|relPages|relPages*8k-+-S|order_order_id_seq|1|1|8192字节S|user_user_id_seq|1|1。8192字节i|Users_pkey|10000|30|240kB r|用户|10000|122|976kB i|Orders_pkey|1e+06|2745|21MB i|Orders_by_User|1e+06|2749|21MB r|订单|1e+06|13334|104MB。
下面是我的表的大小:100万个订单占用104MB,10000个用户占用1MB。稍后我会增加它,但是我不需要这个来理解性能的可预测性。
在了解大小时,请记住表的大小仅为数据的大小。元数据(如列名)不会为每行重复。它们在描述该表的RDBMS目录中存储一次。由于PostgreSQL具有原生JSON数据类型,因此您也可以在这里使用非关系模型进行测试。
SELECT ORDER_MONTH,SUM(AMOUNT),COUNT(*)FROM(SELECT DATE_Trunc(';MOUNT';,ORDER_DATE)ORDER_MONTH,USER_ID,Amount from Orders使用(USER_ID)加入用户)USER_ORDERS WHERE USER_ID=42 GROUP BY。ORDER_MONTH|SUM|COUNT。01 00:00:00|10027887.14|20 2020-06-01 00:00:00|5013943.57|10 2019年-07-01 00:00:00|5013943.57|10(7行)时间:2.863毫秒。
下面是本文中提到的查询:获取一个用户的所有订单,并对它们进行聚合。查看时间并不是很有趣,因为它依赖于RAM来缓存数据库或文件系统级别的缓冲区,以及磁盘延迟。但我们是开发人员,通过查看执行的操作和循环,我们可以理解它是如何扩展的,以及我们在“时间复杂性”和“大O”量级中处于什么位置。
EXPLAIN(分析,详细,成本,缓冲区)SELECT ORDER_MONTH,SUM(Amount)FROM(SELECT DATE_TRUNC(';MOUNT';,ORDER_DATE)ORDER_MONTH,USER_ID,Amount from Orders Join Users Using(USER_ID))USER_ORDERS WHERE USER_ID=42 Group by Order_Month;查询计划--。-组聚合(成本=389.34..390.24行=10宽度=40)(实际时间=0.112..0.136行=7个循环=1)输出:(DATE_TROUNC(';月';::Text,orders.order_date),SUM(orders.mount)组密钥:(Date_trunc(';月';::Text,orders.order_Date))缓冲区:共享命中=19->;排序(成本=389.34..389.59行=100宽度=17)(实际时间=0.104..0.110行=100循环=1)输出:(Date_trunc(';月';::text,orders.order_date),orders.mount排序关键字:(date_trunc(';月';::text,orders.order_date))排序方法:快速排序内存:32KB缓冲区:共享命中=19-&>;嵌套循环(成本=5.49..386.02行=100Width=17)(实际时间=0.022..0.086行=0.086循环=1)输出:Date_trunc(';月';::公共用户(成本=0.29..4.30行=1宽度=8)(实际时间=0.006..0.006行=1循环=1)输出:users.user_id索引条件:(users.user_id=42)堆提取:0缓冲区:共享命中=3->;对public.order(成本=5.20..380.47行=100Width=25)(实际时间=0.012..0.031行=100循环=1)的位图堆扫描输出:orders.order_id,orders.order_date,orders.mount,orders.user_id,orders.description重新检查条件:(orders.user_id=42)堆块:Exact=13 Buffers:Shared Hit=16->;ORDERS_BY_USER上的位图索引扫描(成本=0.00..5.17行=100WIDTH=0)(实际时间=0.008..0.008行=100个循环=1)索引条件:(orders.user_id=42)缓冲区:共享命中率=3计划执行时间:0.082毫秒执行时间:0.161毫秒
这是包含执行统计数据的执行计划。我们已经从用户那里读取了3个页面,以获取USER_ID(仅索引扫描),并使用嵌套循环导航到订单,并获得此用户的100个订单。这从索引中读取了3页(位图索引扫描),从表中读取了13页。总共有19页。这些页面是8K块。
让我们将表的大小增加4倍。我将用户世代中的“Generate_Series(1,100)”更改为“Generate_Series(1,200)”,并运行相同的代码。这产生了40000用户和400万订单。
从PG_CLASS自然连接(SELECT OID RENAME SPACE,NSPNAME FROM PG_NAMESPACE)nsp where lpad(pg_size_pretty(relpages::bigint*8*1024),20)=#39;public';order by relpage;relKind|relName|reltuples|relPages|relPages*8k-+-S|order_order_id_seq|1|1|8192字节S|user_user_id_seq|1。|1|8192字节i|Users_pkey|40000|112|896kB r|Users|40000|485|3880kB i|Orders_pkey|4E+06|10969|86MB i|ORDERS_BY_USER|4E+06|10985|86MB r|订单|3.999995e+06|52617|411MB解释(分析,详细、成本、缓冲区)SELECT ORDER_MONTH,SUM(AUM)FROM(SELECT DATE_TRUNC(';月';,Order_Date)ORDER_MONTH,USER_ID,Amount from Orders使用(USER_ID)加入用户使用(USER_ID)USER_ORDERS WHERE USER_ID=42 GROUP BY ORDER_MONTH;EXPLAIN(ANALYSE,Verbose,Cost,Buffers)SELECT ORDER_MONTER,SUM(Amount)FROM(SELECT DATE_TRUNC(';MONTER';,ORDER_DATE)ORDER_MONTH,USER_ID,Amount from Orders使用(USER_ID)加入用户。查询计划--。-组聚合(成本=417.76..418.69行=10宽度=40)(实际时间=0.116..0.143行=9个循环=1)输出:(DATE_TROUNC(';月';::Text,orders.order_date),SUM(orders.mount)组密钥:(Date_trunc(';月';::Text,orders.order_Date))缓冲区:共享命中=19->;排序(成本=417.76..418.02行=104Width=16)(实际时间=0.108..0.115行=0.115循环=1)输出:(Date_trunc(';月';::text,orders.order_date),orders.mount排序关键字:(date_trunc(';月';::text,orders.order_date))排序方法:快速排序内存:32KB缓冲区:共享命中=19-&>;嵌套循环(成本=5.53..414.27行=104Width=16)(实际时间=0.044..0.091行=0.091循环=1)输出:Date_trunc(';月';::公共用户(成本=0.29..4.31行=1宽度=8)(实际时间=0.006..0.007行=1循环=1)输出:users.user_id索引条件:(users.user_id=42)堆提取:0缓冲区:共享命中=3->;对public.order的位图堆扫描(成本=5.24..104Width=24)(实际时间=0.033..0.056行=0.056循环=1)输出:orders.order_id,orders.order_date,orders.mount,orders.user_id,orders.description重新检查条件:(orders.user_id=42)堆块:Exact=13缓冲区:Shared Hit=16->;ORDERS_BY_USER上的位图索引扫描(成本=0.00..5.21行=104WIDTH=0)(实际时间=0.029..0.029行=100个循环=1)索引条件:(orders.user_id=42)缓冲区:共享命中=3计划时间:0.084毫秒执行时间:0.168毫秒(27行)时间:0.532毫秒。
看看我们在这里是如何伸缩的:我将表的大小乘以4倍,我的成本完全相同:每个索引3页,表13页。这就是B*Tree的美妙之处:成本只取决于树的高度,而不取决于桌子的大小。并且您可以在索引高度增加之前指数级地增加表。
让我们再进一步,把桌子的大小再乘以4倍。我在用户代中使用“Generate_Series(1,400)”运行,并且运行相同的命令。这产生了16万用户和1600万订单。
从PG_CLASS自然连接(SELECT OID RENAME SPACE,NSPNAME FROM PG_NAMESPACE)nsp where lpad(pg_size_pretty(relpages::bigint*8*1024),20)=#39;public';order by relpage;relKind|relName|reltuples|relPages|relPages*8k-+-S|order_order_id_seq|1|1|8192字节S|user_user_id_seq|1。|1|8192字节i|Users_pkey|160000|442|3536kB r|Users|160000|1925|15MB i|Orders_pkey|1.6E+07|43871|343MB i|ORDERS_BY_USER|1.6E+07|43935|343MB r|ORDERS|1.600005e+07|213334|1667MB解释(分析,详细、成本、缓冲区)SELECT ORDER_MONTH,SUM(AUM)FROM(SELECT DATE_TRUNC(';月';,ORDER_DATE)ORDER_MONTH,USER_ID,Amount from Orders使用(USER_ID)USER_ORDERS WHERE USER_ORDERS WHERE USER_ID=42 GROUP BY ORDER_MONTH;查询计划
从PG_CLASS自然连接(SELECT OID RENAME SPACE,NSPNAME FROM PG_NAMESPACE)nsp where lpad(pg_size_pretty(relpages::bigint*8*1024),20)=#39;public';order by relpage;relKind|relName|reltuples|relPages|relPages*8k-+-S|order_order_id_seq|1|1|8192字节S|user_user_id_seq|。1|1|8192字节i|Users_pkey|640000|1757|14MB r|用户|640000|7739|60MB i|Orders_pkey|6.4e+07|175482|1371MB i|Orders_by_User|6.4E+07|175728|137MB r|订单|6。
.