一种统一的强化学习框架--TayPO
来自哥伦比亚大学和DeepMind的一组研究人员提出了一个泰勒展开策略优化(TayPO)框架,该框架结合了两种领先的算法改进方法。
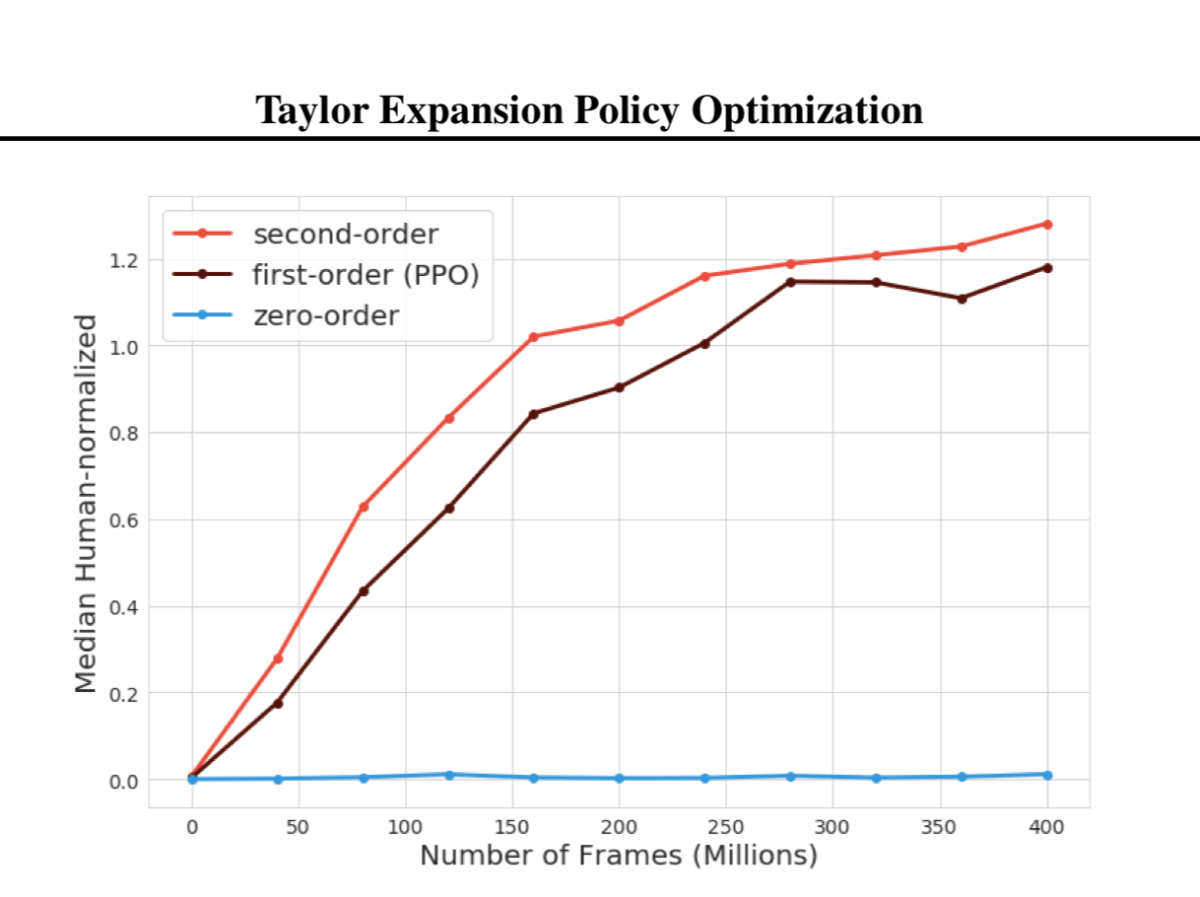
策略优化是无模型强化学习(RL)中的一个主要框架,它提供了可以显著提高算法性能的见解。其中两个最突出的算法改进是信任区域策略搜索和非策略修正,而这些想法流通常是单独评估的。在“泰勒展开策略优化”一文中,研究人员将这些算法思想部分统一到单个框架中,展示了泰勒展开-一种基于泰勒级数概念用于描述和近似数学函数的方法-如何与信任域策略搜索和非策略修正共享高级相似性。这篇论文于本周在ICML2020上发表。在以往的信赖域策略搜索研究中,主要思想是限制策略更新的大小,以限制连续策略之间的偏差,并降低新策略的性能。与此同时,非政策修正要求对目标政策和行为政策之间的差异进行核算。研究人员提出,信赖域约束的固有概念是泰勒展开和信赖域策略搜索的共同特征,并且泰勒展开也满足非策略评估的要求。本文阐述了泰勒展开式如何构造对全部IS(重要性抽样)校正的近似,这是大多数非策略评估技术的核心,因此与已建立的非策略评估技术密切相关。以前的工作集中于将非政策校正直接应用于政策梯度估计器,而不是产生梯度的替代目标。研究人员指出,尽管标准政策优化目标涉及IS权重,但它们与IS的联系并不明确。泰勒展开的使用解决了标准策略优化目标和IS之间的隐含联系。研究人员评估了在一系列不同的场景中应用泰勒展开的好处。实验结果表明,二阶校正的性能略好于一阶和回溯,明显优于零阶校正。一般说来,无偏见(或略有偏差)的非政策修正还没有表现得像完全有偏见的非政策变体那样好。总而言之,这种新配方可以为最先进的深度RL制剂带来显著的收益。论文“泰勒扩展策略优化”发表在arxiv上。
这份报告让我们看到了中国政府和企业主在与新冠肺炎的斗争中是如何利用人工智能技术的。它也可以在亚马逊Kindle上买到。
我们知道你不想错过任何故事。我们可以订阅我们广受欢迎的、同步的全球AI周刊,以获得每周的AI更新。