入门读物:使用声音进行预测性维护
马达隐藏在人们的视线中,是人类文明不可或缺的一部分。在你的笔记本电脑、你的车、你的房子、你的学校和你的手表里都可以找到汽车。没有马达,你心爱的产品就无法制造。根据美国能源部的数据,工业电机的使用占全国所有用电量的25%。
类似于马达,声音无处不在,类似于马达,有些声音是听不到的。有了传感器,可以分析声音来检测故障,从而在它们成为大问题之前防止重大故障。
传统的预测性维护方法分为三个部分:1)在机器开始故障之前,使用传统的硬件工具(如超声波麦克风)识别异常声音。2)使用红外摄像机检测放电或泄漏检测3)使用能够识别压力、温度或振动变化的传感器。人工智能(AI)的最新进展改变了预测性维护的优化方式。
在这篇博客中,我们将设计一种深度学习结构,如卷积递归神经网络(CRNN)来处理高频数据,这些数据将从频谱图中进行处理。CRNN模型同时从我们数据的空间结构和递归结构中学习。
有了成千上万的高频声音片段,机器学习可以用来预测马达何时会发生故障。然后将结合信号处理技术创建CRNN模型,以使我们能够从高频数据中提取价值。我们首先使用传感器收集数据,并将声音分为四类:最佳压力、轻微降低的压力、严重降低的压力、接近完全失效)。
我们通过将原始数据分割成固定且相等的标记序列来处理原始数据。我们采用谱图对这些信号片段进行预处理,并将这些片段送入CRNN模型。频谱图是信号的时频图像。它们基本上是信号的频率强度随时间推移的曲线图。换句话说,我们正在构建一个人工智能支持的时间序列模型,它可以映射高频域中的数据行为。为了标准化我们的序列,我们需要降低序列的大小;一个简单的区分,加上一个适当的片段来限制极端的变化。
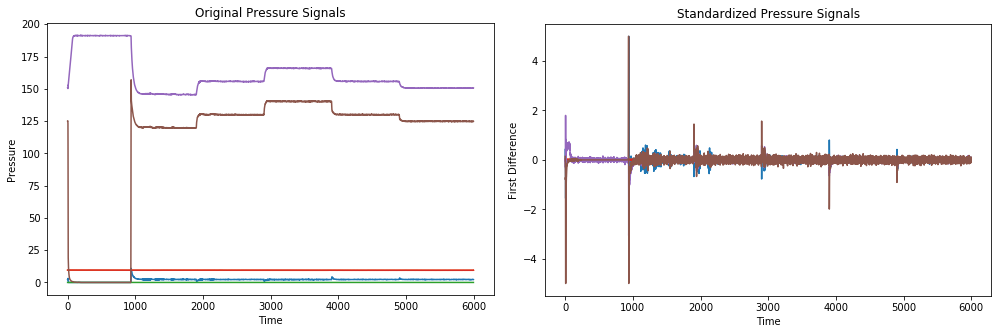
以下是由6个不同压力信号组成的原始序列和标准化序列的示例图:
为了在Python中计算谱图,我们使用名为Librosa的库。对我们可以处理的每个压力序列进行转换,因此我们以每个样本的6个频谱图序列结束,而不是原始信号序列。
CNN(卷积神经网络)和RNN(递归神经网络)可以一起使用,并且它们不是互斥的,因为两者都可以对图像和文本输入进行分类,从而创造了组合两种网络类型以提高效率的机会。当CNN不能处理具有附加时间特征的视觉复杂性时,RNN会介入并解决处理问题。
CNN和RNN的组合有时被称为CRNN。输入首先由CNN层处理,然后其输出被馈送到RNN层。光学字符识别和/或音频分类通常使用这种类型的混合模型。
在本练习中,我们向CRNN提供先前生成的光谱图,以检测电机的工作状态。马达的每一次观测现在都由堆叠的光谱图组成(总共6个,每个压力信号一个)。执行此操作的脚本如KERAS中所示:
Def get_model(Data):inp=input(Shape=(data.Shape[1],data.Shape[2],data.Shape[3]))x=Conv2D(过滤器=64,内核大小=(2,2),填充=';相同';)(INP)x=BatchNormalization(轴=1)(X)x=Activation(';REU';)(X)x=MaxPooling2D(pool_size=(2,1))(X)x=Dropout(0.2)(X)x=置换((2,3,1))(X)x=重塑((data.Shape[2],-1))(X)x=双向(GRU(64,激活=';REU';REU';Return_Sequence=False))(X)x=密集(32,激活='。)(X)x=Dropout(0.2)(X)Out=Dense(y_Train.Shape[1],Activate=';Softmax&39;)(X)MODEL=MODEL(INPUTS=INP,OUTPUTS=OUT)model.compile(loss=';categorical_crossentropy';,优化器=';ADAM&39;,指标=[';精度&39;])返回模型。
在第一阶段,网络从谱图中提取卷积特征,即结构、频率x时间x n特征。要遍历递归部分,我们需要以xn_Feature:Time格式重塑数据。新的n特征是对卷积n特征和频率进行奉承运算的结果。因此,我们的模型达到了86%左右的准确率。
在这篇博客中,我们了解了预测性维护的传统方法,并略微触及了这一领域的AI应用。随着人工智能的进步,未来对硬件传感器的依赖将会减少。