为什么GPT-3很重要
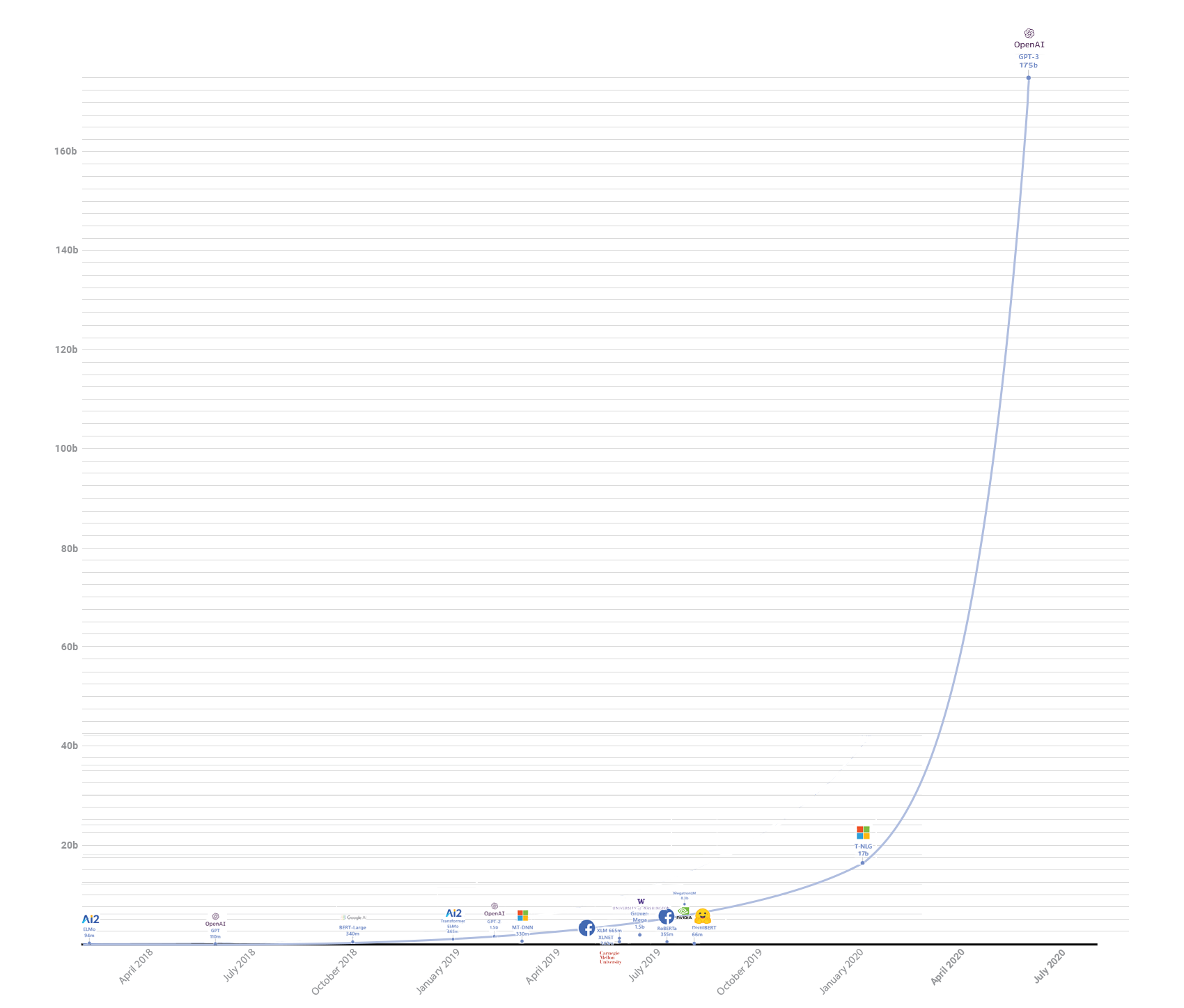
这很难夸大;它比微软已经很大的17B参数Turing-NLG大了整整一个数量级。[1]在FP16中加载整个模型的权重将占用绝对荒谬的300 GB的VRAM,甚至不包括渐变。但是,庞大的规模带来了强大的泛化能力:GPT-3在许多基准测试中具有竞争力,甚至不需要对目标任务进行调优。当我说很多的时候,我指的是很多-这篇72页的完整论文包含了对GPT-3在许多NLP数据集上的广泛评估。然而,也许最令人印象深刻的部分是,即使是在如此大规模的情况下,该模型在性能上仍然可以平稳地扩展,而不是停滞不前,这意味着更大的模型会表现得更好。在这篇文章的其余部分,我的目标是将这篇巨大的论文(以多种方式)提炼成可消化的大小,并阐明它为什么重要。
下表总结了过去几年中一些最大的自回归变压器模型。我已经排除了像XLNet和BERT衍生品这样的模型,因为它们没有相同的单向自回归训练目标。
虽然GPT-3没有那么深,但它的宽度几乎是Turing-NLG的3倍,因为参数计数与隐藏大小的平方大致成正比,它解释了大多数额外参数的来源。它的上下文大小也翻了一番,达到2048个令牌,这令人印象深刻(而且内存昂贵!),尽管不是所有型号中最大的上下文大小;有些型号的上下文甚至更长,比如Transformer-XL,它通过在段之间传递上下文向量来合并更长的上下文,还有Reformer,它使用位置敏感的散列来实现稀疏关注。同样,GPT-3在每隔一层使用稀疏的关注层,尽管具体细节有些含糊。有趣的是,为与GPT-2进行比较而训练的较小的GPT-3版本略浅、略宽,GPT-3-XL只有24层,但隐藏的大小是2048。[2]GPT-3还重用了GPT-2的BPE标记化。总体而言,GPT-3本质上只是GPT-2的一个彻头彻尾的巨型版本。
培训数据是Common Crawl、WebText2(原始数据的更大版本,还包括2018年1月至10月期间采样的链接)、两本书语料库和英语维基百科的重新加权组合。其中一些组件,如维基百科,在培训期间被查看超过3次;其他组件,如庞大的Common Crawl组件,其数据被查看的次数不到一半。作者声称,这是为了通过对已知良好的数据集进行优先排序来帮助提高语料库的整体质量。此外,与原来的WebText相比,这个新的语料库没有按语言过滤,但仅仅因为英语的流行,英语仍然占数据集的93%。经过过滤和清理后,数据集总共是5000亿令牌,或700 GB[3]。本文还详细描述了数据集的过滤过程,这是GPT-2论文没有做的。
作者还试图删除与评估的训练集和测试集重叠的任何数据。不幸的是,由于一个错误,一些被遗漏了,所以为了补偿,论文提供了一个相当好的分析这种泄漏的影响。
GPT-3的评估部分非常全面,在Zero-shot(生成上下文中仅给出自然语言描述)、One-shot(生成上下文中的单个示例)或Null-shot(生成上下文中的少数几个示例)设置下对大量NLP任务进行评估。事实上,这篇论文甚至没有尝试对目标任务进行微调,而是将其留给未来的工作。[4]然而,一个关键的结论是,在几乎所有的测试中,更大的模型的性能继续提高,即使是在4个完整的数量级上,而微调只在一项任务上有所改善,并面临灾难性的遗忘和过度匹配的风险。
在不做太多单独测试的情况下,总体结果是:在大多数任务上,GPT-3的性能明显逊于微调SOTA(例如,Superglue、CoQA、Winograd等),但在其他一些任务(即PhysicalQA、Lambada、Penn Tree Bank)上优于微调SOTA。GPT-3在PTB上的表现尤其出色,将SOTA困惑从35.76降至20.5-这是一个巨大的进步。GPT-3最终还可以进行算术运算,这是GPT-2做不好的。
令人印象深刻,或许有些令人担忧的是,人们无法区分GPT-3产生的新闻故事和真实的新闻故事,这只会加剧GPT-2已经提出的伦理问题。本文对GPT-2的发布结果进行了分析,认为GPT-2的发布并没有导致LMS的广泛使用,因为无论是在中低技能的对手中,还是在高级人员中,由于难以控制输出和输出质量的差异,LMS都没有导致错误信息的广泛使用,因此GPT-2的发布并没有导致LMS在错误信息方面的广泛使用
作者还调查了GPT-3中的性别偏见,表明GPT-3是男性倾向的;然而,作者声称,Wingender数据集(测试同一句子但具有不同性别代词的共指分辨率)上的一些初步证据似乎表明,较大的模型对偏见问题更稳健。种族和宗教也出现了类似的问题,人们对同时使用的术语的看法随着种族的不同而有很大不同。作者声称,这个问题在较大的模型中也变得更好-尽管,如果没有适当的假设检验,很难在这里得出任何可靠的结论。
但是,如果GPT-3甚至不能在所有基准中击败SOTA,那么它为什么重要呢?我们为什么要关心一个如此庞大的模型,以至于一个小的计算集群即使只是为了以合理的速度运行推理也是必要的呢?
关于GPT-3的一件事是,它在从未见过的任务上做得相当好。此外,GPT-3并没有达到收益递减点,而是显示较大型号表现更好的趋势至少持续了另一个数量级,没有停止的迹象。尽管GPT-3很笨拙,即使它仍然没有完全达到人类水平的全面性能,但GPT-3表明,模型有一天在NLP中达到人类水平的泛化是可能的-一旦不可能成为可能,它变得实用只是个时间问题。
早在去年年底,当我谈到大型Transformer语言模型(如GPT-2、CTRL和Megatron-LM)时,我简要地谈到了语言模型变得越来越大的趋势,并讨论了一些简单的计算可能无法解决的问题。我的普遍预期是,模型大小的军备竞赛很快就会暂时停滞,焦点将转移到更好的文本生成解码策略上(可能是通过基于RL的方法)。我肯定没有想到OpenAI会这么快带着这么庞大的模型回来。
这是如此令人惊讶,以至于我放下一切去看报纸,开始写这篇文章,包括我已经写了几个月的一篇更注重理论的文章。当我从GPT-3休克中恢复过来后,它可能会完成。敬请关注!↩︎。
这样做很可能是为了更容易的模型并行性-更大的矩阵乘法比像GPipe那样按顺序应用的层更容易并行化。
不过,这也可能有其他优势。在EfficientNet问世后,我独立地对Transformer模型进行了一些相同概念的实验,结果是在相同的计算量下,更广泛的模型比更深的模型有相当大的优势-这证实了这里选择使用更广泛的模型。↩︎。
这个数字是从文中给出的公共爬行集的大小推断出来的。↩︎
有人猜测,这篇论文中缺乏微调的例子。一个原因可能是,对于如此大的模型,微调范例由于容易过度拟合而开始崩溃,尽管无法访问模型(以及硬件对其进行调优!)。除了推测之外,我们没什么可做的了。↩︎