这是一篇关于Node.js如何在幕后工作的深入文章,分为三个部分
当谈论节点如何工作时,人们谈论的是单线程、非阻塞、异步事件循环。但是每个程序都必须通过系统调用与操作系统对话。服务器可以被描述为操作系统机制之上的抽象,因为它是操作系统告诉硬件要做什么。读完这篇文章后,你将能够带着一堆让经理们疯狂的新流行语参加Javascript面试。EPOLL、事件流和多路复用器等时髦词汇。记住,拥有大的木质平台能量比一个真正的大木质平台更重要。即使你没有完全理解,经理也可能认为你真的读过源代码,他不能测试,因为他肯定没有,所以让我们给你的木质平台增加一些能量,解释一下节点是如何与Linux操作系统对话的。
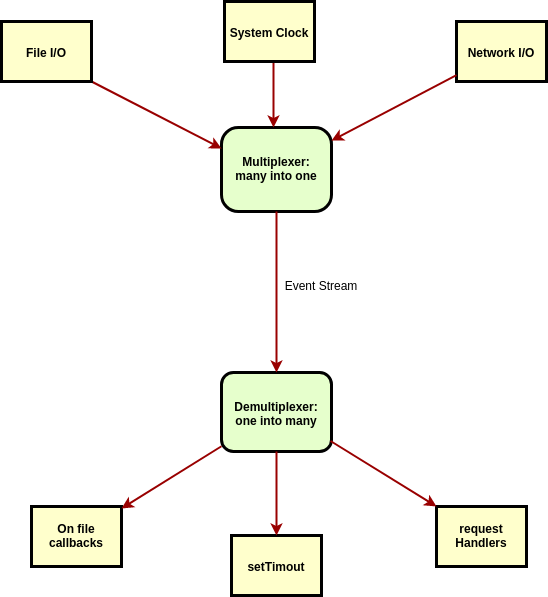
服务器的总体情况是,数据先进行多路复用,然后再进行多路分解。多路复用器采用多个输入通道并创建单个输出通道。它被多路复用成什么?我们称它为事件流,因为它是数据流,数据可以是任何东西,所以让我们只称每个数据点为事件。在节点中,当接收到来自客户端的请求并在其上调用处理程序时,如下所示。
通过将单个流解构成几个队列,并将事件从队列中取出以发送到处理程序函数进行处理,可以将事件从事件流中移除。现在,这应该是你的心理模型了:
下一个问题应该是,为什么我们要多路传输?为什么不在传入的网络事件上直接调用文件处理程序?很简单,因为他们会阻挡。
阻塞经常被提出来,任务被称为阻塞或非阻塞。要解释阻塞,假设您必须做三件事。你要做饭,然后洗衣服,然后打扫。你打算什么时候做呢?当你做完一件事后,你就开始做另一件事。换句话说,在你做饭之前,在洗衣房上放置烹饪块,然后,在你处理完衣服之前,清洁是被阻止的。这非常简单,因为您不必担心调度任务,计时是工作负载完成的问题。但是,如果你在烤鸡呢?你的意思是我要等一个半小时?
这就是并发性的用武之地。要同时烤鸡和洗衣服,你需要为两者分配资源,并确保其中一个不会干扰另一个。在Linux中,在程序之间划分资源的是进程。它们不仅为了安全将程序彼此分开,而且还创建可以并发运行的独立执行线程。
在烤鸡的同时洗衣服是并行和并发的一个例子,但我们实际上并不需要并行。下面是一个处理器的单核如何利用并发进程来帮助我们避免阻塞。
早在20世纪80年代,当人们第一次开始故意撕裂牛仔裤,橙汁是富人的专利时,事情就简单了一点。如果您想要写入终端,并且能够读取输出,则必须完成两件事。您必须对文件调用write(),然后调用read()。为什么是文件?因为Unix中的所有东西都是文件。互联网连接、磁盘上的实际文件或本例中的标准输出。这意味着read()和write()是您发送和接收数据的方式。
当您将10KB的数据写入文件时,会发生这样的情况:写入将发送1KB的数据,在发送其余数据之前,它会等待已读取的信号。在此期间,它会阻塞。那么,我们怎么才能读到阅读部分呢?读取被阻止,直到写入收到已读取的信号,但读取被阻止发生。
以前人们想办法处理这件事的方式比你想象的要愚蠢得多。说真的,这是无知的。您分叉该过程,该过程将引用复制到同一文件,并在它们之间来回切换,甚至在切换到另一个之前甚至不询问其中一个是否完成。一个进程调用write(),另一个进程调用read(),每秒切换多次,使其看起来像是一次发生。
进程之间的切换称为上下文切换。大多数操作系统使用抢占式多任务,这意味着它们几乎不会对进程之间的优先级进行排序,而是简单地根据总共有多少进程来决定一个进程的执行时间。在切换到下一个进程之前,它甚至不会询问进程是否“完成”了任何操作。这就是我们的模型现在的样子。
该模型的第一个创新是创建非阻塞I/O。假设我们有一个100字节的写缓冲区,总共有200个字节要写。我们清空了缓冲区,但是我们不能执行下一次写入,因为前100个字节尚未读取。使用阻塞I/O,我们将无限期阻塞。但是,如果我们知道我们将阻塞,那么我们将返回一个错误,告知我们另一个写操作将阻塞,而不是阻塞呢?让我们将该错误称为EWOULDBLOCK。我们的非阻塞代码应该如下所示:
这样,我们可以在同一进程中进行写入和读取,两者都在等待对方返回此错误以便再次运行。问题解决了,对吧?如果您需要对可能数以千计的流套接字进行读/写,您将如何在单个进程中进行编排?如果我们需要在同一过程中阅读10个不同的内容,我们可以不断地遍历它们,看看哪一个会阻塞。如果它们没有可读取的内容,这将是对系统资源的浪费。我们可以加入延迟,比如每秒循环通过它们。这意味着数据读取可能会延迟一秒,从而增加延迟。
那么,你在想,我们又回到上下文切换了吗?服务器必须处理数千个输入/输出操作,我们的进程有那么多吗?上下文切换是有代价的。每次切换到另一个进程时,CPU中当前缓存中的数据都会被新数据替换。每个进程还会占用内存,并且所有这些进程都会占用大量RAM。
对于网络数据,我们总是使用称为套接字的东西与其他计算机通信。套接字是在1983年引入的,它们在操作系统中也表示为文件。我们谈到了读取和写入文件,但没有说明如何做到这一点。我们引用该文件的方式是通过文件描述符。这是一个整数,在文件描述表中用作引用。文件描述有两个值:一个标志,用于确定在派生此进程时是否将此文件描述符复制到子进程,以及对我们前面讨论的文件结构的引用。
当我们调用read()或write()时,我们是在文件描述符(FD)上调用它们,然后使用文件引用来确定这些函数的实际实现-写入流套接字与写入终端明显不同,尽管Linux将同时调用这两个“文件”。您说FDS只是整数,那么我们的操作系统如何知道它们代表什么呢?我们总是在同一进程中工作,该进程只有一个文件描述表,而FD是一个索引,始终精确映射1:1。
那么,我们如何在一个进程中处理数千个FD呢?和同样出生于1983年的一个小朋友一起,选择()。让我们看看系统调用select()如何处理50个读取的FD。Select()循环遍历它们,并询问是否每个文件都已准备好读取。除了要监视哪个操作(读取)和哪个FD外,我们还传递了SELECT a Timeout。这是select()将阻塞的时间量,直到它向我们发送当前就绪的FDS。是的,我们仍然在阻挡,但是我们阻挡的次数减少了。
因此,我们不是等待单个文件描述符停止阻塞,而是要求select()接受所有这些输入,并输出一个数据流,这就是准备好与我们对话的FD。不仅如此,一切都发生在用户空间中,保证了内存的安全。哦,我们现在在做空间练习。
当程序共享相同的资源,并且它们可以直接访问内存时,它们可以访问彼此的数据。这意味着如果你有一个银行应用程序,你下载了一款精灵宝可梦游戏,皮卡丘就可以偷你的钱。这个问题通过在程序和内存之间创建一个称为虚拟内存的抽象层来解决。它们不是直接与内存交互,而是与这一层交互,这一层背后是内核,它决定要做什么。内核是操作系统最重要的部分,可以直接访问所有内容。
表示网络套接字的FILE结构在内核空间中,select()和node在用户空间中操作。正如您可以想象的那样,从内核转到用户领域会有延迟,但是利用用户领域代码不会让您访问几乎同样多的数据。有一些服务器完全停留在内核空间,称为加速器,但它们很愚蠢。
因此,我们有一个内存安全的用户域多路复用器,它以一种不会阻塞整个节点的方式将事件发送到节点。然而,有一个问题。因为select()必须遍历我们发送给它的所有FD,所以它的运行时间是O(N),换句话说,我们一次可以扩展到几百个连接,但不能扩展到一万个。我们需要一个更好的多路复用器。
让我们回到做饭、洗衣、清洁的例子。比方说,我们需要一种特殊的化学物质来加快清洁速度,于是我们派你的小弟弟去买。我们怎么知道他什么时候拿到的?每隔10秒问他一次,他会告诉我们什么时候。这非常烦人,这就是select()正在做的事情。取而代之的是,我们可以放松,做我们的事情,当他有肩膀的时候,他会拍拍我们的肩膀。这就是EPOLL要做的。
EPOLL是事件轮询的缩写,是内核中的一种结构,用于跟踪当前就绪的文件描述符。我们使用三个系统调用与其对话:EPOLL_CREATE(),它初始化EVENT_POLL结构并为其返回FD;EPOLL_ctl(),它将FD添加到兴趣列表;以及EPOLL_WAIT(),它阻塞直到FD可用。注意,我们从EPOLL_CREATE()返回一个FD-没错,我们可以对EPOLL调用select(),因为EPOLL可以被视为文件。
EPOLL的工作方式有两种:电平触发和边缘触发。Level触发类似于select(),我们给EPOLL_WAIT一个超时,当它到期并返回阻塞时,它会发出就绪的FDS。每次EPOLL监控的任何FD发生更改时,边缘触发都会向我们发送就绪FD。
重要的是要记住,EPOLL不会询问FD它是否准备好了。相反,对EPOLL兴趣列表中与FD相关联的文件进行更改的I/O事件会动态填充就绪列表。当从连接到某台远程计算机的数据通过网卡中的管道进入时,网络模块会使用信号中断通知您的CPU。中断上下文在进程上下文之外,可以向任何未处于不可中断状态的进程发送中断,这在某些系统调用(如mkdir)中会非常短暂地使用。能够中断进程以发送数据显然非常有用,并且是在CPU体系结构级别实现的。您的CPU是如何实现这一点的?
因为网络套接字大多被阻塞,并且没有准备好读取或写入,所以EPOLL在服务器上通常是相当快的。我们从O(我们感兴趣的所有FDS)到O(我们感兴趣的FDS中,只有准备好的FDS)时间复杂度,基本上是O(1)。
我们现在要做的是数据通过网络输入,进行多路复用,这样我们的服务器就不必担心文件描述符没有准备好操作,然后进行多路分解,这样我们服务器的不同部分就可以处理不同类型的数据。但是,我们获得的数据不是从远程计算机发送给我们的数据,而实际上是告诉我们文件描述符已经准备好的事件。准备好迎接另一个流行语吧。
因为我们只是获得了一个现成的FD流,所以我们的节点处理程序必须让系统调用自己负责读取和写入。这称为反应堆模式服务器。我们可以让操作系统进行读取和写入,并将数据发送到处理程序函数。这是一个代理程序,它需要Linux所缺乏的特定操作系统机制。
值得一提的是,我们如何将FD定义为准备好或未准备好。来自网络套接字的数据到达的速率与我们的函数处理它的速率不同。我们使用一种叫做缓冲器的东西来帮助我们。在EXPRESS中,我们抽象出来的一件事是用户提供的缓冲区。当我们调用read()时,它会一直阻塞,直到数据从套接字下来。当它到达时,它会填满预定大小的缓冲区。当缓冲区已满时,它是“就绪”的。数据由处理程序函数处理,缓冲区被清空,我们等待它再次被填满。写入器发送一个已满的缓冲区,该缓冲区在另一端被消耗时会被清空,当缓冲区为空时,写入操作将停止阻塞。
简单地说,我们已经定义了我们的多路复用器EPOLL。它向我们发送准备好的文件描述符。这是我们的多路分解器解构的事件流,以便我们的处理函数可以处理每个事件。我们可以称此流为非阻塞的,因为我们的服务器不会被等待在另一端写入或读取数据的读或写操作所打扰,并且我们可以在此之前执行其他任务。我们没有触及的两个流行语是异步和事件循环。在第二部分中将详细介绍这些内容,其中我们将详细介绍异步意味着什么,以及节点如何实现其多路分解器。在那之前,保持你的甲板干净!