深度学习所需的矩阵演算
(我们在旧金山大学的数据科学硕士项目任教,还有其他邪恶的项目正在进行。您可能知道Terence是ANTLR解析器生成器的创建者。有关更多材料,请参阅Jeremy的Fast.ai课程和旧金山大学数据学院的深度学习课程的面对面版本。)。
这篇文章试图解释所有你需要的矩阵演算,以便理解深度神经网络的训练。除了您在微积分1中学到的知识外,我们假定没有其他数学知识,并提供链接帮助您在需要的地方更新必要的数学知识。请注意,在开始学习培训和在实践中使用深度学习之前,您不需要理解本材料;相反,本材料面向那些已经熟悉神经网络基础知识并希望加深对基础数学的理解的人。如果你在学习的过程中遇到困难,不要担心-只要回去重读上一节,试着写下一些例子并进行练习即可。如果你仍然被困住了,我们很乐意在forums.fast.ai的理论类中回答你的问题。注意:本文末尾有一个参考部分,总结了这里讨论的所有关键矩阵演算规则和术语。
我们大多数人最后一次看到微积分是在学校,但导数是机器学习的关键部分,特别是深度神经网络,它是通过优化损失函数来训练的。拿起一张机器学习纸或图书馆的文档,比如PyTorch和微积分,就像假期里的远亲一样,尖叫着回到你的生活中。而且它不是任何老式的标量微积分-你需要微分矩阵微积分,它是线性代数和多元微积分的结合体。
嗯..。也许需要这个词不合适;杰里米的课程展示了如何成为世界级的深度学习实践者,只需最低水平的标量微积分,这要归功于利用现代深度学习库中内置的自动区分功能。但是,如果你真的想要真正了解这些图书馆背后发生了什么,并阅读讨论模型训练技术最新进展的学术论文,你将需要了解矩阵微积分领域的某些知识。
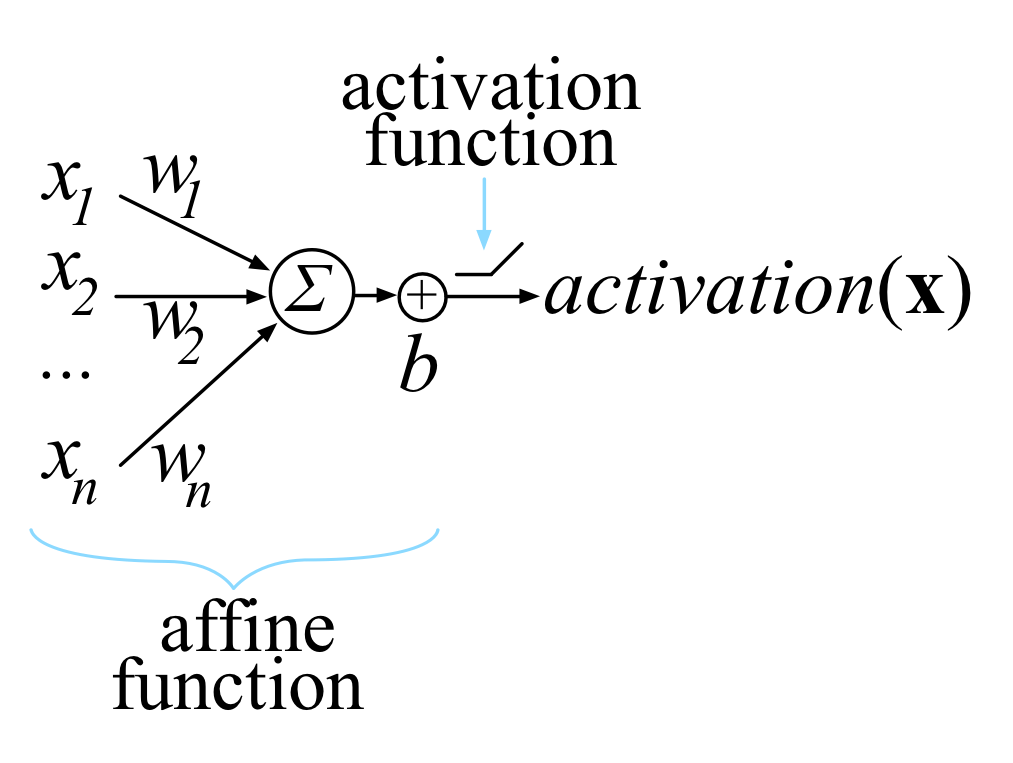
例如,神经网络中单个计算单元的激活通常使用边权重向量w与输入向量x加上标量偏差(阈值)的点积(来自线性代数)来计算:函数被称为单位的仿射函数,后面跟着一个校正的线性单位,它将负值修剪为零:。这样的计算单元有时被称为“人造神经元”,看起来像:
神经网络由许多这样的单元组成,这些单元被组织成多个神经元集合,称为层。激活一层的单位就成为下一层单位的输入。最后一层中的一个或多个单元的激活称为网络输出。
训练这个神经元意味着选择权重w和偏置b,以便我们得到所有N个输入x的期望输出。为此,我们最小化一个损失函数,该损失函数将网络的最终结果与所有输入x矢量的(期望输出x)进行比较。为了使损失最小,我们在梯度下降上使用了一些变化,如平坦随机梯度下降(SGD)、带动量的SGD或ADAM。所有这些都需要对模型参数w和b的偏导数(梯度)。我们的目标是逐渐调整w和b,以便总损失函数在所有x个输入上保持较小。
如果我们细心,我们可以通过微分普通损失函数的标量形式(均方误差)来导出梯度:
但这只是一个神经元,神经网络必须同时训练所有层中所有神经元的权重和偏差。因为有多个输入和(潜在的)多个网络输出,我们确实需要函数对向量的导数的一般规则,甚至需要向量值函数对向量的导数的规则。
这篇文章介绍了一些计算向量偏导数的重要规则的推导,特别是那些对训练神经网络有用的规则。这个字段被称为矩阵微积分,好消息是,我们只需要该字段的一个很小的子集,我们在这里介绍。虽然网上有很多关于多元微积分和线性代数的材料,但它们通常是作为两门独立的本科课程教授的,所以大多数材料都是孤立地对待它们。讨论矩阵演算的页面通常只是规则列表,解释最少,或者只是故事的一部分。由于它们使用密集的记数法和对基本概念的极少讨论,除了少数数学家外,它们往往对所有人都相当晦涩难懂,这要归功于它们使用密集的记数法和对基本概念的极少讨论。(请参阅末尾的带注释的资源列表。)。
相比之下,我们将重新推导和重新发现一些关键的矩阵微积分规则,以努力解释它们。原来矩阵演算真的没那么难!没有几十条新规则需要学习,只有几个关键概念。我们希望这篇短文能让你在矩阵微积分领域快速入门,因为它与训练神经网络有关。我们假设您已经熟悉了神经网络结构和培训的基础知识。如果您不是,请前往杰里米的课程并完成第一部分,当您完成后,我们将在这里与您会合。(请注意,与许多其他学术方法不同,我们强烈建议首先学习在实践中训练和使用神经网络,然后学习基本的数学知识。有了上下文,数学就会变得更容易理解;此外,成为一名有效的实践者并不需要摸索所有这些微积分。)。
关于符号的说明:Jeremy的课程只使用代码而不是数学符号来解释概念,因为代码中不熟悉的函数很容易搜索和实验。在这篇论文中,我们做了相反的事情:有很多数学符号,因为这篇文章的目标之一是帮助你理解你将在深度学习论文和书籍中看到的符号。在文章的末尾,您将找到所用符号的简明表,其中包括您可以用来搜索更多详细信息的单词或短语。
希望您能记住其中一些主要的标量导数规则。如果你的记忆力有点模糊,看看可汗学院的标量导数规则。
你可以在可汗学院的微积分课程中找到关于三角、指数等的其他规则。
当一个函数只有一个参数时,您将经常看到并用作的速记。我们建议不要使用此表示法,因为它没有明确说明我们要对其进行导数的变量。
您可以将其视为将一个参数的函数映射到另一个函数的运算符。这意味着映射到它关于x的导数,这和。还有,如果,那么。将导数视为运算符有助于简化复杂的导数,因为运算符是可分配的,并允许我们提取常量。例如,在下面的等式中,我们可以取出常量9,并将导数运算符分布在括号内的元素上。
这个过程将的导数简化为一些算术运算,以及x和的导数,它们比原来的导数更容易求解。
神经网络层不是单个参数的单一函数。因此,让我们继续讨论多个参数的函数,例如。例如,xy的导数是多少(即x和y的乘积)?换句话说,当我们摆动变量时,乘积xy是如何变化的?这取决于我们是改变x还是y,我们一次计算一个变量(参数)的导数,给出这个两参数函数的两个不同的偏导数(一个是x的,一个是y的)。不使用运算符,而是使用偏导数运算符(样式化为d,而不是希腊字母)。所以,和是xy的偏导数;,通常,它们被称为偏导数。对于单参数函数,运算符等价于(对于足够光滑的函数)。但是,最好使用它来清楚地表明您指的是标量导数。
关于x的偏导数就是通常的标量导数,简单地将方程中的任何其他变量视为常数。考虑一下功能。写出关于x的偏导数。从的角度看有三个常量:3、2和y。因此,。关于y的偏导数将x视为常数:。在继续之前自己派生这些是个好主意,否则这篇文章的其余部分就没有意义了。如果你需要帮助,这是可汗学院关于部分音乐的视频。
为了清楚地表明我们正在做矢量微积分,而不仅仅是多元微积分,让我们考虑一下我们如何处理偏导数和(换句话说,是和)我们计算的。与其让它们漂浮在周围,没有以任何方式组织起来,不如让它们组织成一个水平矢量。我们称此向量为的梯度,并将其记为:
所以的梯度只是它的分项的向量。渐变是矢量微积分世界的一部分,它处理将n个标量参数映射到单个标量的函数。现在,让我们疯狂起来,同时考虑多个函数的导数。
当我们从一个函数的导数转移到多个函数的导数时,我们就从矢量微积分的世界转移到了矩阵微积分的世界。让计算两个函数的偏导数,这两个函数都有两个参数。我们可以保留上一节的内容,但我们也要加进去。G的梯度有两个条目,每个参数都有一个偏导数:
梯度矢量组织特定标量函数的所有偏导数。如果我们有两个函数,我们也可以通过堆叠梯度将它们的梯度组织成一个矩阵。当我们这样做时,我们得到了雅可比矩阵(或仅仅是雅可比),其中梯度是行:
请注意,表示雅可比的方式有多种。我们使用的是所谓的分子布局,但很多论文和软件都会使用分母布局。这只是分子布局雅可比的转置(围绕其对角线进行翻转):
到目前为止,我们已经看了一个雅可比矩阵的具体例子。要更一般地定义雅可比矩阵,让我们将多个参数组合成单个向量变元:。(您有时还会在文献中看到矢量的符号。)。像x这样的粗体小写字母是矢量,而像x这样斜体字体的小写字母是标量。Xi是向量x的元素,并且是斜体的,因为单个向量元素是标量。我们还必须定义矢量x的方向。我们将假定所有矢量在默认大小下都是垂直的:
对于多个标量值函数,我们可以将它们组合成一个向量,就像我们对参数所做的那样。假设是由m个标量值函数组成的向量,每个函数都有一个长度为x的向量x,其中是x中元素的基数(计数)。f内的每个f i函数返回一个标量,与上一节相同:
这是非常常见的情况,因为对于x向量的每个元素,我们都会有一个标量函数结果。例如,考虑Identity函数:
在这种情况下,我们有函数和参数。不过,一般而言,雅可比矩阵是所有可能的偏导数(m行和n列)的集合,它是关于x的m个梯度的堆栈:
每一个都是水平n向量,因为偏导数相对于长度为的向量x。如果我们对x取偏导数,则雅可比的宽度是n,因为我们可以摆动n个参数,每个参数都可能改变函数的值。因此,对于m个方程,雅可比矩阵始终为m行。它有助于直观地考虑可能的雅可比形状:
单位函数WITH的雅可比具有n个函数,并且每个函数具有保存在单个向量x中的n个参数。因此,雅可比是一个方阵,因为:
在继续之前,请确保您可以派生出上面的每一步。如果遇到问题,只需单独考虑矩阵的每个元素,然后应用通常的标量导数规则即可。这是一个通常有用的技巧:将向量表达式缩减为一组标量表达式,然后取所有的分数,最后将结果适当地组合成向量和矩阵。
还要注意跟踪矩阵是垂直的、x的还是水平的,其中x表示转置。还要确保注意某个对象是标量值函数,还是函数的向量(或向量值函数)。
向量上的按元素二进制操作(如向量加法)很重要,因为我们可以将许多常见的向量操作(如向量与标量的乘法)表示为按元素的二进制操作。我们所说的“基于元素的二元运算”只是指将运算符应用于每个向量的第一项以获得输出的第一项,然后将运算符应用于输入的第二项以获得输出的第二项,依此类推。例如,这就是默认情况下在Numpy或TensorFlow中应用所有基本数学运算符的方式。深度学习中经常出现的示例是AND(返回一个由1和0组成的向量)。
我们可以用记号WHERE来概括按元素的二元运算。(提醒:是x中的项目数。)。符号表示任何元素运算符(如),而不是函数复合运算符。下面是当我们放大检查标量方程式时,方程式是什么样子的:
其中,我们垂直写出n(而不是m)等式,以强调这样一个事实,即按元素的运算符的结果给出大小的向量结果。
使用上一节中的思想,我们可以看到关于w的雅可比矩阵的一般情况是方阵:
这是一个相当多的毛球,但幸运的是,雅可比经常是一个对角矩阵,一个矩阵,除了对角线,在任何地方都是零。因为这极大地简化了雅可比,让我们详细研究一下什么时候雅可比降为对角线矩阵进行逐个元素运算。
在对角线雅可比中,对角线外的所有元素都是零,其中。(请注意,我们取的是关于wj的偏导数,而不是关于wi的偏导数。)。在什么条件下这些非对角线元素为零?确切地说,当f_i和g_i关于wj,不管运算符是什么,如果这些偏导数归零,那么不管是什么运算,运算都归零,常数的偏导数为零。
当fi和gi不是wj的函数时,这些分项变为零。我们知道,按元素运算意味着fi纯粹是wi的函数,gi纯粹是xi的函数。例如,求和。因此,归并到和目标就变成了。并且看起来像是偏微分算子相对于wj的常数,当偏导数离对角线为零时。(从技术上讲,符号是对符号的滥用,因为fi和gi是向量的函数,而不是单个元素。我们真的应该写一些类似的东西,但那样会使方程式变得更加混乱,而且程序员可以轻松地重载函数,所以无论如何我们都会继续使用这种表示法。)。
我们稍后将利用这种简化,并将最多访问和访问的约束分别称为逐元素对角线条件。
(大的“0”是一个缩写,表示所有非对角线都是0。)。
因为我们做了很多简单的向量运算,所以二元元素运算中的一般函数往往就是向量w,任何时候一般函数都是一个向量,我们知道它会化为。例如,矢量加法符合我们的逐元素对角线条件,因为它的标量方程仅用偏导数表示:
这就给出了单位矩阵,因为沿对角线的每个元素都是1,我表示合适维数的平方单位矩阵,除了对角线,其他地方都是0,它包含所有的1。
考虑到这种特殊情况的简单性,归结为,您应该能够推导出向量上常见的按元素二进制运算的雅可比:
和运算符是基于元素的乘法和除法;有时称为Hadamard积。目前还没有标准的元素乘除表示法,所以我们使用的方法与一般的二进制运算表示法一致。
当我们将标量与向量相乘或相加时,我们隐式地将标量扩展为向量,然后执行按元素的二进制操作。例如,将标量z与向量x相加,实际上是AND。(符号表示适当长度的向量。)。Z是不依赖于x的任何标量,这很有用,因为对于任何x,i,这将简化我们的偏导数计算。(可以将变量z视为我们在这里讨论的常量。)。类似地,乘以标量,实际上是两个向量的逐元素乘法(Hadamard积)。
向量标量加法和乘法相对于向量x的偏导数使用我们的逐元素规则:
这是因为函数和显然满足我们的雅可比的逐元素对角线条件(最多引用xi,并且引用向量值)。
使用标量偏导数的常用规则,我们得出矢量标量加法的雅可比对角线元素如下:
然而,计算相对于标量参数z的偏导数会得到垂直向量,而不是对角矩阵。矢量的元素包括:
矢量-标量乘法的雅可比矩阵的对角元素涉及标量导数的乘积规则:
相对于标量参数z的偏导数是垂直向量,其元素为:
求出向量的元素是深度学习中的一项重要操作,例如网络损失函数,但我们也可以将其用作简化向量点积的导数计算和其他将向量降为标量的操作。
让我们来吧。注意,我们在这里小心地将参数保留为向量x,因为每个函数f,i都可以使用向量中的所有值,而不仅仅是x,求和的结果是函数的结果,而不是参数。矢量求和的梯度(雅可比)为:
(渐变元素内部的求和可能比较棘手,因此请确保记数法保持一致。)。
让我们来看看简单的渐变。求和中的函数为正,梯度为:
请注意,结果是一个充满1的水平向量,而不是垂直向量,因此渐变是。(的T指数表示指示向量的转置。在这。
.