在ext4中使用Linux内核的不区分大小写特性
Linux5.2是在一年多前发布的,随之而来的是在ext4文件系统中添加了一个新特性来支持优化的不区分大小写的文件名查找--这是第一个这样做的原生Linux文件系统。现在,在这个颇具争议的功能推出一年后,Collabora和其他公司继续在它的基础上进行构建,使其对系统开发人员和最终用户越来越有用。因此,现在似乎是一个很好的时机来看看为什么合并,以及如何将其付诸实施。
最近,由于Google的努力,在ext4实现和框架之后,F2FS也开始支持这一特性。此处描述的大部分(如果不是全部)信息也适用于F2F,但对用于配置超级块的命令稍有更改。
文件名是用于在目录层次结构的特定级别唯一标识文件(在此上下文中,目录与文件相同)的文本字符串。虽然从操作系统的观点来看,文件名是什么并不重要,只要它是唯一的,有意义的文件名对最终用户来说是必不可少的,因为它是定位和检索数据的主要关键。换句话说,有意义的文件名是人们用来查找有价值的文档、图片和电子表格的依据。
传统上,Linux(和Unix)文件系统总是将文件名视为不透明的字节序列,没有任何特殊含义,要求用户提交与文件完全匹配的文件才能在文件系统中找到它。但这不是人类的运作方式。当人们写标题时,重要报告和重要报告通常指的是同一条数据,而你在创建它时并不关心它是如何写的。我们关心的是重要和报告这两个词的内容和语义。
在英语中,一个单词的不同拼写唯一表示相同意思的情况是处理大写和小写,但对于其他语言,情况并非如此。一些语言有不同的脚本来表示相同的信息,对于用户来说,在以后检索数据时不关心文件最初的标题是哪种不同的书写系统是有意义的。
过去,用户空间应用程序已经解决了这些语言差异中的大多数,但是将这些知识引入内核使我们能够解决从其他操作系统(如windows Games)移植的应用程序的重要瓶颈,这些应用程序不能简单地重新编译以理解它在Linux上运行,并且文件系统现在区分大小写。事实上,让内核理解语言规范化和案例折叠的过程可以让我们优化我们的磁盘存储,这样系统就可以快速检索所请求的信息。最终结果很明显:为最终用户提供了一个更加用户友好的Linux体验,以及一个更好的平台,可以在Linux上使用Steam运行心爱的Windows游戏。
在启用它之前,请确保您的内核支持不区分大小写的ext4,并且支持您计划使用的编码版本。
如果内核是用config_unicode=y构建的,那么它支持不区分大小写的ext4。如果您不确定,可以通过读取下面的sysfs文件在引导的内核上进行验证。如果它不存在,则不区分大小写没有编译到您的内核中。
目前,内核最高支持12.1版的UTF-8。Mkfs将始终选择最新版本,但是尝试使用比内核支持的UTF-8版本更新的版本运行文件系统是有风险的,并且为了保存您的数据,内核将拒绝挂载这样的文件系统。要解决此问题,需要更新内核,或者可以将mkfs配置为使用旧版本。
补丁排队等待下一个版本,以便内核在sysfs上报告Unicode的最新受支持版本。请注意,即使CONFIG_UNICODE存在,以下文件也可能在您的系统中不可用。
首先,在启用";之前,请确保您已经阅读了第#34;节。如果不遵循这些说明,可能会使您的文件系统在当前内核中无法挂载。
要启用该功能,需要两个步骤:第一步是在卷的超级数据块上启用文件系统范围的案例折叠功能。这不会立即使任何目录不区分大小写,所以不用担心,但它会使磁盘准备好支持案例折叠目录。它还配置将使用的编码。
第二步是将特定目录配置为不区分大小写。但首先,让我们看看如何创建支持不区分大小写的磁盘。
之后,在挂载文件系统时,您可以验证文件系统是否正确具有以下功能:
$dumpe2fs-h/dev/vda|grep';文件系统功能'; 转储2fs 1.45.6(2020年3月20日) 文件系统功能:has_Journal ext_attr resize_inode dir_index文件类型范围 64位FLEX_BG案例折叠稀疏超大文件巨型文件目录nlink Extra_isize METADATA_CCUM。
如果上面一行包含特性';case';,则在文件系统的/dev/vda中启用该特性。
$mount/dev/vda/mnt $dmesg|尾部 EXT4-fs(VDA):使用带有标志0x0的超级块定义的编码:utf8-12.1.0 EXT4-fs(VDA):使用有序数据模式挂载的文件系统。选项:(空)。
从历史上看,除尾部斜杠(';/';)和空字节(';\0';)之外的任何字节都是文件名的有效部分。这是因为Unix文件系统将文件名视为一系列斜杠分隔的组件,这些组件只是不透明的字节序列,没有赋予它们任何意义。更高级别的用户空间软件通过将它们视为用于渲染的角色来赋予它们意义。然而,当谈论不区分大小写时,内核需要检查并理解字符的真正含义以及大小写折叠的规则是什么。这就是我们在内核中采用编码的原因,就像我们对UTF-8所做的那样。但是,对于人们可能选择的任何编码,什么是有效名称的要求要严格得多。事实上,有几个序列在UTF-8中完全是无效文本。当程序要求内核创建具有这些名称的文件时,内核需要决定是以某种方式假装该名称是有效的,还是向应用程序抛出错误。
绝大多数应用程序不关心是否区分大小写,只要是有效的Unix名称,文件名就会被接受。如果内核在它们期望的有效名称上抛出错误,这些应用程序将失败,因此,默认情况下,如果应用程序试图在不区分大小写的目录上使用无效名称,内核将任由其发生,并将该单个文件视为不透明的字节序列。这很好,但是不区分大小写并不只适用于该文件。
另一方面,在某些情况下,我们希望严格控制文件系统接受的内容。把坏文件名和好文件名混合在一起是令人困惑的,并且为程序的不正常行为提供了空间。不过,对于这些用户,ext4有一个严格模式,它会导致创建或重命名带有错误名称的文件的任何尝试失败,并向应用程序返回错误。
如果一切正常,并且tune2fs返回时没有任何错误,则下次挂载此文件系统时,内核日志将显示类似以下行的内容:
$mount/dev/sda1/mnt $dmesg|尾部 Ext4-fs(Sda1):使用带有标志0x0的超级块定义的编码:utf8-12.1.0。
它有两条重要的信息。第一个是使用的编码,在上面的示例中,它是支持Unicode规范版本12.1.0的UTF-8。第二部分信息是标志参数,在本例中为0x0,它在处理案例折叠目录时修改文件系统的行为。
在编写本文时,唯一支持的标志是严格模式,在这种情况下,标志掩码将为0x1。
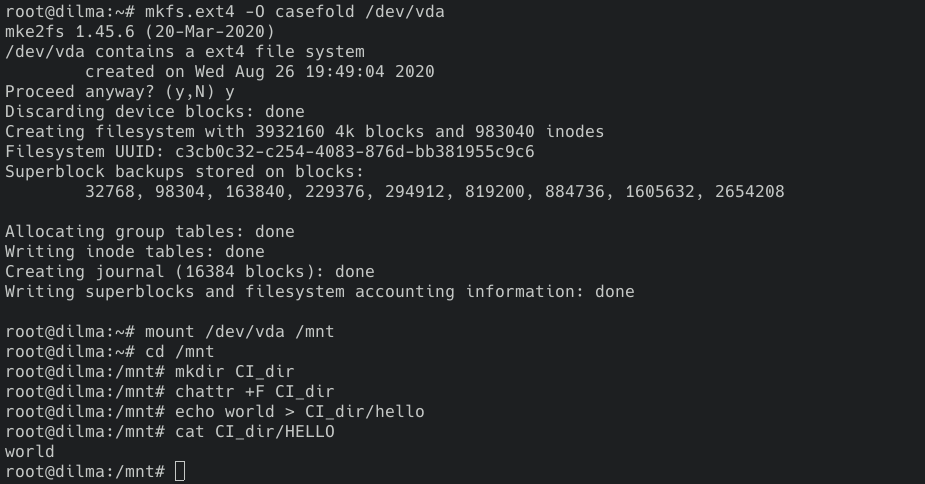
装载启用了不区分大小写的文件系统后,现在可以翻转空目录中的';Casefold';inode属性(';+F';),以使其中的文件查找不区分大小写:
启用该设置后,以下命令应该会成功,而不是最后一个命令返回没有这样的文件或目录。";
可以使用lsattr验证目录区分大小写。例如,在下面的示例中,F字母表示CI_dir目录不区分大小写。
要恢复设置并再次使配置项目录不区分大小写,必须清空目录,然后删除CaseFold属性:
$RM CI_dir/* $chattr-F配置项目录 $Isattr. -./CS_dir -./CI_dir -/丢失+找回。
要求目录为空来翻转不区分大小写的标志有点烦人,但这是目前的技术要求,将来不太可能改变。事实上,要以区分大小写的方式访问不区分大小写的目录的数据,将其移动到新目录会容易得多:
$mkdir配置项目录 $chattr+F配置项目录 $mkdir配置项目录/foo $lsattr配置项目录 -F-CI_dir/foo。
$mkdir配置项目录 $chattr+F配置项目录 $mkdir配置项目录/foo $chattr-F foo $Isattr. -F-CI_DIR $lsattr配置项目录 -CI_dir/foo
但是,请记住,在上面的示例中,命令的顺序很重要,因为如果目录不为空,则不能翻转其CaseFold属性。
目前,只支持UTF-8编码,我不知道是否有计划将其扩展到更多编码。由于编码压缩的原因,对于说东方语言的人来说,不同的编码方式很有意义,但我不知道目前有谁在Linux上从事这方面的工作。
如上所述,Linux实现在比较字符串之前执行规范分解标准化过程。这意味着可以使用不同的规范化名称正确搜索规范等价的字符。例如,在一些语言(如德语)中,字母«(Eszett)的大写形式是SS(或U+1E9Eẞ拉丁文大写字母Sharp S)。因此,对于讲德语的人来说,使用字符串";flss";查找名为";flo";(RAFT,英文)的文件是有意义的:
还有多种组合重音字符的方法。例如,我们的方法确保了单词café(葡萄牙语中的咖啡)的多个编码可以在一个案例折叠查找中互换。
让我们看看很酷的东西吧。要使其正常工作,您可能需要复制粘贴下面的命令,而不是键入它。让我们创建一些文件:
Ext4中实现的不区分大小写的特性是一种非侵入性机制,可以为需要该特性的用户提供支持,同时将对其他应用程序的影响降至最低。考虑到每个目录的性质,在文件系统范围内启用功能位并让应用程序根据需要在目录上启用它是安全的。它使用简单,对于以前必须在用户空间中模拟它的用户空间应用程序,应该会产生更高的性能。
你怎么知道文件名是用哪种语言写的? 例如,i.txt和i.txt文件通常是相同的,但前提是您知道它们不是用土耳其语编写的。
嗨,很棒的文章!我猜自从你在LinuxDev BR的演讲之后,变化不大! `mv ci_dir/*`命令中有一个拼写错误,您缺少目标目录。
嗯,怎么了?这样你就可以像Windows一样了?这太傻了。这将使脚本和自动化成为一场噩梦,就像文件名中的空格一样。这是一个寻找问题的解决方案……。
不过,Windows NTFS区分大小写。它只是通过用户空间限制不敏感。这怎么会让事情变得混乱呢?不是正好相反吗?我知道这个角色让剧本变得很脏,但我不会说它是一场噩梦来匹配命名tho,这是区分大小写的事情。
任何人都依赖于不区分大小写这一事实意味着糟糕/懒惰的编码。即使是日常使用,这也不是什么问题。软件不加载文件...。只需正确拼写文件名即可。显式比隐式好,诸如此类。让我们希望这不是默认在发行版中启用的。再说一次,这是一个寻找实际问题的解决方案。
因此,我们从导入到Linux内核的CP/M和DOS文件名选择中得到了40年前的糟糕设计选择。
不反对,想用的人就用吧。让我们把两者混合起来吧。那些促成它的人,让他们承受后果。而其他人则可以继续以其应有的方式使用Linux。这是区分大小写的。我不确定当我们学习POSIX时,我们学到的是区分大小写的文件系统。作者的意图是区分大小写。我不想让它出现在我的任何服务器上。我不想为了某个麻木不仁的神经病破坏我的环境。
这怎么会是一种障碍呢?允许您使用糟糕的编码样式,还是必须使用正确的文件名?
与竞争对手相比,我们更喜欢Linux有几个原因。其中之一是区分大小写的文件名。这是一个巨大的倒退。
如果它在主流发行版中启用,似乎这将是一次重大的倒退。我就是不明白这一点。目前,这在用户空间中得到了很好的处理。我在zsh上使用不区分大小写的搜索和自动完成,从来没有出现过问题。在一些非拉丁语言中,这听起来可能是一个更重要的问题,我当然会支持为那些用户解决这个问题,但不是每个人。
这是一个愚蠢的理由,要在内核中构建整个语义,还要考虑到任何问题。语言没有大小写的概念。通过不区分大小写的文件名搜索,可以很容易地处理从语义上查找文件的用例。如果对熟悉POSIX区分大小写的人启用此功能,将是一种刺激。
要实现这种逆行验证,需要破解内核吗?通过不区分大小写的文件名搜索,可以很容易地实现所述用例通过语义查找我的文件。如果在POSIX用户不知情的情况下激活,甚至在事先通知的情况下激活,这将会刺激来自POSIX的用户。
这是我今年读过的最愚蠢和最邪恶的东西。Linux一天比一天糟糕。
请勾选此框以确认您已阅读并接受我们关于收集/存储和使用您的个人数据的隐私声明条款:*