作为合同的列名
软件产品使用一系列策略与其用户作出承诺或签订合同。成熟的代码包和API记录预期的输入和输出,检查单元测试的遵从性,并透明地报告代码覆盖率。具有图形用户界面的程序通过交互式组件上的标签和图标来形成此合同,这些标签和图标解释了它们的意图(例如,“保存”按钮通常不会批量删除文件)。
然而,已发布的数据表存在一个模糊的灰色区域;静态到不能被认为是“服务”或“软件”,但又太原始,不能赢得对界面用户体验的关注。这种模棱两可可能会在数据生产者和消费者之间产生一种奇怪的共生关系。生产者可以发布系统可以访问的或看起来相关的任何数据,而消费者可能很快就会认为“听起来正确”的表格或字段恰好是适合他们头等大事的定制的。
元数据管理解决方案旨在解决这个问题,在这个领域有很多有前途的开发,包括Lyft的Amundsen、LinkedIn的DataHub和Netflix的Metacat。然而,元数据解决方案通常需要很大程度的合作:生产者必须警惕地维护文档,消费者必须仔细检查它-尽管这样的工具几乎不在任何一方的核心工具包和工作流程之外。
将受控词汇表用于列名是一种低技术、低摩擦的方法,可以共同理解数据集中每个字段的工作方式。在这篇文章中,我将用一个例子介绍这个概念,并演示受控词汇表如何为死记硬背的数据验证、可发现性和争论提供轻量级的解决方案。我将用R包来说明这些可用性方面的好处,包括PointBlank、CavlsibleTree和dplyr,但我们将通过演示如何将相同的原则应用于其他包和语言来结束。
受控词汇表的基本思想是预先定义一组含义明确的词、短语或存根,这些词、短语或存根可用于索引信息。当这些存根被定义为不同类型的信息并以一致的顺序组合在一起时,词汇表就变成了描述性语法,我们可以使用它来描述更复杂的内容和行为。
在数据集的上下文中,该词汇表还可以充当数据生产者和数据消费者之间的潜在契约,并提供关于数据谱系的不同方面、有效值和适当用途的承诺。当在组织的所有表中一致使用时,它可以显著扩展数据管理并提高可用性,因为使用一个数据集的知识很容易转移到另一个数据集。
例如,假设我们在一家拼车公司工作,并且正在构建一个每次旅行只有一条记录的数据表。受控词汇表可能是什么样子的?1。
出于示例中显而易见的原因,我希望层次结构的第一级通常捕获变量的半泛型“类型”。这与编程语言中的数据类型(例如,bool、Double、Float)并不完全相同,尽管具有相同前缀的所有内容最终都应该转换为相同的类型。相反,这些数据类型暗示了一种信息类型和适当的使用模式:
ID:实体的唯一标识。数字表示更高效的存储和连接,除非记录系统生成带有字符的ID。
IND:二进制0或1指示符或事件发生可以考虑调用IS而不是IND,以减少歧义,这种情况被标记为1。
金额:可求和实数金额。也就是说,任何“无分母”的非计数金额。
Val:本质上不能求和的数值变量,例如,不能组合的比率和比率,或者像纬度和经度这样的典型算术运算没有意义的数值。
虽然这些都是相对通用的,但也可以使用特定于领域的类别。例如,由于位置对拼车非常重要,因此将ADDR列为1级类别可能是值得的。
最佳层次结构因行业和数据库的整体内容而变化很大,而不仅仅是一个表。在这里,我们希望对许多不同主题的Trip属性感兴趣:骑手、司机、Trip等等,因此度量主题可能是逻辑上的下一层。我们可以定义:
成本:关于总成本组成部分的信息(可能是行程的子集,但与所有各方相关,并且在下一层具有很高的基数,因此我们将其细分)。
当然,在高度规范化的数据库中,这些不同实体的度量将存在于不同的表中。然而,命名它们的这一原则仍然是有益的,因此当分析师组合它们时,数量是毫不含糊的。
该层次结构的前几层对于标准化、做出我们的“性能承诺”以及帮助数据可搜索性是至关重要的。以后的水平将是特定于衡量标准的,可能不值得预先定义。但是,对于将存在于多个表中的概念,有必要预先指定它们的名称和精确格式。例如:
City:这个应该全部大写吗?应该如何对待城市名称中的空格?
纬度/LON:纬度和经度应该地理编码到多少位小数?如果该公司仅在某些地理区域(例如美国大陆)运营,则可以确定这些区域的粗略界限。
末尾的“形容词”也可以考虑。例如,如果数据生成系统吐出分析上不理想的数量,这些数量应该保留用于数据沿袭目的,则后缀(如_raw和_lean)可能分别表示同一变量在其原始状态和修剪状态下的版本。
N_Trip_{Passenger|ORIG|DEST}行程的唯一乘客数、上下车点数。
AMT_COST_{TIME|DIST|基数|费用|激增|提示}:每个成本构成的金额。
CAT_TRIP_TYPE:行程类型,如‘Pool’、‘Standard’、‘Elite’
Cat_rider_type:骑手状态,如‘BASIC’、‘FREQUENCE’、‘SUBSCRIPTION’
Addr_{orig|dest}_{Street|City|state|ZIP}:行程开始和结束的地址组件。
Val_{ORIG|DEST}_{LAT|LON}:行程起止的纬度和经度。
我们可以用大约三分之一的行数来描述35个变量,这一事实已经说明了这种结构在帮助数据消费者构建强大的心理模型以快速操作数据方面的价值。但现在我们可以展示更大的价值。
首先,我们使用我们的模式创建一个小的假数据集。为简单起见,我模拟上面列出的35个变量中的18个:
Head(Data_Trips)#>;ID_Driver ID_Rider ID_Trip DT_ORIG DT_DEST N_Driver_Passenger#>;1 3133 1931 2111 2019-11-28 2019-11-28 1#>;2 2814 3447 8774 2019-01-27 2019-01-27 2#>;3 6228 5307 3579 2019-08-20 2019-08-20 1#>;4 8662。6 1082 4283 1932 2019-04-05 2019-04-05 1#>;N_TRIP_ORIG N_TRIP_DEST AMT_TRIP_DIST IND_TRAP VAL_DRIVER_RATING#>;1 1 1 17.20903 1 4.563146#>;2 1 1 48.61153 1 1.821682#>;3 1 1 15.84176 0 2.547830#>;4 1 1 32.53479 1 2.197225#>;5 1 1 46.78174 0 1.811439#>;ValRIDER_RATING VAL_ORIG_LAT VAL_ORIG_DEST_LAT VAL_ORIG_LON VAL_DEST_LON#>;1 3.910203 41.03484 41.03484 41.05040 108.57596 114.66087#>;2 3.082977 41.83536 41.14015 91.37160 90.74377#>;3 1.263818 40.26959 40.07620 88.81886 77.41221#>;4 2.740829 41.35613 40.48563 103.01865 91.60560#>;6 1.589261 41.13615 40.72645 79.85532 115.38686#>;CAT_Trip_TYPE CAT_RIDER_TYPE#&>;1精英常客#&>2精英基础#&>3泳池常客#&>4标准常客#&>5标准常客#&>6常客#&>6。
变量名中的“承诺”不仅仅是用来装饰的。它们实际上可以帮助生产商发布更高质量的数据,帮助实现数据验证检查的自动化。数据质量是特定于上下文的,需要用户端的努力,但在任何数据管道中设置保护措施都可以帮助检测和消除常见错误,如重复或损坏的数据。
当然,设置数据验证管道并不是任何数据工程师工作中最令人兴奋的部分。但这就是R的PointBlank包的用武之地,它提供了一种优秀的特定于领域的语言,用于常见的断言数据检查。将此语法与dplyr';的“选择帮助器”(如starts_with())相结合,相同的验证管道可以确保在不增加额外开销的情况下遵守许多数据承诺。例如,N_COLUMNS应严格为非负数,IND_COLUMNS应始终为0或1。
下面的示例演示了在pointblank中编写这样一个管道的R语法,但是该包还允许在独立的YAML文件中指定规则,这可以进一步提高项目之间的可移植性。
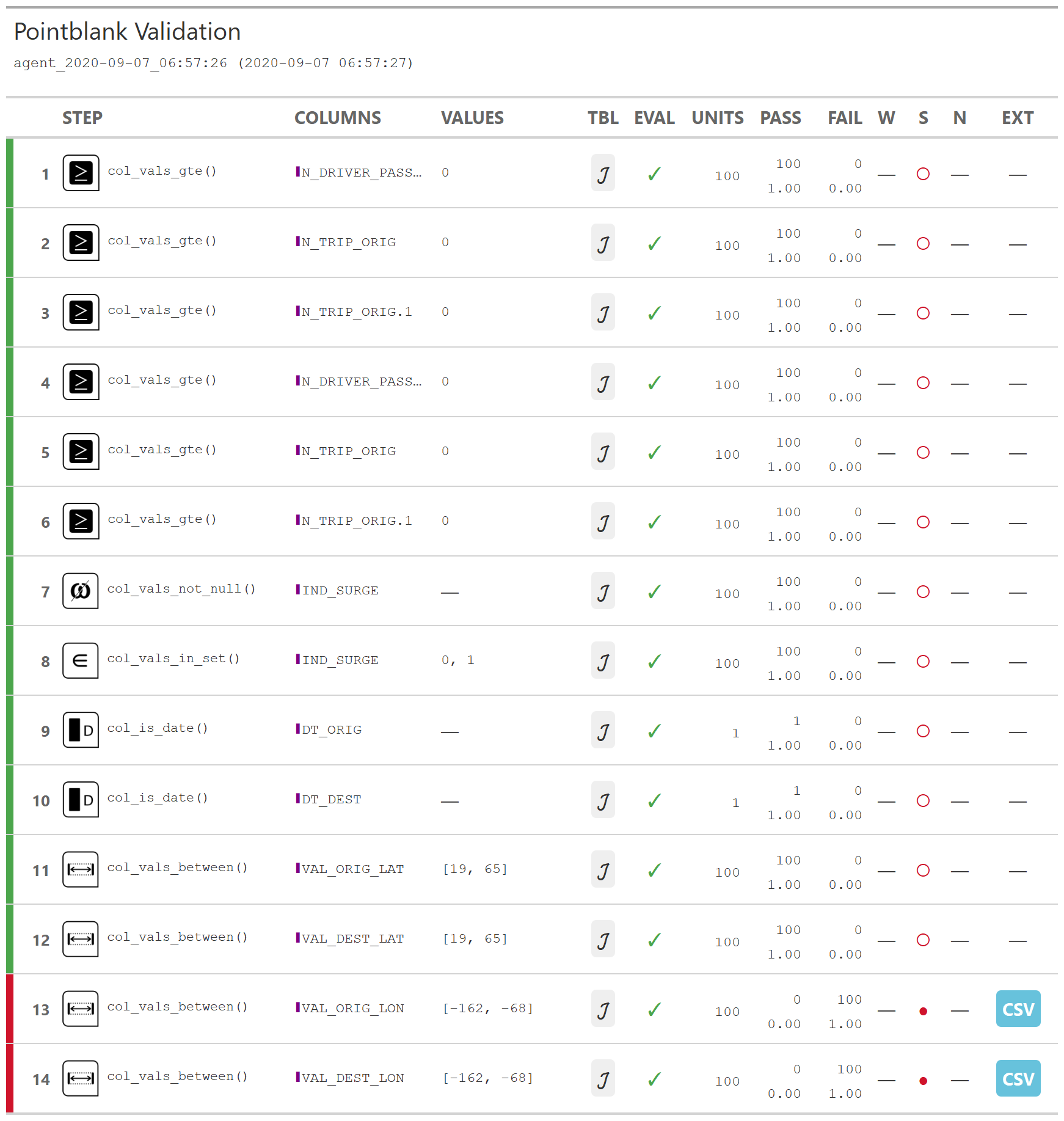
AGENT<;-DATA_TRIPS%>;%CREATE_AGENT(ACTIONS=ACTION_LEVES(Stop_at=0.001))%>;%COL_VALULES_GTE(STARTS_WITH(";N";),0)%>;%COL_VERVERS_NOT_NULL(";IND";)开始(";IND";)%COL_VALULES_NOT_NULL(";IND";)。))%>;%COL_VERVIES_IN_SET(STARTS_WITH(";IND";),c(0,1))%>;%COL_IS_DATE(STARTS_WITH(";DT";))%&gT;%COL_VERVES_BETWEEN(匹配(";_LAT(_|$)";),19,65)%>;%COL_VERVERS_BETWEEN("。_LON(_|$)";),-162,-68)%>;%QUERGATE()。
在上面的示例中,只有7行与表无关的可移植代码最终创建了14个数据验证检查。结果发现了两个错误。经过调查2,我们发现我们的地理编码器错误地翻转了经度上的符号!
您还可以想象自己编写变量名称的Linter或验证器,以检查打字错误、不跟在公共存根后面的离群值等。
在用户端,受控词汇表使新数据更容易浏览。尽管IS不是也不应该取代真正的数据字典,但是想象一下理解以下变量的意图并导航输出可视化的可搜索选项卡是多么容易。
要生成一些可访问的输出,我们可以首先将列名编排到它们自己的表中。
COLS_TRIPS<;-名称(Data_Trips)COLS_TRIPS_SPLIT<;-strSplit(COLS_TRIPS,Split=";_";)COLS_Components<;-data.frame(VARIABLE=COLS_TRIPS,Level 1=VAPPLY(COLS_TRIPS_SPLIT,FUN=Function(X)x[1],FUN.VALUE=character(1)),Level 2=vApply(COLS_Trips_Split,FUN=Function(X)x[2],FUN.VALUE=character(1)),Level3=vApply(COLS_TRIPS_SPLIT,FUN=Function(X)x[3],FUN.VALUE=Character(1。可变级别1级别2级别3#>;1 ID_Driver ID Driver<;NA>;#>;2 ID_Rider ID Rider<;NA>;#>;3 ID_Trip ID Trip<;NA>;#>;4 DT_ORIG DT orig<;NA>;#>;5 DT_DEST DT DEST<;NA>;#>。
因此,元数据的一部分可以使按各种存根进行搜索变得特别容易-无论是度量类型(例如,N或AMT)还是度量主题(例如,骑手或驱动程序)。^[具有可搜索列3的DT输出。
同样,我们可以使用可视化来验证和探索可用字段。下面,数据字段以树的形式显示。
根据正在进行的探索类型,先按测量对象深入可能会更方便。折叠树可以灵活地让我们通过指定层次结构来控制这一点。
这些命名约定对于通过具有自动完成功能的IDE进行“被动搜索”特别友好。简单地键入“N_”并暂停或按Tab键可能会引出数据集中计数变量的潜在选项列表。
更广泛地说,推动这一标准化为变量优先文档提供了有趣的可能性。随着我们描述字段的语法变得更加丰富和不那么模棱两可,用户探索变量优先的数量网络并返回到包含它们的适当表格的可能性越来越大。
受控的、分层的词汇表也让基础数据争论管道变得轻而易举。通过对列名进行编程,我们可以以最相关的方式适当地汇总多条数据。
例如,下面的代码使用dplyr';的“select helpers”来汇总我们可能合理地对总数感兴趣的计数变量,并找出指标变量的算术平均值,以帮助我们计算事件发生的比例(这里是高峰定价的发生率)。
注意我们的受控词汇表和隐含的“合同”给了我们什么。我们不是在总结像纬度和经度这样没有固有意义的字段。相反,如果我们的指标变量可能包含NULL或偶尔使用其他数字(例如,2)来表示浪涌严重程度而不是纯粹的发生率,我们可以自信地计算出我们无法计算的比例。
库(Dplyr)DATA_TRIPS%>;%GROUP_BY(CAT_RIDER_TYPE)%>;%SUMMARY(交叉(STARTS_WITH(";N_";),SUM),交叉(STARTS_WITH(";IND_&34;),Mean))#>;#A Tibble:3 x 5#>;cat_rider_type N_Driver_Passenger N_Trip_orig N_Trip_DestInd。<;Chr&>;<;集成;数据库;#&>;1基本49 32 32 0.406#>;2经常64 42 42 0.548#>;3订阅37 26 26 0.462。
上面的示例使用了几个特定的R包,这些包带有专门对列名进行操作的帮助器。但是,这种方法的价值是语言不可知的,因为大多数用于数据操作的流行语言都支持由变量名列表指定的字符模式匹配和争论操作。我们将用几个例子来结束。
尽管SQL是一种很难“编程”的语言,但许多编程友好的工具都提供了SQL生成器。例如,通过使用dbplyr,我们可以使用R生成SQL代码,该代码按骑手类型汇总我们所有的计数变量,而不必手动键入它们。
库(Dbplyr)df_mem<;-memdb_frame(data_trips,.name=";example_table";)df_mem%>;%group_by(Cat_Rider_Type)%>;%SUMMARM_AT(vars(以(";N_";)开始),sum,na.rm=true)%>;%show_query()#>;<。SELECT`CAT_RIDER_TYPE`,SUM(`N_DRIVER_PASSENGERS`)AS`N_DRIVER_PASSENGERS`,SUM(`N_TRIP_ORIG`)AS`N_TRIP_ORIG`,SUM(`N_TRIP_DEST`)AS`N_TRIP_DEST`#>;from`Example_Table`#&>GROUP BY`CAT_RIDER_TYPE`。
然而,我们当然并不局限于整齐风格的编码。类似地,简明的工作流同时存在于基本语法和数据表语法中。假设我们想要汇总所有数值变量。首先,我们可以使用base::grep查找所有以N_开头的列名。
Aggregate(DATA_TRIPS[COLS_n],BY=DATA_TRIPS[COLS_GRP],FUN=SUM)#>;CAT_RIDER_TYPE N_Driver_Passenger N_Trip_ORIG N_Trip_DEST#>;1 Basic 49 32 32#>;2频繁64 42 42#>;3订阅37 26。
Library(data.table)dt<;-as.data.table(Data_Trips)dt[,lApply(.SD,SUM),BY=COLS_GRP,.SD=COLS_n]#>;CAT_RIDER_TYPE N_Driver_Passenger N_Trip_orig N_Trip_Dest#>;1:频繁64 42 42#>;2:Basic 49 32 32#>;3:订阅37 26。
类似地,我们可以在Python中使用列表理解来创建与特定模式(Cols_N)匹配的列名列表。这个列表和一个定义分组变量的列表可以传递给熊猫的数据操作方法。
如果Vbl[0:2]==';N_&';[COLS_GRP=[";CAT_RIDER_TYPE";]data_trips.groupby(cols_grp)[cols_n].sum()#>;N_Driver_Passenger N_Trip_ORIG N_Trip_DEST#>;CAT_RIDER_TYPE#>;Basic 49 32.0 32.0#>;Frequency 64 42.0 42.0#>;订阅37 26.0 26.0。
同样,词汇表应该跨越数据库-不仅仅是单个数据集,为了简单起见,我们只讨论一个较小的示例。↩︎
Pointblank的输出实际上是一个交互式表格。由于特定于博客的原因,我在这里只显示PNG。↩︎。
与pointBlank一样,dt输出是交互式的,但不幸的是,我的博客对额外的javascript反应不佳,所以现在我只显示一个图像↩︎。