对Http4k、KTOR(Kotlin)和Actix(Rust)微服务进行基准测试
早在2020年春的Goout,我们就希望用一个更轻量级的框架来取代Spring-Tomcatduo来支持我们未来的Kotlin微服务。我们做了一些详细的(有时是哲学上的)理论比较,我非常喜欢,但这些不能替代亲身体验。我们决定使用最可行的框架来实现概念验证微服务,并在此过程中在基准中强调它们。虽然Kotlin是主要语言,但我认为这是一个机会,可以在家里享受一些乐趣,测试(我对Rotlin的熟练程度)。在这个过程中,我们决定使用最可行的框架来实现概念验证微服务。虽然Kotlin是主要语言,但我认为这是一个机会,可以在家里享受一些乐趣,测试(我对Rotlin的熟练程度)。还有Rust的Actix Web,请继续阅读,看看他们的表现如何。
如果你不耐烦的话,可以直接看结果,稍后再看背景资料。
提交的TEB实现往往是相当优化的。我们希望测量这样一种我们通常编写的代码样式:一种是努力做到简单/惯用/可读,但完成得很快,没有广泛剖析;另一方面,我们希望包括生产级API错误处理(正确的HTTP代码和JSON错误消息列出了各个参数的问题等)。
除了高水位请求/秒性能和相关延迟之外,我们还希望捕获更多操作特征,如内存使用率、CPU使用率和效率,以及微服务实例的生命周期。
在生产中,我们在相当高密度的Kubernetes集群中运行我们的微服务,其中每个实例都必须是CPU和内存受限的。我们想要模拟这种环境,并检查我们是否可以将流行的“无服务器”产品用于新服务。
我们的数据存储Elasticsearch与TEB中包含的数据存储不同,我们很好奇Elasticsearch客户端的同步和异步风格如何比较。
有关要实现&;基准的服务的描述,请参阅Locations-rs存储库中提供的API规范文档。
我们对其最简单的/City/v1/GET端点进行了基准测试,该端点的工作是在Elasticsearch中根据id查找城市文档,查找相关的区域文档,并呈现响应JSON。它对区域(只有几十个)使用内部内存缓存,但对更多的城市没有缓存。
为了减少从Elasticsearch获取文档时的带宽,所有实现都指示它剥离(至少)最大的属性几何图形。此属性仅用于Elasticsearch端过滤,微服务不使用。我认为剥离会使Elasticsearch承受很大的压力(或者更确切地说,将压力从微服务传递给它)。
基准测试由BASE-3-impls.py产生的每个Dockerized实现的多个相同的“Run”组成。Run是以实现及其序号命名的,因此rs-Actix-1是Rust(Actix)实现的第一次运行,而kt-KTOR-3是Kotlin(KTOR)实现的第三次运行,因此rs-Actix-1是Rust(Actix)实现的第一次运行,而kt-KTOR-3是Kotlin(KTOR)实现的第三次运行。
每次运行使用test-image.py.一次运行的步骤来模拟微服务实例的前几分钟:
HTTP负载使用WRKIN生成一系列10秒长的步骤,并增加并发连接计数;在每一步之后从WRK和Docker API收集指标:接下来的11步中的每一步都会使并发连接计数加倍,即继续使用2,4,8,…。,1024,2048。1个。
最后,使用Render-tests.py中令人敬畏的Pygal库绘制所有运行,单个实现的不同运行使用相同的颜色,允许直观检查它们之间的差异。
Docker被告知限制微服务容器可用的资源,这是典型的Kubernetes集群中常见的做法。
使用等效的--cpu=1.5 docker选项将CPU限制为1.5个CPU-单位。这意味着即使实例可以访问机器的所有4个CPU核心,它在每个10墙时钟秒的步长中也只能使用15个CPU-秒(理论上是40个CPU-秒)。选择1.5的值足够小,可以确保测试的微服务是基准测试期间的实际瓶颈,并且足够大,足以断言框架可以正确使用多个CPU核心。
内存限制为512 MiB。我认为任何超过512MiB的服务都不应该称为微服务。
两个JVM托管的Kotlin实现运行在OpenJDK 11中,唯一的选项是-XX:MaxRAMPercentage=75,它应该允许JVM将高达75%的可用512MiB内存分配给Java堆。
基准测试在位于同一区域的Google Cloud Platform(GCP)Compute Engine中的2台虚拟机上运行。
第一台VM,n2d-high cpu-4机器类型(4个AMD Epyc Roman vCPU,4 GB内存):由于容器限制为1.5个CPU,而WRK占用的CPU少于剩余的2.5个CPU,它们应该不会相互影响。
第二个虚拟机,e2-定制机器类型(12个高密度vCPU,6 GB内存):短期峰值期间的最大CPU利用率从未超过80%-我已将Elasticsearch CPU核心的数量向上扩展,直到它不再成为瓶颈,达到12个。
我们最初还在Vert.x中实现了Kotlin概念验证,但结果发现没有一个团队成员对此框架建议的编程范例感兴趣(这可能是一个主观问题),所以我们没有继续进行下去。
Http4k位置服务是由GoOut的@Goodhoko编写的,它成为GoOut的生产实现,因此与Swagger服务等附加服务一起是最完整的。
Http4k允许从多个服务器后端中进行选择,因此我们首先需要进行鉴定基准测试,并公平地选择性能最好的引擎。
这个基准测试的一个很好的副作用是,我发现了Netty后端性能问题的原因,@daviddenton很快就解决了这个问题。netty-updfix-*图显示了一些不错的延迟特征,已经包含了修复。它后来在http4k v3.259.0中发布(如果您使用此后端,请务必升级)。
Apache HttpCore 4.4版,标记为apache4-*,是CPU效率最高的后端,在请求/秒峰值性能上取得了共享的第一名。但是,随着并发连接数量的增长,它往往会占用太多内存,一旦它们的数量达到(极端)1024,内存就会耗尽。Apache HttpCore 5.0版(Apache-*)和一个套接字积压较少的变体(Apache-Q100-*)也遇到了同样的问题。我已经打开了一个问题,看看是否会出现这种情况。
本轮资格赛的获胜者是Undertow后端(对于v3.163.0,Undertow-*;对于v3.258.0,Undertow-upd-*),它在高水位Req/s性能方面分享了第一名,但在其他指标,特别是负载下的内存消耗方面,也带来了良好的全面结果。
Jetty后端(Jetty-*)在大多数指标上略落后于其他生产引擎,但始终落后于其他生产引擎。为了完整性,我还包括了仅用于开发的SunHttp后端,基准测试证实了这一点。
更新:此实现使用更高级别的契约API来生成OpenAPI规范,这可能会对性能产生一些影响。我会重新量一量,找出答案。
KTOR变体也是由@Goodhoko在goout编写的,我后来调整了/City/v1/get端点以实现与其他实现的功能等价性,它仍然是仅使用此单个端点的最不完整的实现。
KTOR还允许可插拔的HTTP服务器引擎,我对此进行了基准测试。请参阅KTOR服务器引擎基准页面。
这里的模式类似,Netty比Jetty更有效率和性能,因此有资格成为KTOR选择的主基准引擎。
我在空闲时间编写了Rust克隆,密切关注locations-kt-http4k的发展。
由于Actix Web3.0刚刚发布,我非常想将其与V2.0的性能进行比较。一对一基准测试显示v3.0至少与v2.0不相上下。我认为这是个好消息,因为v3.0在安全方面已经取得了进步。请注意,我不得不取消Swagger支持,因为回形针还没有移植到Actix 3.0,但这应该没有运行时效果。本文的其余部分使用最初的Actix-web 2.0版本,但我们知道结论同样适用于最新的v3.0。
以基准为基准的构建采用了廉价的性能技巧。它们是否会有所不同?是的,专用的锈蚀优化基准页面显示了以下内容:
将LTO=";FAT";,codegen-unit=1放入Cargo.toml的[profile.release]部分,与普通发布版本(标记为rs-actix-base-*)相比,性能提高了约17%,效率提高了约19%。
在顶部添加RUSTFLAGS=";-C target-cpu=Skylake&34;或RUSTFLAGS=";-C target-cpu=znver2&34;3不会影响结果。此工作负荷可能不会从基础x86-64 One以外的任何SIMD指令中受益,和/或即使目标CPU不支持,也会在运行时检测到并使用它们。Elfx86exts即使在基本版本中也可以检测SS(S)E3、AVX(2)指令。
Rust效率的另一个因素是@seanmonstar对num_cpu机箱的更改非常及时,以检测Docker使用的软CPU限制。4所有主要的异步运行时和线程池都依赖于num_cpust来产生最高效的工作线程数量。在Actix中,它为每个逻辑CPU启动一个单独的执行器,这一点在Actix中得到了放大。由于软CPU限制为1.5个核心,因此更改将工作线程计数从4个减少到2个。
最后有一件小事:我没有意识到一些Rust异步运行时之间的不兼容性,我最初使用的是建立在异步标准之上的Tide Web框架。我一插入ElasticSearch-rs就出现了问题,它使用的是Reqwest HTTP客户端,而后者又依赖于Tokio。我甚至粗略地将Reqwest移植到ElasticSearch-rs中用于Surf。虽然它可以工作,但它是不可持续的,而且我遗漏了Tide错误中的一些内容。我甚至在ElasticSearch-rs中粗略地移植了Reqwest for Surf。虽然它起作用了,但它是不可持续的,我遗漏了Tide错误中的一些内容。
下面的所有图表都是交互式的、可无限扩展的SVG。如果您是Firefox用户,您可以在新建选项卡中打开框架(在上下文菜单中可用)以完整查看它们。
启动时间是从Docker完成容器设置到我们收到GET/的有效HTTP响应的那一刻计算的。如果配置的Elasticsearch服务器无法访问,即需要对其执行HTTP往返,则要求不启动服务。
两个基于JVM的Kotlin服务都在3秒内启动,考虑到JVM必须加载自身、服务40+MiB胖JAR并执行初始化,这是令人印象深刻的。
Actix的生锈启动时间在图表中几乎看不到,因为它们需要1-2毫秒,基本上就是HTTP-ping Elasticsearch所需的时间。这样的个位数毫秒级启动允许在Google Cloud Run等平台上部署,这些平台会积极地将实例缩减到零,并且可能只有在收到请求后才会启动它们。
错误应该记录在任何基准中,所以我们开始吧。在我们的例子中,所有框架的行为都是典型的,在512个连接之前都是纯零错误,1024个并行连接的错误可以忽略不计,2048个并行连接的错误率约为3%(Kotlin)或1%(Rust)。
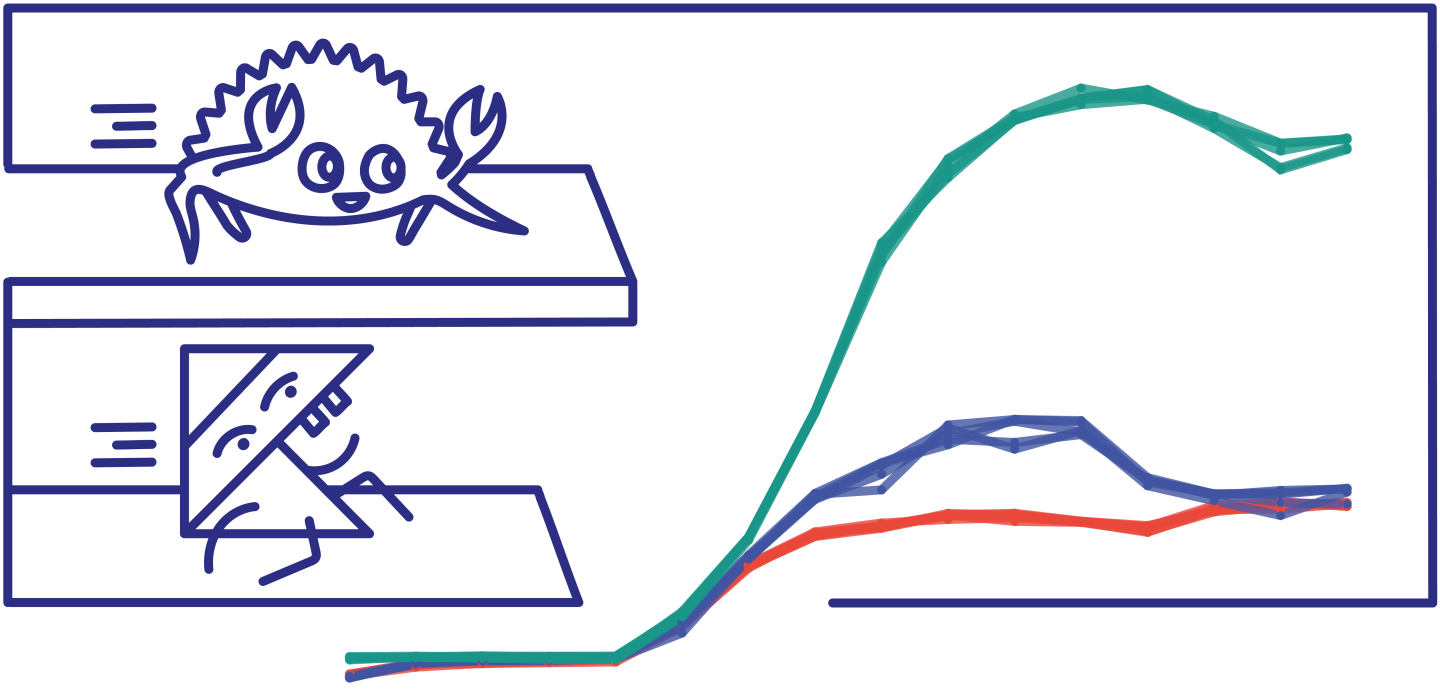
随着并发连接数量的增长(我们的主要指标之一),每秒成功的请求数达到最高值。让我们从左到右看看实例生存期的进展情况下的结果。
最初的几个单连接预热步骤展示了基于JVM的Kotlin框架如何在进行JIT优化时逐渐获得性能(下面将详细介绍),最终达到与Rust实现的临时性能平价。
最多4个连接,所有实施都受延迟绑定到Elasticsearch实例,产生相似的吞吐量。
在8个连接时,KTOR和Http4k变得受CPU限制,KTOR略高,受益于更高的CPU效率。Actix飞速发展。
首先是Http4k平台,保持在8到256个并发连接之间的3000-3200请求/秒范围内。
Actix的命中率是这个数字的两倍多,128256个并发连接大约有11000个请求/秒。
在达到峰值后,Actix和KTOR都变得过饱和,表现出轻微的性能下降,这种影响在KTOR的情况下发生得更早。
Http4k在极端连接计数中的行为与之相反,尽管存在非零错误率,但仍达到了峰值成功请求/秒~3500。这既源于效率的提高,也在较小程度上超出了Docker CPU的限制。
无论是否巧合,在图形中形状有点相似的Actix&;KTOR都基于异步执行器和低线程计数,而模式略有不同的Http4k使用更传统的高线程计数和阻塞I/O。
请注意,Google Cloud Run的默认(也是最大)并发连接计数80几乎正好击中了所有测量实现的最佳点。
正如预期的那样,延迟情况与吞吐量相反,第99个百分位数是最嘈杂的,并且在某些Rust运行中显示异常。最大的(几何)差异是在8-16个连接范围内,其中Kotlin框架已经使可用CPU饱和,但Rust还没有。
图最右边的延迟“截止”对应于模式的变化:从饱和诱导的延迟到错误响应的出现。
这里我们测量容器从开始到每个基准步骤结束的高水位线内存使用率,正如Docker报告的那样(即不仅仅是瞬时内存使用量)。
基于JVM的框架和Rust框架之间的比较在这里并不具有代表性,因为分配的Java堆除了实际使用之外还取决于配置。
与上面的度量相同,但除以每秒成功请求的数量;这给出了每个请求的非常规单位兆字节秒。
低连接计数的值较高是正常的,因为每个框架的基本内存占用分布在较少的请求中。
您可能会注意到Http4k和2个异步框架在形状上略有不同:Http4k降至~0.05MiB⋅并保持不变,而KTOR,尤其是Actix会随着延迟的增加而再次上升。在讨论中分享你的想法。
在预热阶段,JVM努力地对基于Kotlin的代码库进行JIT优化,这种即时优化与未优化代码的执行相结合,额外花费了大约23 CPU秒,这是一个非常小的资源量。5个。
不过,在考虑高频连续部署或主动实例计数自动伸缩时,基于JVM的微服务需要牢记这一点。JIT还可能与尚未优化的目标工作负载竞争资源。这种特征也应该适用于其他基于JIT的引擎,如Node.js的V8。
一旦我们达到2-8个连接或更多,Kotlin实现很快就会使已分配的CPU部分饱和,大约2个步骤之后就会出现Rust。
再往右看,Http4k设法消耗的CPU比Docker分配的15 CPU-秒稍多一些,这可能是该区域每秒请求数增加的原因,但仅超过约3.5%的CPU限制并不能完全解释性能提升约6%的原因。
消耗的CPU时间除以每秒成功的请求数或CPU效率。让我们将图表分为两部分。
Http4k,KTOR的效率由于JIT和像垃圾收集这样的记账工作在更多执行的请求之间被稀释而迅速提高。
我很难解释Actix的效率增长,这在只有Actix的图形中更为显著。异步任务执行器是否有一些恒定的开销?当空闲时,Actix消耗的CPU周期为零。
Http4k的效率略有提高,这在连接过量时几乎是意料之中的。
Actix非常微妙的效率降低导致每秒请求减少约1000个,这是由于它们之间的反向关系。
最后是我最喜欢的指标;成功服务的请求总数(时间集成吞吐量)除以已用CPU时间的累积总和(简称bang)。向上表示为请求提供服务,而向右表示消耗CPU。线斜率对应于CPU效率。
如果我们取每个实现的最远点,并除以总服务请求数所消耗的总处理器时间,我们得到每个请求的加权平均CPU时间,其中包括启动服务并使其加速所需的CPU时间。
如果我们允许自己进行明显的简化,我们可以将这个数字转换为更容易理解的每十亿个请求的成本,假设示例价格为每vCPU⋅小时0.0275美元,并且不切实际的完美资源利用率。
请对这些数字持保留态度。由于基准实例只运行几分钟,我们过多地考虑了启动成本。实际微服务可能会在远低于饱和点的负载下运行,从而花费更长的时间来处理相同数量的请求,这一影响可能只能部分补偿。
正如Devid Denton所指出的,结论是单是微服务的运营成本低得令人难以置信,而且很容易被开发和其他运行时成本所支配。
在这篇文章中,我想要超越通常的基准,让一组扩展的度量来展示测试技术的更多细微差别,并讨论它们的一些含义。我想比较每个框架的最佳状态,所以我最后做了3个资格基准,它们可能也会为人们自己服务。所有的实现、工具和数据都是开源的,所以理论上基准应该是任何人都可以复制的;而且应该很容易向组合中添加新的实现。
这篇帖子只是关于运行时特性的,这只是每种技术众多方面中的一个。比较开发人员的经验将是一篇全新的文章的素材!
我要感谢GOUT将2个Kotlin实现开源,也感谢我的前同事敦促我写下这篇文章,并彻底审阅了这篇帖子的草稿。所有的问题、更正和想法当然欢迎在下面链接的任何讨论渠道中提出。
1024和2048的顶端并发连接计数太高,不实用。它们是用来测试在不受控制的流量峰值下的框架行为。-↩。
较新的HTTP4k版本3.258.0,Undertow 2.1.3的性能略有下降,请参阅HTTP4k服务器引擎基准。↩。
基准微服务在Zen2微体系结构的AMD Epyc Roman处理器上运行,因此应该会从使用target-cpu=znver2进行编译中受益。-↩
这一变化的灵感来自于OpenJDK 11中已经存在的OpenJDK中的类似代码,所以我们在基准测试中进行了公平的比较。“↩。
人们很容易将其与RUST进行不公平的比较,在RUST中,优化的构建在11.5CPU分钟的调试构建的基础上增加了17CPU分钟。我们还应该承认,在我们的基准测试中,实际执行的kotlin应用程序代码量被人为地降低了。-↩