深度学习代码中异常的澄清和张量运算的可视化
(特伦斯在旧金山大学的数据科学硕士项目任教。您可能知道Terence是ANTLR解析器生成器的创建者。)。
大多数人使用Kera或Fastai等高级库来解决深度学习问题,这是有意义的。这些库隐藏了许多我们不关心或可以稍后了解的实现细节。然而,要真正理解深度学习,我认为在某种程度上实现您自己的网络层和培训循环是很重要的。例如,请参阅我最近的一篇名为“在没有神经网络的情况下解释RNNs”的文章。如果你对构建深度学习模型感到满意,而让一些细节有点模糊,那么这篇文章不适合你。在我古怪的情况下,我更关心的是深入学习一些东西,而不是把它实际应用到一些有用的东西上,所以我直接去寻找细节。(我想这就是为什么我在一所大学工作,而不是在工业😀工作的原因。)。这篇文章是针对我在孤立的Covid Summ 2020中对深度学习的基础的痴迷编码和学习过程中所经历的一个痛点的回应。
在编写实现深度学习网络的代码时,尤其是对我们这些新手来说,最大的挑战之一是让所有张量(矩阵和向量)维度正确排列。在涉及多个张量和张量运算的复杂表达式中,很容易丢失张量维数的轨迹。即使只是将数据馈送到预定义的TensorFlow网络层,我们仍然需要正确的维度。当您要求不正确的计算时,您将会遇到一些不太有用的异常消息。为了帮助我自己和其他程序员调试张量代码,我构建了一个名为TensorSensor(pip install tensor-Sensor)的新库。TensorSensor通过增加消息和可视化Python代码来指明张量变量的形状来澄清异常(参见右图中的预告片)。它可以与TensorFlow、PyTorch和Numpy以及Kera和Fastai等更高级的库一起使用。
TensorSensor目前的版本是0.1b1,所以我很高兴收到回购或直接发送电子邮件时产生的问题。
即使对于专家来说,也很难快速确定执行张量操作的一行Python代码中出现异常的原因。调试过程通常涉及在有问题的行前添加一条print语句,以发出每个张量操作数的形状。这需要编辑代码以创建调试语句并重新运行培训过程。或者,我们可以使用交互式调试器手动单击或键入命令来请求所有操作数形状。(这在PyCharm这样的IDE中可能不太实用,因为在调试模式下执行代码似乎要慢得多。)。以下小节说明了贫乏的默认异常消息和我建议的TensorSensor方法,而不是调试器或打印语句。
让我们看一看简单的张量计算,以说明默认异常消息提供的不太理想的信息。考虑以下包含张量维误差的硬编码单(线性)网络层的简单NumPy实现。
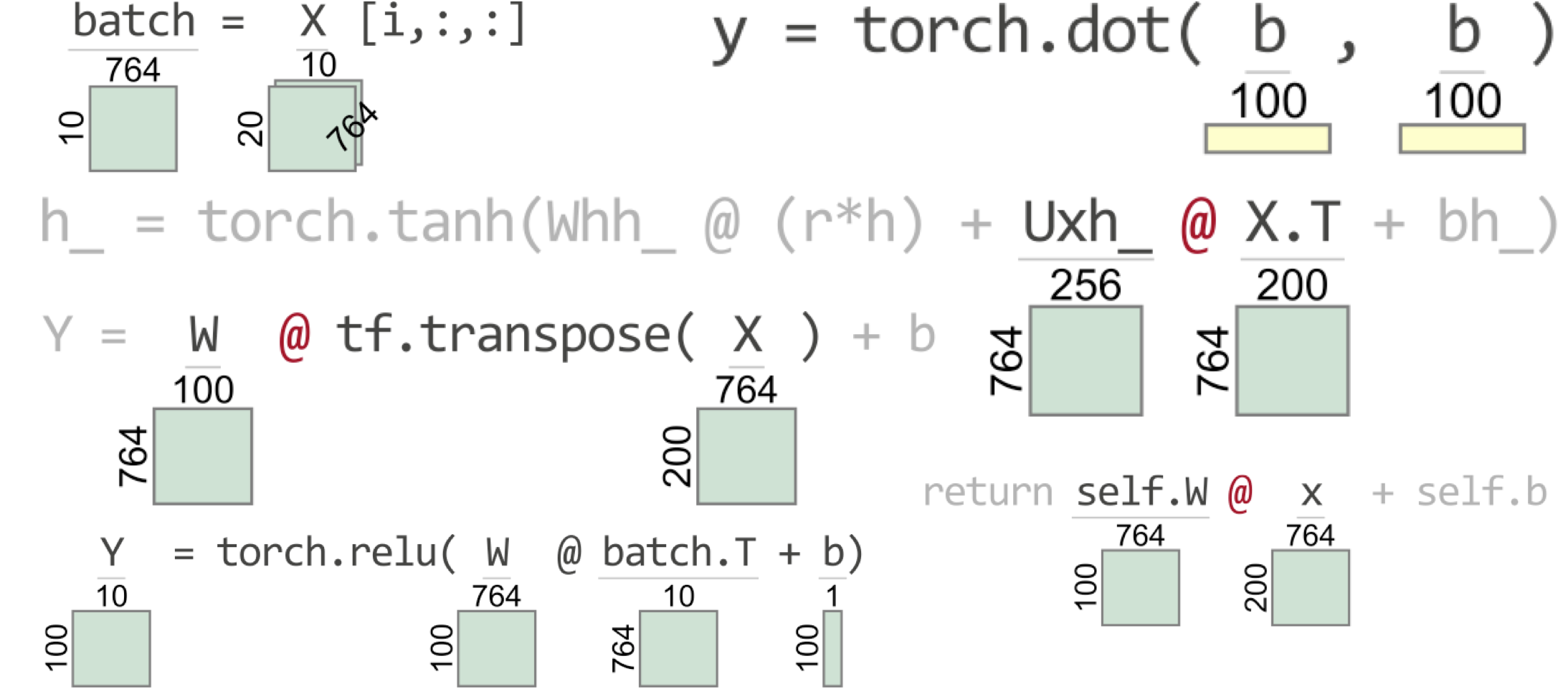
将numpy导入为npn=200#实例数d=764#实例特征数n_neurents=100#这一层有多少个神经元?w=np.and.rand(d,n_neurents)#哎呀!应为(n_Neurns,d)<;=b=np随机.rand(n_Neurents,1)X=np随机.rand(n,d)#具有n行d维的伪输入矩阵[email protected]+b#通过层传递所有X个实例。
...->;10 [email protected]+b值错误:matmul:输入操作数1在其核心维度0中不匹配,Gufunc签名为(n?,k),(k,m?)->;(n?,m?)。(764号与100号不同)
异常标识了有问题的行和哪个操作(matmul:Matrix multiply),但是如果它给出了完整的张量维,则会更有用。此外,异常将无法区分在Python的一行中发生的多个矩阵乘法。
接下来,让我们看看TensorSensor如何使调试该语句变得容易得多。如果我们使用Python with语句和tSensor';的Clarify()来包装语句,我们会得到一个可视化结果和一条增强的错误消息。
...ValueError:matmul:输入操作数...原因:@ON张量操作数W w/Shape(764,100)和操作数X.T w/Shape(764,200)。
从可视化效果可以清楚地看出,W的尺寸应该翻转为n_Neurents x d;W的列必须与X.T的行相匹配。您还可以用或不用Clarify()签出一个完整的并排图像,以查看它在笔记本中的样子。
在发生异常之前,Clarify()功能不会给正在执行的程序带来任何开销。如果出现异常,请澄清():
提供违规操作中涉及的张量大小的可视化表示;仅突出显示异常中涉及的操作数和运算符,而取消突出显示其他Python元素。
TensorSensor还澄清了PyTorch和TensorFlow提出的与张量相关的异常。下面是等效的代码片段和产生的增强异常错误消息(原因:@on tensor...)。以及来自TensorSensor的可视化功能:
导入torchW=torch.rand(d,n_神经元)b=torch.rand(n_神经元,1)X=torch.rand(n,d)with tensor.clarify():[email protected]+b
将TensorFlow导入为tfw=tf.随机性.均匀((d,n_神经元))b=tf.随机性.均匀((n_神经元,1))X=tf.随机性.均匀((n,d))带tensor.clarify():[email protected](X)+b。
运行错误:大小不匹配,m1:[764x100],m2:[764x200]at/tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41Cause:@on张量操作数W w/Shape[764,100]和操作数X.T w/Shape[764,200]。
InvalidArgumentError:矩阵大小不兼容:In[0]:[764,100],In[1]:[764,200][Op:MatMul]原因:@on张量操作数W w/Shape(764,100)和操作数tf.transspose(X)w/Shape(764,200)。
PyTorch消息没有指明是哪个操作触发了异常,但TensorFlow的消息确实指出了矩阵乘法。两者都显示操作对象维度。对于线性层的这个简单张量表达式,这些默认异常消息可能已经足够好了。尽管如此,TensorSensor可视化的问题还是比较容易看出来的。
不过,您可能想知道,为什么张量库不生成一个更有用的异常消息来标识问题子表达式中涉及的Python变量的名称。这并不是说图书馆的作者不会感到烦恼。根本问题在于,Python张量库是用C或C++编写的极其高效的核心的包装器。比方说,Python将两个张量的数据传递给C++函数,但不传递Python空间中相关的张量变量名。在C++中捕获的异常无法访问Python中的局部和全局变量空间,因此它只抛回一个泛型异常。因为Python在语句级捕获异常,所以它也不能隔离语句中的子表达式。(要了解TensorSensor如何生成此类特定消息,请查看下面的关键TensorSensor实现功夫部分。)。
缺省消息中缺乏特异性,因此很难在包含大量运算符的更复杂的语句中识别坏子表达式。例如,下面是一条摘自门控定期单元(GRU)实施的声明:
不管它在计算什么,或者变量代表什么,只要它们是张量变量就可以了。有两个矩阵乘法、两个向量加法,甚至还有一个向量元素修改(r*h)。如果没有扩充的错误消息或可视化效果,我们就不会知道哪些运算符和操作数导致了异常。为了演示TensorSensor如何在这种情况下澄清异常,我们需要为语句中使用的变量(对h_的赋值)提供一些假定义,以获得可执行代码:
NHIDDED=256Whh_=torch.ye(nHIDDED,nHIDDED)#标识矩阵Uxh_=torch.randn(d,nHIDDED)bh_=torch.zeros(nHIDDED,1)h=torch.randn(nHIDDED,1)#FAKE前一隐藏状态hr=torch.randn(nHIDDED,1)#FAKE本次计算X=torch.rand(n,d)#FAKE INPUTWITH TSENSOR.CRILEY():h_=torch.tanh(WHH_@(r*h)[email protected]+bh_)
同样,您可以忽略代码执行的实际计算,将重点放在张量变量的形状上。
对于我们大多数人来说,仅仅看张量维数和张量码是不可能识别问题的。默认的异常消息当然是有帮助的,但我们中的大多数人仍然难以识别问题。以下是默认异常消息的关键位(请注意对C++代码的无用引用):
->;10 h_=torch.tanh(WHH_@(r*h)[email protected]+bh_)运行错误:大小不匹配,m1:[764x256],m2:[764x200]at/tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41。
我们需要知道的是哪些运算符和操作数失败了,然后我们就可以查看维度来识别问题。以下是TensorSensor的可视化和增强异常消息:
->;10 h_=torch.tanh(whh_@(r*h)[email protected]+bh_)运行错误:大小不匹配,m1:[764x256],m2:[764x200]at/tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41Cause:@张量操作数uxh_w/Shape[764,256]和操作数X.T w/Shape[764,200]。
人眼很快就能抓住所指示的运算符,并且矩阵-矩阵上的维度相乘。Ooops:Uxh_的列必须与X.T.的行匹配。Uxh_的维度已反转,应为:
在这一点上,我们只使用了我们自己在WITH代码块中直接指定的张量计算。在张量库的预置网络层中触发的异常怎么办?
TensorSensor在最后一段代码进入您选择的张量库之前将其可视化。例如,让使用标准PyTorch nn.线性图层,但传入的X矩阵是n x n,而不是适当的n x d:
L=torch.nn.线性(d,n_神经元)X=torch.rand(n,n)#哎呀!应为n x dwith tensor.clarify():Y=L(X)。
运行错误:大小不匹配,m1:[200x200],m2:[764x100]at/tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41Cause:L(X)张量参数X w/Shape[200,200]。
TensorSensor将对张量库的调用视为操作符,无论是对网络层的调用还是对torch.dot(a,b)之类的简单调用。库函数内触发的异常会生成标识函数和任何张量参数维数的消息。
当使用具有预构建层对象的高级库(如KERAS)时,我们会得到极好的错误消息,表明深度学习网络各层之间的维度不匹配。但是,如果您正在构建自定义层,或者只是实现您自己的层以更彻底地理解深度学习,那么您将需要检查Layer对象内部触发的异常。TensorSensor下降到从With语句块内启动的任何代码中,只有当它到达张量库函数时才停止。
作为演示,让我们通过将上面的简单线性层代码包装在类定义中来创建我们自己的线性网络层:
类线性:def__init__(self,d,n_unurents):self.w=torch.randn(n_neurents,d)self.b=torch.zeros(n_neurents,1)def__call__(self,input):return self.w@input+self.b。
然后,我们可以创建一个层作为对象,并使用一些伪输入X执行正向计算:
L=线性(d,n_神经元)#创建一个LayerX=torch.rand(n,d)#利用tensor.clarify():Y=L(X)#L(X)调用L__call__()
线性层在权重W和偏移b上具有正确的维数,但__call__()中的公式错误地引用输入,而不是该输入矩阵的转置,从而触发异常:
----RuntimeError回溯(最近一次调用)<;ipython-Input-20-b6b1bd407c61>;在<;模块>;9 10中,带tensor.clarify(hush_error=false):->;11 Y=L(X)<;Ipython-input-16-678a8372f1c2>;in__call__(self,x)4 self.b=torch.zeros(n_Neurents,1)5 def__call__(self,x):->;6返回self.w@x+self.b#L(X)调用L.__Call_(_)运行错误:大小不匹配,m1:[100x764],m2:[200x764]at/tmp/pip-req-build-as628lz5/aten/src/TH/generic/THTensorMath.cpp:41Cause:@on张量操作数self.w w/Shape[100,764]和操作数x w/Shape[200,764]。
因为L(X)调用的是我们自己的代码,而不是张量库函数,所以TensorSensor在__call__()中澄清了有问题的语句,而不是with块中的Y=L(X)语句。
到目前为止,我们一直专注于澄清异常,但有时我们只是想向其他人解释一些正确的张量代码,或者使其更易于阅读。也不是所有的错误代码都会触发异常;有时,我们只是得到了错误的答案。如果错误答案具有错误的形状,TensorSensor可以提供帮助。接下来,让我们来看看TensorSensor的EXPLAIN()功能。
TensorSensor的Clarify()不起作用,除非张量代码触发异常。为了可视化无异常Python语句中的张量维数,TensorSensor提供了一种名为expline()的机制,该机制类似于clarify(),不同之处在于Expline()为块内执行的每个语句生成可视化效果。例如,这里又是我们熟悉的线性层计算,但包装在EXPLAIN()块中,并带有结果张量形状可视化:
N=200#实例数d=764#实例特征数n_neurents=100#这一层有多少个神经元?w=torch.rand(n_neurents,d)b=torch.rand(n_neurents,1)X=torch.rand(n,d)with tensor.explay():[email protected]+b。
查看结果计算的形状(对于Y)很方便。另外,注意列向量b在视觉上很容易识别为垂直矩形(只有一列的矩阵)。行向量是水平矩形:
N_神经元=100b=torch.rand(1,n_神经元)#2D张量1 x n_神经元,带tensor.解释性():[email protected].
列向量和行向量仍然是2D矩阵,但是我们也可以有1D张量:
1D张量的可视化效果看起来像2D行向量,但是黄色(相对于淡绿色)表示它是1D的。(这一点很重要,因为张量库通常以不同的方式处理1D向量和2D行向量。)。结果(Y)是标量,因此没有可视化组件。
理解和调试使用二维以外张量的代码可能真的很有挑战性。不幸的是,这个问题经常出现。例如,出于性能原因,批量训练深度学习网络是很常见的。这意味着将输入矩阵X重塑为n_batches x Batch_size x d而不是n x d。下面的代码模拟多批通过线性层。
N=200#实例数d=764#实例特征数n_neurents=100#此层中有多少个神经元?Batch_size=10#每批有多少条记录?n_batches=n//Batch_sizeW=torch.rand(n_neurents,d)b=torch.rand(n_neurents,1)X=torch.rand(n_Batches,Batch_size,d)with tensor.expline():对于范围内的i(N_Batches):Batch=X[i,::,]Y=torch.relu([email protected]+b)。
以下是TensorSensor如何可视化这两个语句(尽管是在循环中,但每个可视化都给出一次):
为了表示3D张量的形状(如X),TensorSensor会绘制一个额外的方框来模拟三维透视,并在45度处提供第三个维度。
为了将张量可视化到3D之外,让我们考虑一个例子,其中输入实例是包含每个输入像素的红、绿、蓝值的图像。常见的表示是每个图像的1xdx3矩阵(d是图像的宽度乘以高度)。对于n个图像,我们有一个nxdx3矩阵。再加上批处理,我们得到一个4D n_Batches x Batch_Size x d x 3矩阵:
如您所见,超过三个的尺寸显示在3D表示的底部,前面有一个省略号。在本例中,第四个尺寸标注显示为“...x3”。
TensorSensor有一些重要的特点值得突出。首先,与Clarify()不同,EXPLAIN()不会深入到从WITH块中的语句调用的代码。它只在WITH块中显示语句。每次执行WITH BLOCK语句都会生成一个新映像,最多只能生成一个映像。换句话说,如果With代码包围了一个循环,您将不会在该循环中看到同一语句的多个可视化效果。
其次,澄清()和解释()都会导致张量语句执行两次,因此要注意副作用。例如,下面的代码打印“hi”两次,一次是由TensorSensor打印的,另一次是在正常程序执行期间打印的。大多数张量表达式都是无副作用的,所以这通常不是问题,但请记住这一点。(有关更多详细信息,请参阅下面的实施部分。)。
第三,TensorSensor不能处理所有语句/表达式和所有Python代码结构。解析器会忽略以RETURN以外的关键字开头的行,因此澄清和解释例程不会处理如下所示的方法:
CLISTIFY或EXPLAIN WITH块中的语句也必须单独在行中。
最后,因为EXPLAIN()会为WITH块中的每个语句创建可视化效果,所以“解释的”代码的运行速度会明显变慢。
大多数情况下,了解表达式中引用的张量变量的形状就足以调试Python语句。然而,有时一个运算符结合了其他运算符的结果就是问题的根源。我们需要一种方法来可视化所有部分结果的形状,我们可以使用倒置的树来显示所有子表达式的数据流和形状。在语言世界中,我们称之为抽象语法树或AST。例如,下面是从上面设置的假GRU计算(使用正确的Uxh_Definition):
NHIDDED=256Whh_=torch.ye(n隐藏,n隐藏)Uxh_=torch.randn(n隐藏,d)#更正定义bh_=torch.zeros(n隐藏,1)h=torch.randn(n隐藏,1)#FAKE前一隐藏状态hr=torch.randn(nHIDDED,1)#FAKE本次计算X=torch.rand(n,d)#FAKE INPUT。
要可视化张量计算的AST,我们可以使用astviz()和一个表示要可视化的代码的字符串,该代码将在当前执行帧中执行:
如果您只想查看AST,而不想计算语句或表达式,请将frame=None传递给astviz()。(附注:ast是使用raphviz生成的,但是代码可视化使用matplotlib。)。
我想通过描述一下TensorSensor的工作原理来结束这篇文章。如果您不擅长语言实现,那么可以忽略下一节,但是如果您进行了大量张量计算,请务必查看TensorSensor库。
TensorSensor的实现充分利用了我作为语言实现者的经验,这在我作为机器学习机器人的新世界里出人意料地派上了用场。如果您有类似的经验,代码中的大部分细节都会清晰可见,但是让本文中的所有内容正常工作的关键技巧是值得探讨的:递增地解析和计算少量的Python语句和表达式,记录它们的部分结果。(这也是我严重滥用matplotlib来生成可视化效果的情况,但是您可以查看代码,看看它是如何工作的。)。
正如我前面指出的,Python在语句级捕获异常。例如,如果您在a[i]+b[j]中得到一个IndexError,则Python不会告诉您。
.