起重机起重的新后端
这篇文章将我最近在Cranelift上的工作描述为我在Mozilla的日常工作的一部分。在这篇文章中,我将设置一些上下文并描述指令选择问题。特别地,我将谈一谈指令选择器和后端框架的总体改造,这是我们在过去九个月左右一直致力于的工作。这项工作是与我杰出的同事朱利安·苏厄德(Julian Seward)和本杰明·布维尔(Benjamin Bouvier)共同开发的,丹·戈曼(Dan Gohman)也提供了重要的早期投入,并得到了所有优秀的Cranelift黑客的帮助。
该项目是一个用Rust编写的编译器框架,专为即时编译而设计(但不是排他性的)。它是一个通用编译器:它最流行的用例是编译WebAssembly,尽管还有其他几个前端,例如cg_clif,它使Rust编译器本身适应使用Cranelift。到目前为止,Mozilla和其他几个地方的人们已经在开发编译器几年了。它是wamtime(浏览器外部的WebAssembly运行时)的默认编译器后端,也在其他几个地方的生产中使用。
我们最近打开了开关,在ARM64(AArch64)机器(包括大多数智能手机)上的夜间Firefox中打开了基于Cranelift的WebAssembly支持,如果一切顺利,它最终将在稳定的Firefox版本中发布。Cranelift是在字节码联盟的保护伞下开发的。
在过去的9个月里,我们在Cranelift中为“机器后端”(即编译器中支持特定CPU指令集的部分)构建了一个新的框架。如上所述,我们还为AArch64添加了一个新的后端,并根据需要填充了功能,直到Cranelift准备好在Firefox中投入生产使用。这篇博客文章设置了一些背景,并描述了进入后端框架改造的设计过程。
为了理解我们最近在Cranelift上所做的工作,我们需要放大上面的Cranelift_codegen箱子,并讨论它过去是如何工作的。这个“Clif”输入是什么,编译器如何将其转换为CPU可以执行的机器码?
Cranelift使用CLIF或Cranelift IR(中间表示)格式来表示它正在编译的代码。每个执行程序优化的编译器都使用某种形式的中间表示(IR):您可以将其视为虚拟指令集,它可以表示程序被允许执行的所有操作。IR通常比实际指令集简单,设计为使用一小部分定义良好的指令,以便编译器可以很容易地推理出程序的含义。
IR还独立于编译器最终面向的CPU体系结构;这使得只要编译器适合于面向新的CPU体系结构,就可以重用大部分编译器(例如,从输入编程语言生成IR的部分,以及优化IR的部分)。CLIF采用静态单赋值(SSA)形式,并使用带有基本块的传统控制流图(尽管它以前允许扩展基本块,但这些块已被逐步淘汰)。与许多SSAIR不同,它用块参数表示φ节点,而不是显式的φ指令。
在creenelift_codegen中,在我们修改后端设计之前,程序在整个编译过程中一直保留在Clif中,直到编译器发出最终的机器码。这似乎与我们刚才所说的相矛盾:IR怎么可能是独立于机器的,但又是我们发出机器代码的最终形式呢?
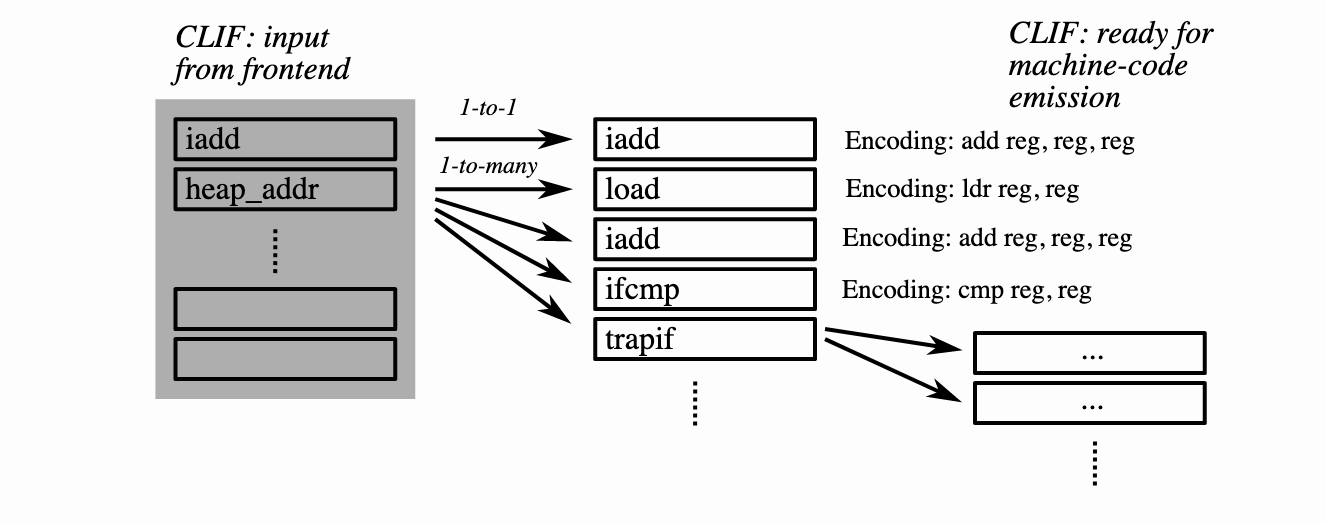
答案是,旧的后端是围绕“合法化”和“编码”的概念构建的。从更高的层次来看,想法是每条Cranelift指令要么对应于一条机器指令,要么可以被一系列其他Cranelift指令所取代。有了这样的映射,我们可以分步细化Clif,从来自早期编译器阶段的与机器无关的任意指令开始,执行编辑,直到Clif与机器代码一一对应。让我们可视化一下这个过程:
对机器指令进行直接“编码”的Clif指令的一个非常简单的例子是iadd,它只将两个整数相加。在基本上任何现代架构上,这应该映射到一个简单的ALU指令,该指令将两个寄存器相加。
另一方面,许多CLIF指令没有清晰地映射。有些算术指令就属于这一类:例如,有一条CLIF指令用来计算整数的二进制表示(Popcount)中的设置位数;并不是每个CPU都有一条这样的指令,所以它可能会扩展成更长的位操作序列。
也存在在更高语义级别上定义的操作,这些操作必须随着扩展而降低:例如,对WASM存储器的访问被降低为获取线性存储器基数及其大小、对照限制检查WASM地址的界限、计算WASM地址的真实地址并执行访问的操作。
然后,为了编译一个函数,我们迭代Clif并找到没有直接机器编码的指令;对于每个指令,我们只需展开到合法化的序列,然后递归地考虑该序列中的指令。我们循环,直到所有指令都有机器编码。在这一点上,我们可以发出与每条指令的编码相对应的字节。
传统的Cranelift后端设计有许多优势,它在整个过程中使用单一IR执行基于扩展的合法化。然而,正如人们可能预料的那样,也有一些缺点。让我们分别讨论其中的几个。
通过对单个IR的操作一直到机器代码的发送,可以在多个阶段应用相同的优化。
如果大多数Cranelift指令变成一条机器指令,并且几乎不需要合法化,那么这个方案可以非常快:它变成了简单的一次遍历来填充“编码”,这些编码由小索引表示到一个表中。
基于扩展的合法化可能并不总是产生最佳代码。有时存在实现多个CLIF指令的行为的单机指令,即多对一映射。为了生成高效的代码,我们希望能够使用这些指令;而基于扩展的合法化则不能。
基于扩展的合法化规则必须遵守指令之间的偏序:如果A扩展为包括B的序列,则B稍后不能扩展为A。这可能会成为机器后端作者保持直通的一个困难。
基于扩张的合法化存在效率问题。在算法级别,我们倾向于尽可能避免定点循环(在这种情况下,“继续扩展,直到不再存在扩展”)。运行时是有界的,但是这个界有点难以推论,因为它依赖于链式扩展的最大深度。支持就地编辑的数据结构也比我们希望的要慢得多。通常,编译器将IR指令存储在链接列表中,以允许就地编辑。虽然这与基于数组的解决方案渐近一样快(我们永远不需要执行随机访问),但在现代CPU上,它对缓存或ILP的友好性要差得多。相反,我们更喜欢存储指令数组,并在任何可能的情况下对它们执行单次遍历。
随着时间的推移,我们对合法化方案的具体实现变得有些笨拙(例如,参见GitHub问题#1141:用火杀死食谱)。添加一条新指令需要学习“食谱”、“编码”和“合法化”,以及仅仅是指令和操作码;更传统的代码降低方法可以避免大部分这种复杂性。
单级IR有一个基本的张力:要使分析和优化正常工作,IR应该只有一种方式来表示任何特定的操作。另一方面,机器级别的表示应该表示目标ISA的所有相关细节。单一的IR根本不能很好地服务于这一光谱的两端,当CLIF从任何一端偏离时,困难就出现了。
出于所有这些原因,作为Cranelift改造的一部分,以及我们新的AArch64后端的先决条件,我们为机器后端和指令选择构建了一个新的框架。该框架允许机器后端独立于Clif定义它们自己的指令;我们不是通过扩展使其合法化并运行到固定点,而是定义单一的降低路径;并且一切都围绕更高效的数据结构构建,仔细地优化数据传递并完全避免链表。现在我们来介绍一下这个新设计!
新的Cranelift后端的主要思想是添加一个特定于机器的IR,它有几个专门选择的属性来很好地表示机器代码。我们称之为VCode,它来自“虚拟寄存器代码”,VCode包含机器,或机器指令。我们做出的主要设计选择是:
VCode是线性指令序列。有允许遍历基本块的控制流信息,但数据结构并不能轻松地允许插入或删除指令或重新排序代码。取而代之的是,我们只需一次遍历就可以进入VCode,按照指令的最终(或接近最终)顺序生成指令。
VCode不是基于SSA的;相反,它的指令在寄存器上操作。降低时,我们分配虚拟寄存器。生成VCode后,寄存器分配器计算适当的寄存器分配并就地编辑指令,用真实寄存器替换虚拟寄存器。(两者都打包到32位表示空间中,使用高位来区分虚拟和真实。)。在这个级别上避免SSA允许我们避免维护其不变量的开销,并且更接近于真实的机器。
VCode指令简单地存储在数组中,基本块单独记录为数组(指令)索引范围。我们设计此数据结构是为了快速迭代,而不是为了编辑。
从VCode容器的角度来看,每条指令大多是不透明的,但有几个例外:每条指令都公开其(I)寄存器引用和(Ii)基本块目标(如果是分支)。寄存器引用分为通常的“使用”和“定义”(读取和写入)。
还要注意的是,指令可以引用任何一个虚拟寄存器(这里表示为V0.。Vn)或真实机器寄存器(这里表示为R0.。Rn)。此设计选择允许机器后端在特定指令或ABI(参数传递约定)需要时使用特定寄存器。
除了寄存器和分支目标之外,VCode中包含的指令可以包含发出机器代码所需的任何其他信息。每台机器后端都定义自己的类型来存储此信息。例如,在AArch64上,以下是几种简化的指令格式:
Enum Inst{/具有两个寄存器源和一个寄存器目标的ALU操作。AluRRR{ALU_OP:ALUOp,RD:WRITABLE,Rn:REG,Rm:REG,},/带有寄存器源和立即源以及寄存器/目的地的ALU操作。AluRRImm12{alu_op:aluOp,rd:write,rn:reg,imm12:imm12,},/双向条件分支。包含两个目标;在发出时,发出条件/分支指令,后跟无条件分支指令,但/发送缓冲区通常会将其折叠为只有一个分支。CondBR{Take:BranchTarget,Not_Take:BranchTarget,Kind:CondBrKind,},//...。
这些枚举臂可以被认为类似于旧后端中的“编码”,不同之处在于它们是使用类型安全且易于使用的Rust数据结构以更简单的方式定义的。
现在我们来讨论最有趣的设计问题:如何将独立于机器的CLIF指令降低为具有适当类型CPU指令的VCode?换句话说,我们用什么取代了以扩展为基础的合法化和编码方案?
我们对CLIF指令执行一次遍历,并且在每条指令处,我们调用机器后端提供的函数将CLIF指令降低为VCode指令。后端被赋予一个“降低上下文”,通过该上下文,后端可以检查流入其中的指令和值,并根据需要执行“树匹配”(见下文)。这自然允许1对1、1对多或多对1翻译。我们将引用计数方案合并到此过程中,以确保只有在实际使用指令的值时才会生成指令;当发生多对1匹配时,这是消除死代码所必需的。
回想一下,旧的设计允许从CLIF指令到机器指令的一对一和一对多映射,但不是多对一。当涉及到寻址模式之类的事情的模式匹配时,这尤其有问题,在这些模式中,我们希望识别特定的操作组合,并选择一条同时涵盖所有这些操作的特定指令。
让我们从定义一个以特定Clif指令为根的“树”开始。对于指令的每个参数,我们可以“查找”程序以找到其生产者(Def)。因为CLIF是SSA形式的,所以指令变元是一个普通值,它必须正好有一个定义,或者它是一个表示多个可能定义的块参数(在传统的SSA公式中是φ节点)。我们会说,如果我们达到一个块参数(φ-Node),我们只是在树叶结束-在作为真实数据流的子集的树上进行模式匹配是完全可以的(我们可能会得到次优的代码,但它仍然是正确的)。例如,给定CLIF代码:
块0(v0:i64,v1:i64):brnz v0,块1(V0)跳转块1(V1)块1(v2:i64):v3=iconst.i64 64 v4=iadd.i64 v2,v3 v5=iadd.i64 v4,v0 v6=load.i64 v5返回v6。
让我们考虑加载指令:v6=load.i64v5。简单的代码生成器可以使用保存v5的寄存器作为地址,将这种1对1映射到CPU的普通加载指令。这当然是正确的。不过,我们或许可以做得更好:例如,在AArch64上,可用的寻址模式包括两个寄存器和LDR x0,[x1,x2]或具有恒定偏移量LDR x0,[x1,#64]的寄存器。
我们止步于v2和v0,因为它们是块参数;我们不确定哪条指令将生成这些值。我们可以用常数64代替v3。鉴于此观点,加载指令的降低过程可以相当容易地选择寻址模式。(在AArch64上,进行此选择的代码在此处;在本例中,它将选择寄存器+常量立即形式,为v0+v2生成单独的加法指令。)。
请注意,在降低期间,我们实际上并不显式构造操作数树。取而代之的是,机器后端可以查询每个指令输入,而降低框架将提供一个结构,在已知的情况下给出生成指令,在知道的情况下给出常量值,如果需要的话,给出保存该值的寄存器。
后端可以根据需要遍历树(通过“生成指令”)任意多次。如果它不能将树上更靠上的指令的操作合并到根指令中,则只需使用该点的寄存器中的值即可;仅为根指令生成机器指令始终是安全的(尽管可能不是最优的)。
那么,考虑到这种匹配策略,我们实际上应该如何进行翻译呢?基本上,后端提供了一个函数,每个CLIF指令在操作数树的“根”处调用一次,并且可以生成任意数量的机器指令。此函数本质上只是根Clif指令操作码上的一个大型匹配语句,匹配臂根据需要进行更深入的查找。
以下是整数加法运算降至AArch64的Match-Arm的简化版本(完整版本在此处):
匹配操作{//...。操作码::iadd=>;{let rd=get_output_reg(ctx,output[0]);let rn=put_input_in_reg(ctx,input[0]);let rm=put_input_in_rse_imm12(ctx,input[1]);let alu_op=Choose_32_64(ty,ALUOp::Add32,ALUOp::Add64);ctx.emit(alu_inst_imm12(alu_op,rd,rn,rm));}//...}。
这里的几个帮助器函数中有一些神奇之处。Put_input_in_reg()调用CTX上的正确方法来查找保存输入值的寄存器。Put_input_in_rse_imm12()更有趣:它返回一个ResultRSEImm12,它是一个“寄存器、移位寄存器、扩展寄存器或12位立即数”。这组选项捕获了我们在AArch64上为ADD指令的第二个参数提供的所有选项。
助手查看操作数树中的节点,并尝试匹配移位运算符或零/符号扩展运算符,这两个运算符可以直接合并到加法运算中。它还检查操作数是否为常量,如果是,则可以放入12位立即数字段。如果不是,则退回到简单地使用寄存器输入。Alu_inst_imm12()然后分解此枚举并选择适当的Inst臂(分别为AluRRR、AluRRShift、AluRRRExtension或AluRRImm12)。
就这样!不需要合法化和重复代码编辑来匹配几个操作并产生机器指令。我们发现这种写降低逻辑的方式相当直截了当,很容易理解。
既然我们可以降低一条指令,那么如何降低包含多条指令的函数体呢?这并不像循环遍历指令并调用上面描述的匹配操作码函数那样简单(尽管这实际上是可行的)。特别是,我们希望更高效地处理多对一的情况。考虑当上面的加法指令逻辑能够将(比方说)左移运算符合并到加法指令中时会发生什么。
然后,加法机器指令将使用移位的输入寄存器,并完全忽略移位的输出。如果移位运算符没有其他用途,我们应该避免完全进行计算;否则,将操作合并到加法中是没有意义的。
我们实现了一种引用计数来解决这个问题。具体地说,我们跟踪是否实际使用了任何给定的SSA值,并且只有在使用了CLIF指令的任何结果时(或者如果它有必须发生的副作用),才会为CLIF指令生成代码。这是一种消除死码的形式,但集成到单次降低通道中。
我们必须在Defs之前看到使用情况,这样才能起作用。因此,我们“向后”迭代函数体。具体地说,我们按后序迭代;这样,所有指令都在支配它们的指令之前看到,所以给定SSA形式,我们在defs之前看到用法。
让我们看看这在现实生活中是如何运作的!请考虑以下Clif代码:
函数%F25(I32,I32)->;I32{BLOCK 0(v0:I32,v1:I32):v2=iconst.i32 21 v3=ishl.i32 v0,v2 v4=isub.i32 v1,v3返回v4}。
我们预计左移位(Ishl)操作应该合并到AArch64上的减法操作中,使用ALU指令的reg-reg-Shift形式,确实会发生这种情况(在这里,我展示了在运行Clif-util Compile-d--target aarch64时使用RUST_LOG=DEBUG可以看到的调试转储格式):
Vcode{条目块:0块0:(原IR块:块0)(指令范围:0.。6)Inst 0:mov%v0J,X0 Inst 1:mov%v1J,x1 Inst 2:sub%v4Jw,%v1Jw,%v0Jw,LSL 21 Inst 3:mov%v5J,%v4J Inst 4:mov x0,%v5J Inst 5:Ret}。
然后,它通过寄存器分配器,附加了前言和结尾(在我们知道哪一个之前,我们不能生成它们。
.