为什么mmap比系统调用快(2019年)
当我问我的同事为什么mmap比系统调用快时,他们的回答不可避免地是“系统调用开销”:跨越用户空间和内核之间边界的开销。事实证明,这种开销比我过去认为的更细微,所以让我们来看看幕后的情况,以了解性能差异。
系统调用。系统调用是一种特殊的函数,它允许您跨越保护域。当程序在用户模式(非特权保护域)下执行时,不允许执行在内核模式(特权保护域)下执行的代码所允许的事情。例如,在用户空间中运行的程序通常在没有内核帮助的情况下无法读取文件。当用户程序从操作系统请求服务时,系统会通过系统调用保护自己不受恶意程序或错误程序的影响。系统调用执行特殊的硬件指令,通常称为“陷阱”,将控制转移到内核。然后内核可以决定是否接受该请求。
虽然这种保护非常有用,但也是有代价的。当我们从用户空间进入内核时,我们必须保存硬件寄存器,因为内核可能需要使用它们。此外,由于直接取消引用用户级指针是不安全的(如果它们为空怎么办-这会使内核崩溃!)。必须将这些指针引用的数据复制到内核中。
当我们从系统调用返回时,我们必须以相反的顺序重复该序列:复制出用户请求的任何数据(因为我们不能只给用户程序指向内核内存的指针),恢复寄存器并跳转到用户模式。
页面错误。操作系统和硬件一起将写在程序可执行文件中的地址(称为虚拟地址)转换为实际物理内存中的地址(物理地址)。编译器直接生成物理地址非常不方便,因为它不知道您可能在哪台机器上运行您的程序,它有多少内存,以及在您的程序运行时,哪些其他程序可能正在使用物理内存。因此需要这种虚拟到物理地址转换。翻译或映射设置在程序的页表中。当您的程序开始运行时,不会设置任何这些映射。因此,当您的程序试图访问虚拟地址时,它会生成一个页面错误,通知内核去设置映射。内核被通知需要通过陷阱处理页面错误,因此在这种情况下,它有点类似于系统调用。不同之处在于系统调用是显式的,而页面错误是隐式的。
缓冲区缓存。缓冲区缓存是内核内存的一部分,用于保存最近访问的文件块(这些块称为块或页)。当用户程序请求读取文件时,(通常)首先将文件中的页面放入缓冲区缓存。然后,在从系统调用返回期间,将数据从缓冲区高速缓存复制到用户提供的缓冲区。
Mmap。Mmap代表内存映射文件。它是一种在不调用系统调用的情况下读写文件的方法。操作系统保留程序虚拟地址的块以直接“映射”到文件中的块。因此,如果程序从地址空间的该部分读取数据,它将获得驻留在文件的相应部分中的数据。如果文件的该部分恰好驻留在缓冲区高速缓存中,则在第一次访问时,映射区块的虚拟地址将简单地映射到相应缓冲区高速缓存页的物理地址,并且稍后不会调用任何系统调用或其他陷阱。如果文件数据不在缓冲区缓存中,访问映射区域将生成页面错误,提示内核从磁盘获取相应的数据。
让我们从阐述假设开始。为什么我们期望mmap更快呢?有两个显而易见的原因。首先,它不需要显式地跨越保护域,尽管当我们有页面错误时仍然存在隐式跨越。也就是说,如果文件中的给定范围被多次访问,那么在第一次访问之后,我们很可能不会出现页面错误。然而,在我的实验中没有出现这种情况,所以我确实预料到每次读取文件的新块时都会遇到页面错误。
其次,如果编写的应用程序可以直接访问映射区域中的数据,我们就不必执行内存复制。不过,在我的实验中,我感兴趣的是测量应用程序为其读取的数据具有单独的目标缓冲区的场景。因此,即使文件被mmmap,应用程序仍然会将数据从映射区域复制到目标缓冲区。
因此,在我的实验环境中,我预计mmap会比系统调用稍微快一些,因为我认为处理页面错误的代码会比系统调用的代码更精简一些。
我用下面的方式设置了我的实验。我创建了一个4 GB的文件,然后使用4KB、8KB或16KB的块大小顺序或随机读取它。我使用read系统调用或mmap读取文件。在mmap的情况下,数据从映射区域复制到单独的“目标”缓冲区。我使用冷缓冲区缓存(意味着文件不在那里缓存)或热缓冲区缓存(意味着文件在内核内存中)来运行这些测试。存储介质是您可能期望在典型服务器中找到的SSD。所有读取都使用单个线程执行。这里是我的基准测试的源代码。
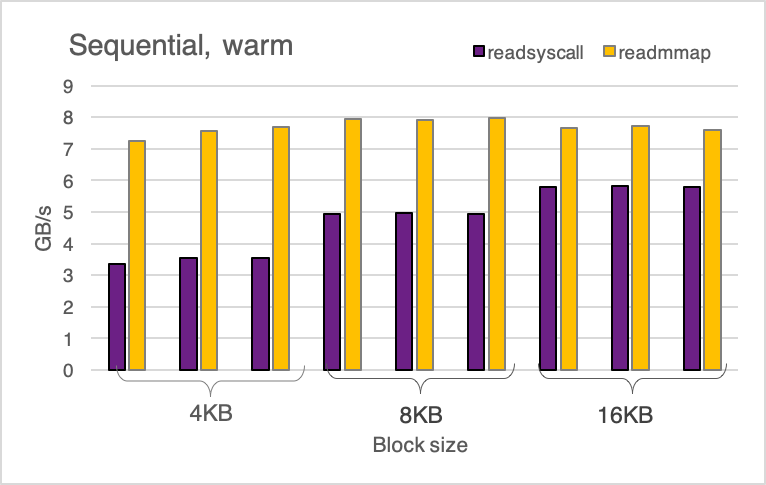
下图显示了顺序/暖、顺序/冷、随机/暖和随机/冷运行的读取基准的吞吐量。
除了少数例外,mmap比系统调用快2-6倍。让我们分析一下热实验中发生了什么,因为mmap提供了更一致的改进。
下图显示了在16KB块大小的顺序/暖SysCall实验期间收集的CPU配置文件。在此实验期间,CPU利用率为100%,因此CPU配置文件可以告诉我们全部情况。
我们看到大约60%的时间花在COPY_USER_ENHANDIZED_FAST_STRING上-这是一个将数据复制到用户空间的函数。大约15%用于跨越系统调用边界的其他工作(函数do_syscall_64、entry_syscall_64和syscall_return_via_sysret),大约6%用于在缓冲区缓存中查找数据的函数(find_get_entry和Generic_file_Buffered_read)。
现在,让我们看一下在使用相同参数的mmap测试期间发生了什么:
这份个人资料有很大的不同。大约60%的时间花在__memmove_avx_unaligned_erms上,还有大量时间花在设置页面映射的各种函数上。
我们稍后将返回到__memmove_avx_unaligned_erms,但现在让我们试着计算一下映射页面所花费的确切时间。我有一个巧妙的窍门来做那件事。在Linux上,mmap系统调用可以接受MAP_PUPULATE标志。此标志的作用是强制mmap在实际系统调用期间预先填充所有页面映射,因此在测试实际运行时不会执行任何页面映射工作。因此,我将测试更改为使用MAP_PUPULATE调用mmap,并了解到实验完成速度提高了大约36%。(我只测量主循环的计时,而不测量mmap系统调用的计时)。因此,我假设在上面的配置文件中,所有这些映射函数约占36%。
让我们总结一下到目前为止我们所掌握的内容。使用CPU配置文件,我们能够解释syscall实验大约82%的执行时间(60%用于复制,15%用于其他跨域操作,8%用于从缓冲区缓存实际读取文件),mmap实验大约96%:60%用于用户级内存复制,大约36%用于映射页面。
我还必须告诉您,如果我调整实验运行很长时间,一遍又一遍地在循环中访问同一个文件,mmap实验完全由内存副本控制:
如果我运行更长时间,Syscall实验的概况基本保持不变:
这就是事情变得非常有趣的地方。有很大一部分时间-至少60%-花费在复制数据上。但是,syscall和mmap使用的函数非常不同,不仅在名称上如此。
__memmove_AVX_UNALIGNED_ERMS在mmap实验中称为__memmove_avx_unaligned_erms,它是使用高级矢量扩展(AVX)实现的(这里是它所依赖的函数的源代码)。另一方面,Copy_User_Enhanced_FAST_String的实现要简单得多。在我看来,这是mmap速度更快的重要原因。使用宽向量指令进行数据复制有效地利用了内存带宽,并与CPU预取相结合,使mmap变得非常快。
为什么内核实现不能使用AVX?如果它这样做了,那么它将不得不在每次系统调用时保存和恢复这些寄存器,这将使跨域变得更加昂贵。所以在Linux内核中这是一个有意识的决定。
同时,将应用程序转换为使用mmap而不是系统调用可以使其运行得更快。也就是说,使用mmap编程并不总是很方便,但这是另一篇…文章的主题



