让我们用GPU构建一个高性能的模糊器
TL;DR:在云中模糊化嵌入式软件时,我们是否可以使用GPU获得10倍的性能/美元?根据我们的初步工作,我们认为答案是肯定的!
模糊是一种软件测试技术,它为程序提供许多随机化的输入,试图导致意想不到的行为。它是一项重要的行业标准技术,负责发现许多安全漏洞并预防更多漏洞。然而,很好地模糊化需要时间,并且模糊化嵌入式软件带来了额外的挑战。
嵌入式平台不是为通过模糊查找错误所需的工具和高通量计算而设计的。在不访问源代码的情况下,此类平台的实际模糊化需要速度较慢的仿真器,或者需要许多物理设备,而这通常是不切实际的。
大多数模糊方法都使用传统的CPU架构或仿真器,但我们决定使用其他商用硬件来解决这个问题-特别是GPU。最近机器学习的繁荣压低了GPU的非高峰价格,并使所有主要的云提供商都可以轻松获得巨大的GPU计算能力。GPU非常擅长并行执行任务,而模糊化是一个很容易并行化的问题。
在这篇博客文章中,我将带你完成这个基于GPU的大规模并行模糊器的设计和实现。到目前为止,我们已经实现了一个执行引擎,它可以实现比libFuzzer多5倍的执行/秒/美元-而且还有更大的优化空间。
模糊的目的是向程序生成意外的输入,并导致不想要的行为(例如,崩溃或内存错误)。最常用的模糊器是覆盖率引导的模糊器,它专注于查找导致新代码覆盖的输入(例如执行以前没有执行过的函数),以探索可能导致程序崩溃的边缘情况。
为此,模糊器通过目标程序运行许多不同的随机输入。此任务很容易并行化,因为每个输入都可以独立于其他输入执行。
GPU相当便宜;在Google Cloud上购买一辆可抢占的特斯拉T4的价格是0.11美元/小时。此外,GPU非常擅长并行执行许多事情-特斯拉T4可以在40,000多个线程之间进行上下文切换,并可以同时执行其中的2,560个线程-如上所述,模糊是一个自然可以并行化的问题。使用数千个线程,理论上我们应该能够同时测试数千个不同的输入。
简而言之,在几个关键方面,在GPU上运行代码与在CPU上运行代码有很大的不同。
首先,GPU不能直接执行x86/aarch64/等指令,因为GPU有自己的指令集。我们的目标是模糊没有源代码的嵌入式软件。由于手头只有一个二进制文件,我们没有简单的方法来生成要运行的GPU程序集。
其次,GPU没有操作系统。传统的并行模糊器可以启动多个进程,这些进程可以单独执行输入,而不会干扰其他进程。如果输入导致一个进程崩溃,其他进程不会受到影响。GPU没有进程或地址空间隔离的概念,任何内存违规都会导致整个Fuzzer崩溃,因此我们需要找到某种方法来隔离正在Fuzize的程序的并行实例。
此外,如果没有操作系统,就没有人在家应答系统调用,这些调用使程序能够打开文件、使用网络等。系统调用必须被仿真或中继回CPU才能由主机操作系统执行。
最后,GPU内存很难管理好。GPU具有复杂的内存层次结构,具有几种不同类型的内存,并且每种内存都具有不同的易用性和性能特征。性能高度依赖于内存访问模式,控制线程访问内存的时间和方式可以决定应用程序的成败。此外,没有太多内存可供分配,这使得正确管理内存布局和访问模式变得更加困难。拥有16 GB的设备内存听起来可能令人印象深刻,但将其分配给40,000个执行线程,每个线程只有微不足道的419 KiB。
要构建一个可以工作的GPU模糊器有很多障碍,但没有一个是不可逾越的。
首先,让我们看看是否可以在GPU上运行aarch64二进制文件。
如前所述,我们希望模糊化嵌入式二进制文件(例如,ARMv7、aarch64等)。在GPU上。NVIDIA GPU使用一种不同的指令集架构,称为PTX(“并行线程执行”),因此我们不能直接执行我们想要模糊的二进制文件。这个问题的一个常见解决方案是仿真嵌入式CPU,但是为GPU开发CPU仿真器可能是一项昂贵的投资,而且性能会很差。另一种选择是将二进制文件转换为PTX,这样它们就可以直接在GPU上执行,而无需仿真。
TRAIL of BITS已经开发了一个叫做REMILL的二进制翻译工具,我们可以用它来做这件事。Remill将二进制文件“提升”到LLVMIR(中间表示),然后可以重定目标并编译到LLVM项目支持的任何架构。碰巧LLVM支持将LLVM IR作为PTX代码发出,这非常适合我们的目的。
假设我们有这个简单的示例函数,它将w19设置为0,加5,然后返回结果:
我们可以将这些指令的字节传递给Remill,它会生成LLVM IR,对在ARM处理器上执行的原始程序进行建模:
然后,通过一些优化,我们可以让LLVM将上面的LLVM IR编译为PTX程序集:
最后,我们可以将此PTX加载到GPU中并执行它,就像我们首先可以访问源代码一样。
如前所述,GPU没有操作系统来提供进程之间的隔离。我们需要实现地址空间隔离,以便模糊化程序的多个实例可以访问同一组内存地址,而不会相互干扰,并且需要检测目标程序中的内存安全错误。
Remill将原始程序中的所有内存访问替换为对特殊函数read_memory和write_memory的调用。通过提供这些功能,我们可以实现一个软件内存管理单元,它可以填补缺失的操作系统功能,并调解内存访问。
例如,考虑以下函数,该函数接受一个指针并递增其指向的整数:
Remill将此程序集转换为以下IR,其中包含READ_MEMORY调用、ADD指令和WRITE_MEMORY调用:
通过提供__REMILL_READ_MEMORY_32和__REMILL_WRITE_MEMORY_32函数,我们可以为每个线程提供自己的虚拟地址空间。此外,我们还可以验证内存访问,并在无效访问使整个模糊器崩溃之前拦截它。
不过,请记住,如果跨40,000个线程共享,16 GB的设备内存实际上并不多。为了节省内存,我们可以在MMU中使用写入时复制策略;线程共享相同的内存,直到其中一个线程写入内存,此时该内存被复制。以这种方式保存内存是一种令人惊讶的有效策略。
太棒了--我们有一些管用的东西!我们可以获取一个二进制程序,将其转换为LLVM,将其转换为PTX,混入一个MMU,然后在数千个GPU线程上并行运行结果。
但是,我们如何实现我们的目标,建立一个模糊,达到10倍的性能每美元与其他模糊的比较呢?
评估Fuzzer是一件非常棘手的事情,已经发表了很多关于如何有效地比较它们的论文。我们的模糊器还太年轻,还不能正确评估,因为我们仍然缺少关键的模糊器组件,如变频器,以生成程序的新输入。要仅测量执行器性能,我们可以查看Fuzzer通过目标程序运行输入的速度(以执行/秒为单位)。通过标准化计算硬件的成本(GPU比运行其他模糊器的CPU更贵),我们可以比较执行/秒/$。
在我们的基准测试中,我们应该模糊什么?出于以下几个原因,libpcap中的BPF数据包过滤代码似乎是一个很好的候选代码:
它实现了一个复杂的状态机,人类很难对其进行推理,这使得它成为模糊化的一个很好的候选者。
BPF组件在过去有过错误,所以这是一个我们可能想要模糊的现实目标。
让我们编写一个测试应用程序,该应用程序从Fuzzer获取数据包并在其上运行复杂的BPF过滤器程序:
这个测试程序没有做很多事情,但是它确实执行了复杂的逻辑,并且需要大量的内存访问。
要评价我们的模糊器,我们可以把它与libFuzzer相比较,libFuzzer是一种应用广泛的快速模糊器。这不是一个完全公平的比较。一方面,libFuzzer解决了一个更简单的问题:它使用测试程序的源代码进行模糊处理,而我们的Fuzzer则翻译并检测为不同架构编译的二进制代码。在安全研究中,源代码通常是不可用的。另一方面,libFuzzer正在执行突变以生成新的输入,而我们没有这样做。虽然显然不完美,但这种比较将足够好地提供数量级的估计。
我使用Google Compute engine 8核N1实例(撰写本文时不可抢占实例的价格为0.379998美元/小时)和Tesla T4GPU(撰写本文时价格为0.35美元/小时)进行了比较。
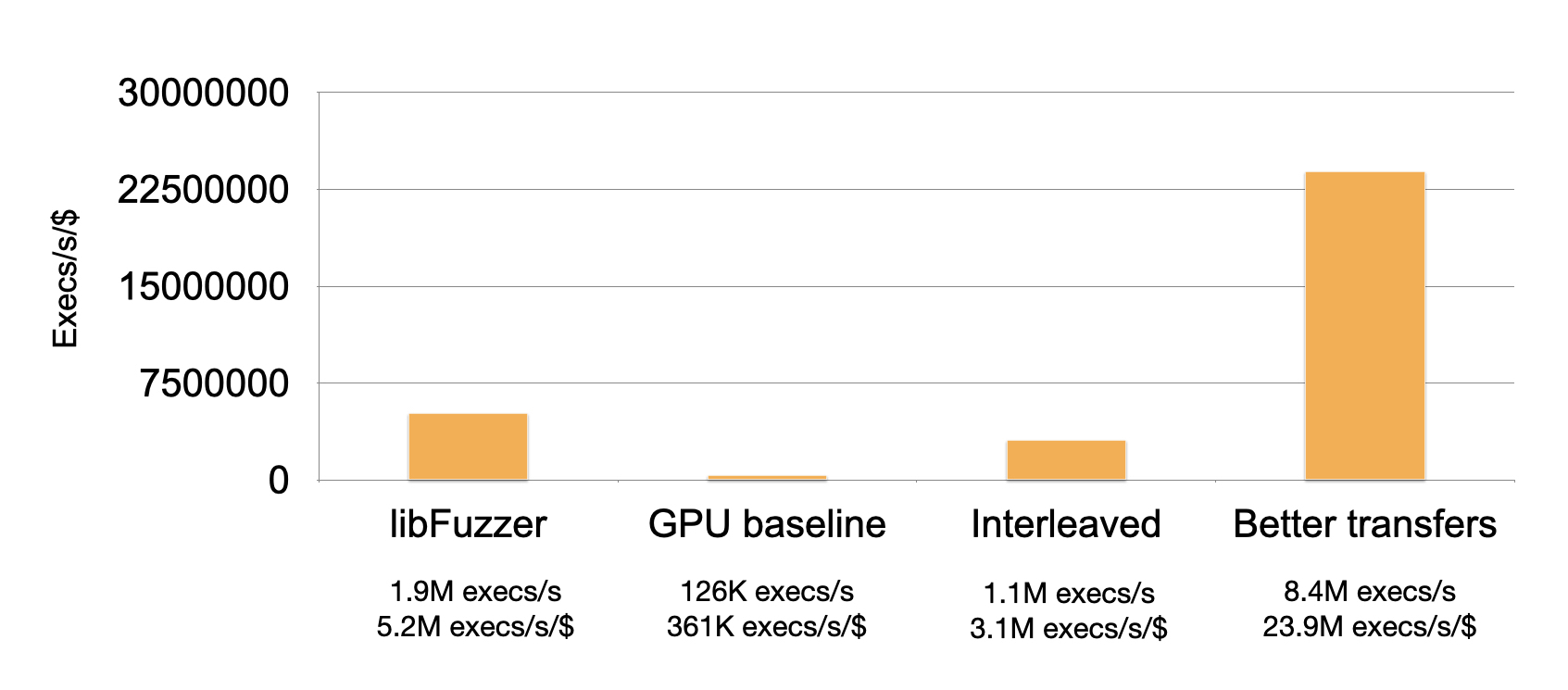
不幸的是,我们的绒毛器比不上libFuzzer。LibFuzzer可以达到520万个execs/s/$,而我们的Fuzzer只能达到361k个execs/s/$。
在我们开始优化性能之前,我们应该分析一下Fuzzer,以便更好地了解它的性能。NVIDIA的NSight Compute Profiler有助于解释硬件利用率和性能瓶颈。
从配置文件中,我们可以看到GPU只使用了其计算能力的3%。大多数情况下,GPU计算硬件处于闲置状态,什么也不做。
这通常是因为内存延迟较高:GPU正在等待内存读/写完成。然而,这并没有发生,因为我们的Fuzzer需要访问太多的内存;配置文件显示GPU只使用了其可用内存带宽的45%。相反,我们访问内存的效率肯定非常低。每次存储器访问都需要很长时间,并且没有提供足够的数据用于计算。
要解决这个问题,我们需要更好地理解GPU的执行模型。
GPU线程以32个为一组执行,称为扭曲。WARP中的所有线程在并行多处理器中一起执行,并且它们以锁步方式运行,即它们同时运行相同的指令。
当线程读取或写入内存时,内存访问以128字节的块为单位进行。如果WARP中的32个线程试图读取位于同一128字节块中的内存,那么硬件将只需要从内存总线请求一个块(一个“事务”)。
然而,如果每个线程都从不同的块读取存储器地址,则硬件可能需要进行32个单独的存储器事务,这些事务通常是串行化的。这导致了我们在配置文件中发现的行为:计算硬件几乎总是空闲的,因为它必须等待如此多的内存事务才能完成。内存带宽利用率看起来并不是很差,因为正在读取许多128字节的区块,但每个区块中只有4或8个字节被实际使用,因此浪费了大量使用的带宽。
目前,我们为每个线程分配单独的内存,因此当一个线程访问内存时,它很少落入与不同线程相同的128字节块中。我们可以通过为一个扭曲(32个线程)分配一个内存片,并在该扭曲内交织线程的内存来改变这一点。这样,当线程需要访问内存中的值时,它们的值都是相邻的,并且GPU可以通过单个内存事务来完成这些内存读取。
尝试一下,我们发现性能提高了一个数量级!显然,在为GPU编程时了解内存访问模式是极其重要的。
重新运行性能分析器,我们可以看到,我们的计算利用率有了很大提高(33%,高于3%),但我们仍远未达到完全利用率。我们能做得更好吗?
继续检查内存使用模式,让我们看看使用的内存类型。NVIDIA GPU有几种位于不同物理位置的内存,但最容易使用的类型称为“统一内存”,它代表我们在不同物理位置之间自动传输数据。我们一直在使用它,因为它不需要我们过多地考虑字节的物理存储位置,但是如果管理不当可能会导致性能瓶颈,因为数据将在物理内存位置之间低效传输。
由于我们仍然看到非常高的内存延迟,让我们更仔细地看看这些传输。
我们的简单模糊器是“轮次”工作的:如果GPU可以运行40,000个线程,我们将40,000个输入传递给GPU,每个线程在我们启动下一轮之前对一个输入进行模糊处理。在两轮之间,我们重置使用的内存(例如,被模糊化的程序使用的覆盖范围跟踪数据结构和内存)。然而,这会导致GPU和CPU之间在每轮之间进行大量数据传输,因为内存会被分页回CPU、重置,然后再分页回GPU。当这些传输正在进行时,GPU什么也不做。当GPU等待CPU启动下一轮时,会产生额外的延迟。
我们可以通过单次启动GPU代码并避免CPU和GPU之间的同步来改进此设置。许多数据不需要在统一内存中;相反,我们可以在GPU上分配全局内存,然后在需要发送有关Fuzization进度的信息(例如,哪些输入导致崩溃)时将数据异步传输到CPU。这样,当线程完成对输入的模糊化时,它可以重置内存并继续进行下一个输入,而不需要数据传输开销,也不需要等待CPU。
这几乎实现了另一个数量级的加速!现在,一美元比libFuzzer快五倍左右。
这是非常有前途的--尽管我们的Fuzzer缺少突变引擎并且不能处理系统调用,但是超过libFuzzer如此程度的性能表明使用GPU的Fuzze对于某些应用程序可能非常有用。
虽然我们已经接近这个测试程序的性能目标,但是这个项目还有很长的路要走。硬件利用率仍然较低,因此还有进一步优化的空间。
此外,我们需要构建对处理系统调用的支持,这在模糊化I/O繁重的应用程序时可能会对性能产生重大影响。在这个Fuzzer有用之前,我们还需要构建突变引擎,尽管这个问题比构建执行引擎更容易理解。
尽管如此,我们仍然非常兴奋能在如此早期的开发阶段获得如此有希望的结果。我们期待在模糊化嵌入式二进制文件方面有一个数量级的改进。
我们很想听听您对这项工作的看法!联系我们:[email protected]或[email protected]。
最后,我要向Artem Dinaburg致以极大的感谢,感谢他对这个系统的初步设计,以及在整个项目过程中对我的指导。同时,感谢Peter Goodman提供设计反馈和调试建议。