通过机器学习和Slither-Simil进行高效的智能合同安全审计
BITS跟踪已经手动管理了大量数据-多年的安全评估报告-现在我们正在探索如何使用这些数据通过Slither-simil提高智能合同审核流程的效率。
基于先前审计中积累的知识,我们着手在新客户的代码库中检测类似的易受攻击的代码片段。具体地说,我们探索了机器学习(ML)方法,以自动改进Slither(我们的静态稳固性分析器)的性能,并使审计师和客户的工作变得更容易。
目前,具有可靠性及其安全细微差别的专业知识的人类审核员扫描和评估可靠性源代码,以发现不同粒度级别的漏洞和潜在威胁。在我们的实验中,我们探索了可以在多大程度上自动化安全评估以实现以下目标:
最大限度地降低再次出现人为错误的风险,即忽略已知的、记录的漏洞的机会。
帮助审计人员更快、更轻松地筛选潜在漏洞,同时降低误报率。
Slither-SIMIL是对Slither的统计添加,是一种代码相似性度量工具,它使用最先进的机器学习来检测类似的坚固性函数。去年,当它作为代号为Crytic-pred的实验开始时,它被用来向量化坚固性源代码片段,并测量它们之间的相似性。今年,我们将把它提升到下一个层次,并将其直接应用于易受攻击的代码。
Slither-SIMIL目前使用其自己的坚固性代码表示Slither Intermediate(Slither Intermediate Presentation,滑动中间表示)来在函数的粒度级别编码坚实度片段。我们认为函数级分析是开始研究的好地方,因为它不会太粗略(如文件级),也不会太详细(如语句或行级)。
在Slither-SIMIL的工作流程中,我们首先从以前归档的安全评估中手动收集漏洞,并将其传输到漏洞数据库。请注意,这些都是审计人员必须在没有自动化的情况下发现的漏洞。
之后,我们编译了以前客户的代码库,并通过自动函数提取和归一化脚本将它们包含的函数与我们的漏洞数据库进行匹配。在此过程结束时,我们的漏洞被标准化的SlitIR标记作为我们ML系统的输入。
下面是我们如何使用Slither将固态函数转换为中间表示Slither IR,然后将其进一步标记化和规范化以作为Slither-simil的输入:
首先,我们将每个语句或表达式转换为其对应的SlitIR,然后对SlitIR子表达式进行标记化,并进一步对其进行规范化,以便尽管此函数的标记与漏洞数据库之间存在表面差异,但仍会出现更相似的匹配。
在获得此函数的最终令牌表示形式后,我们将其结构与漏洞数据库中易受攻击的函数的结构进行了比较。由于Slither-SIMIL的模块性,我们使用了不同的ML体系结构来衡量任意数量的功能之间的相似性。
图5:使用Slither-SIMIL测试来自智能合约和一组其他稳固合约的功能。
让我们看看ETQuality.sol智能契约中的函数transfer From,看看它的结构与我们的查询函数有什么相似之处:
比较这两个函数中的语句,我们可以很容易地看到,它们都以相同的顺序包含一个二进制比较操作(>;=和<;=)、相同类型的操作数比较,以及另一个类似的赋值操作,其中包含一个内部调用语句和一个返回“true”值的实例。
随着相似性分数越低,这种结构相似性越少,而且是在相反的方向上;这两个功能变得更加相同,因此相似性分数为1.0的两个功能彼此相同。
在过去的两年里,关于Solity中的自动漏洞发现的研究已经开始,像Vulcan和SmartEmbed这样的工具,它们使用ML方法来发现智能合同中的漏洞,正在显示出令人振奋的结果。
然而,目前所有的相关方法都集中在静态分析器(如Slither和Mythril)已经可以检测到的漏洞上,而我们的实验则集中在这些工具无法识别的漏洞上-具体地说,就是那些没有被Slither检测到的漏洞。
过去五年的大部分学术研究都集中在提取ML概念(通常来自自然语言处理领域),并在开发或代码分析上下文中使用它们,通常称为代码智能。在此研究领域以前相关工作的基础上,我们的目标是弥合人类审计师和ML检测系统之间的语义鸿沟,以发现漏洞,从而用自动化方法(即机器编程,MP)来补充Trail of BITS人类审计师的工作。
我们仍然面临数据稀缺的挑战,涉及可供分析的智能合同的规模以及其中出现有趣漏洞的频率。我们可以专注于ML模型,因为它很吸引人,但在稳定的情况下,它对我们没有太大的好处,因为即使是语言本身也很年轻,我们需要谨慎对待我们拥有的大量数据。
存档以前的客户数据本身就是一项工作,因为我们必须处理不同的Solc版本来分别编译每个项目。对于在这一领域经验有限的人来说,这是一个挑战,我在这一过程中学到了很多东西。(我暑期实习最重要的收获是,如果你在做机器学习,你不会意识到数据收集和清理阶段的瓶颈有多大,除非你必须这样做。)。
饼图显示了89个漏洞在我们调查的10个客户端安全评估中的分布情况。我们记录了值得注意的漏洞和Slither无法发现的漏洞。
在刚刚过去的这个夏天,我们怀着两个目标继续开发Slither-simil和Slither-simil:
我们使用FastText实现了基于文本的基线模型,并将其与结果有明显显著差异的改进模型进行比较;例如,不研究软件复杂性度量,而只关注基于图形的模型,因为它们是目前最有前途的模型。
为此,我们提出了一系列在最高抽象级别(即源代码)尝试使用固态语言的技术。
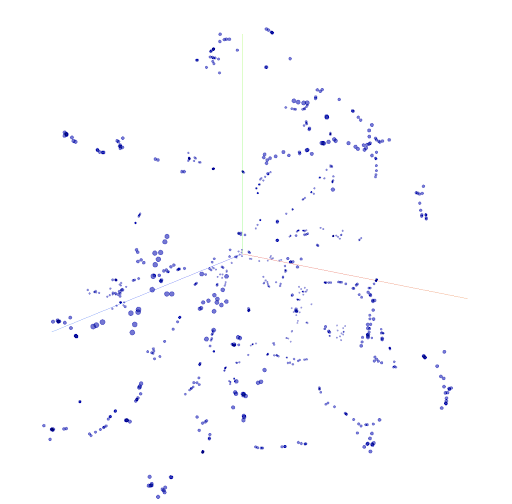
为了建立ML模型,我们同时考虑了监督和非监督学习方法。首先,我们开发了一个基于标记化源代码函数并将其嵌入欧几里得空间(图8)的基线非监督模型,以度量和量化不同标记之间的距离(即,相异度)。因为函数是由标记组成的,所以我们只需将差异相加,就可以得到任意大小的任意两个不同片段之间的(反)相似性。
下图显示了来自在三维欧几里德空间中球化的一组训练稠度数据的SlitIR令牌,其中相似的令牌在矢量距离上彼此更接近。每个紫点显示一个代币。
我们目前正在开发一个专有数据库,其中包括我们以前的客户及其公开可用的易受攻击的智能合同,以及论文和其他审计中的参考资料。它们将共同形成一个统一的、全面的安全漏洞数据库,用于查询、以后的培训和测试较新的模型。
我们还在研究其他无监督和有监督的模型,使用由Slither和Mythril等静态分析器标记的数据。我们正在研究的深度学习模型具有更强的表现力,我们可以利用抽象语法树和控制流图为源代码建模-具体地说,就是基于图形的模型。
我们期待着检查Slither-simil在新审计任务上的表现,看看它如何提高我们保证团队的工作效率(例如,在分类和更快地找到容易摘到的果实方面)。我们还将在Mainnet上测试它,当它变得更成熟和自动可伸缩时。
你现在可以在这款Github公关上试试Slither-simil。对于最终用户,它是可用的最简单的CLI工具:
输入一个或多个智能合同文件(目录、.zip文件或单个.sol)。
确定一个预先培训的模型,或单独培训一个模型,使其具有合理数量的智能合同。
Slither-simil是一种功能强大的工具,有可能测量以实心编写的任意大小的函数片段之间的相似性。我们正在继续开发它,基于目前的结果和最近的相关研究,我们希望在今年年底之前看到有影响力的现实世界结果。
最后,我要感谢我的上级Gustavo,Michael,Josselin,Stefan,Dan,以及Trail of Bits的其他所有人,是他们让这次实习经历成为我有生以来最不平凡的经历。