.NET比C++快,在GRPC_BENCH中下围棋

GRPC是一个现代的开源远程过程调用框架。GRPC有许多令人兴奋的特性:实时流、客户端到服务器代码生成,以及很好的跨平台支持,仅举几例。对我来说,最令我兴奋的是性能,这也是对GRPC感兴趣的开发人员不断提到的。
去年,微软为CNCF贡献了一个新的GRPC for.NET实现。构建在Kestrel和HttpClient之上的GRPC for.NET使GRPC成为.NET生态系统的一流成员。
在我们的第一个GRPC for.NET版本中,我们重点介绍了GRPC的核心特性、兼容性和稳定性。在.NET5中,我们让GRPC变得非常快。
在不同GRPC服务器实现的社区运行基准中,.NET在Rust之后获得每秒最高的请求,并且仅仅领先于C++和Go。
我们的基准测试表明.NET5服务器的性能比.NET Core3.1快60%。.NET 5客户端性能比.NET Core 3.1快230%。
Stephen Toub在他的.NET5博客文章中讨论了DotNet/运行时的变化。请查看它以了解HttpClient和HTTP/2中的改进。
在这篇博客文章的其余部分,我将谈论我们在ASP.NET Core中为使GRPC更快所做的改进。
GRPC使用HTTP/2作为其底层协议。当涉及到性能时,快速的HTTP/2实现是最重要的因素。我们的GRPC服务器构建在Kestrel之上,Kestrel是用C#编写的HTTP服务器,其设计考虑了性能。Kestrel是TechEmpower基准测试中的顶级竞争者,GRPC自动受益于Kestrel的大量性能改进。但是,.NET5中进行了许多特定于HTTP/2的优化。
减少拨款是一个很好的起点。每个HTTP/2请求的分配越少,执行垃圾收集(GC)的时间就越少。而GC中“浪费”的CPU时间是未用于服务HTTP/2请求的CPU时间。
上面的性能分析器正在测量超过100,000个GRPC请求的分配。活动对象图的锯齿状图案表明内存正在积累,然后被垃圾收集。每个请求被分配的大小约为3.9KB。让我们试着把这个数字记下来!
Dotnet/aspnetcore#18601在HTTP/2连接中添加了流池。这一更改几乎将每个请求的分配减少了一半。它允许跨多个请求重用内部类型(如Http2Stream)和可公开访问的类型(如HttpContext和HttpRequest)。
Dotnet/aspnetcore#19356重用输入和输出管道实例。PIPE是分配的最大单一贡献者。
Dotnet/aspnetcore#19431重用已知的报头字符串值。与报头重用相关,dotnet/aspnetcore#19457添加了http/2伪报头作为已知报头。字符串分配使用第三大字节。
虽然当服务器负载过重时,池化很好,但我们希望释放不再使用的内存。如果流在最近5秒内没有被HTTP请求使用,dotnet/aspnetcore#24767将从池中删除这些流。
还有许多较小的分配节省。Dotnet/aspnetcore#19783删除了Kestrel的HTTP/2流控制中的分配。每次触发流控制时,可重置的ManualResetValueTaskSourceCore<;T>;类型将替换分配新对象。在验证HTTP请求路径时,dotnet/aspnetcore#19273用stackalloc替换数组分配。Dotnet/aspnetcore#19277和dotnet/aspnetcore#19325消除了一些与日志记录相关的意外分配。如果任务已经完成,dotnet/aspnetcore#22557会避免分配任务。最后,dotnet/aspnetcore#19732通过特殊的大小写内容长度0保存字符串分配。因为每个分配都很重要。
在.NET5中,每个请求的内存现在只有330B,减少了92%。锯齿图案也消失了。减少分配意味着在服务器处理100,000个GRPC调用时根本不运行垃圾收集。
HTTP/2中的热路径是读写HTTP报头。HTTP/2连接支持TCP套接字上的并发请求,这是一种称为多路复用的功能。多路复用允许HTTP/2有效利用连接,但一次只能处理连接上一个请求的报头。HTTP/2的HPack报头压缩是有状态的,并且取决于顺序。处理HTTP/2报头是一个瓶颈,因此必须尽可能快。
Dotnet/aspnetcore#23083优化了HPackDecoder的性能。解码器是读取传入HTTP/2报头帧的状态机。这里的方法很好,状态机允许Kestrel在帧到达时解码,但解码器在解析每个字节后检查状态。另一个问题是文字值(头名称和值)被多次复制。此PR中的优化包括:
收紧解析循环。例如,如果我们刚刚解析了一个头名称,则该值必须在后面。不需要检查状态机来计算出下一个状态。
一起跳过文字解析。HPack中的文字具有长度前缀。如果我们知道接下来的100个字节是文字,那么就不需要检查每个字节。标记文字的位置,并在其末尾继续解析。
避免复制文字字节。以前的文字字节总是在传递给Kestrel之前复制到中间数组。大多数情况下,这并不是必需的,相反,我们可以只对原始缓冲区进行切片,并将ReadOnlySpan<;byte>;传递给Kestrel。
总而言之,这些更改显著减少了解析标头所需的时间。标题大小几乎不再是一个因素。解码器标记值的开始和结束位置,然后对该范围进行切片。
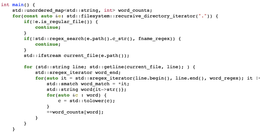
Private HPackDecoder_Decoder=CreateDecoder();private byte[]_simHeader=new byte[]{/*HPack bytes*/};private byte[]_largeHeader=new byte[]{/*HPack bytes*/};private IHttpHeadersHandler_noOpHandler=new NoOpHeadersHandler();[Benchmark]public void SmallDecode()=&gT;_decder.Decode(_SmallHeaders,endHeaders:true,handler:_noOpHandler);[Benchmark]public LargeDecode()=>;_decder.Decode()=>(_largeHeader,endHeaders:true,Handler:_OpnoHandler);[Benchmark]public void SmallDecode()=>;[Benchmark]public void LargeDecode()=>(_largeHeader,endHeaders:true,Handler:_OpnoHandler);
一旦标题被解码,Kestrel需要验证和处理它们。例如,需要将特殊的HTTP/2标头(如:Path和:Method)设置为HttpRequest.Path和HttpRequest.Method,而其他标头需要转换为字符串并添加到HttpRequest.Headers集合。
Kestrel具有已知请求头的概念。已知标头是为快速设置和获取而优化的一组常见请求标头。Dotnet/aspnetcore#24730将用于设置HPack静态表头的更快路径添加到已知头。HPack静态表给出了61个常见的报头名称和值,可以发送一个数字ID来代替全名。具有静态表ID的标头可以使用优化路径绕过某些验证,并根据其ID在集合中快速设置。dotnet/aspnetcore#24945为具有名称和值的静态表ID添加了额外的优化。
在.NET5之前,Kestrel支持读取请求中的HPack压缩头,但不压缩响应头。响应头压缩的明显优势是网络使用量较少,但也有性能优势。为压缩的报头写入几个比特要比编码和写入报头的全名和值(以字节为单位)要快。
Dotnet/aspnetcore#19521添加了初始HPack静态压缩。静态压缩非常简单:如果标头在HPack静态表中,则写入ID来标识标头,而不是较长的名称。
动态HPack报头压缩更复杂,但也提供了更大的收益。在动态表中跟踪响应标头名称和值,并为每个响应标头分配一个ID。写入响应标头时,服务器会检查标头名称和值是否在表中。如果匹配,则写入ID。如果没有,则写入完整的标头,并将其添加到表中以供下一次响应。动态表的大小是最大的,因此向其添加标题可能会以先进先出的顺序逐出其他标题。
Dotnet/aspnetcore#20058增加了动态HP包头压缩。为了快速搜索标题,动态表使用基本哈希表对标题条目进行分组。为了跟踪顺序并逐出最旧的标头,条目维护一个链表。为避免分配,删除的条目将汇集并重复使用。
使用Wireshark,我们可以看到报头压缩对此示例GRPC调用的响应大小的影响。.NET Core 3.x写了77B,而.NET5只写了12B。
GRPC for.NET使用Google.Protobuf包作为消息的默认序列化程序。Protobuf是一种高效的二进制序列化格式。Google.Protobuf是为提高性能而设计的,它使用代码生成而不是反射来序列化.NET对象。可以向其添加一些现代的.NETAPI和功能,以减少分配并提高效率。
对Google.Protobuf最大的改进是对现代.NET IO类型的支持:span<;T>;、ReadOnlySequence<;T>;和IBufferWriter<;T>;。这些类型允许使用Kestrel公开的缓冲区直接序列化GRPC消息。这节省了Google.Protobuf在序列化和反序列化Protobuf内容时分配中间数组。
对Protobuf缓冲区序列化的支持是微软和谷歌工程师多年的努力。更改分布在多个存储库中。
协议缓冲区/协议缓冲区#7351和协议缓冲区/协议缓冲区#7576为Google.Protobuf添加了对缓冲区序列化的支持。这是迄今为止最大、最复杂的变化。在找到性能、向后兼容性和代码重用之间的正确平衡之前,我们进行了三次添加此功能的尝试。Protobuf读写使用了许多添加到C#和.NET核心中的面向性能的功能和API:
Span<;T>;和C#ref结构类型支持快速、安全地访问内存。Span<;T>;表示任意内存的连续区域。使用SPAN允许我们序列化到托管.NET数组、堆栈分配的数组或非托管内存,而无需使用指针。Span<;T&>和.NET可保护我们免受缓冲区溢出。
Stackalloc用于创建基于堆栈的数组。当需要较小的缓冲区时,stackalloc是避免分配的有用工具。
低级方法(如MemoryMarshal.GetReference()、Unsafe.ReadUnalized()和Unsafe.WriteUnaligned())直接在基元类型和字节之间转换。
BinaryPrimites具有在.NET基元类型和字节之间进行高效转换的帮助器方法。例如,BinaryPrimives.ReadUInt64LittleEndian读取很少的Endian字节并返回一个无符号的64位数字。BinaryPrimitive提供的方法经过了大量优化,并使用了矢量化。
现代C#和.NET的一个伟大之处在于,可以在不牺牲内存安全的情况下编写快速、高效、低级的库。当谈到性能时,.NET让您两全其美!
Private TestMessage_testMessage=CreateMessage();private ReadOnlySequence<;byte>;_testData=CreateData();private IBufferWriter<;byte>;_BufferWriter=CreateWriter();[Benchmark]public iMessage ToByteArray()=>;_testMessage.ToByteArray();[Benchmark]public iMessage ToBufferWriter()=>;_testMessage.WriteTo(_bufferWriter);[Benchmark]public iMessage FromByteArray()=>;TestMessage.Parser.ParseFrom(CreateBytes());[Benchmark]public iMessage FromMessage.ParseFrom(__Data);
向Google.Protobuf添加对缓冲区序列化的支持只是第一步。GRPC for.NET需要做更多工作才能利用新功能:
Grpc/Grpc#18865和Grpc/Grpc#19792将ReadOnlySequence<;byte>;和IBufferWriterbyte>;API添加到Grpc.Core.Api中的GRPC序列化抽象层。
GRPC/GRPC-DotNet#376和GRPC/GRPC-DotNet#629更新GRPC for.NET以使用Grpc.Core.Api中的新序列化抽象。此代码是Kestrel和GRPC之间的集成。因为Kestrel的IO构建在System.IO.Pipeline之上,所以我们可以在序列化期间使用它的缓冲区。
最终结果是GRPC for.NET将Protobuf消息直接序列化到Kestrel的请求和响应缓冲区。中间数组分配和字节副本已从GRPC消息序列化中删除。
性能是.NET和GRPC的一个特性,随着云应用的扩展,它比以往任何时候都更加重要。我想所有的开发人员都会同意,开发快速的应用程序很有趣,但性能会对现实世界产生影响。更低的延迟和更高的吞吐量意味着更少的服务器。这是一个省钱、减少用电量和开发更环保应用程序的机会。
从这次巡视中可以明显看出,GRPC、Protobuf和.NET中有很多旨在提高性能的更改。我们的基准测试显示,GRPC服务器RPS提高了60%,GRPC客户端RPS提高了230%。
.NET5RC2现在可以使用,官方的.NET5发行版将在11月发布。要尝试性能改进并开始在.NET中使用GRPC,最好的起点是在ASP.NET核心中创建GRPC客户端和服务器教程。
我们期待着听到关于使用GRPC和.NET构建的应用程序的消息,并期待您将来在DotNet和GRPC Repos中做出的贡献!