综合数据保险库(SDV):用于数据集建模的Python库
在数据科学中,您通常需要一个实际的数据集来测试您的概念证明。创建捕获实际数据行为的伪造数据有时可能是一项相当棘手的任务。几个python软件包尝试实现此任务。很少有流行的python软件包是Faker,Mimesis。但是,大多数情况下会生成简单的数据,例如生成名称,地址,电子邮件等。
要创建捕获复杂数据集属性的数据(例如具有以某种方式捕获实际数据的统计属性的时间序列),我们将需要使用不同方法生成数据的工具。 Synthetic Data Vault(SDV)python库是使用统计和机器学习模型对复杂数据集建模的工具。对于使用数据和建模的任何人,此工具都可以是工具箱中的一个很棒的新工具。
我对该工具感兴趣的主要原因是为了进行系统测试:拥有从相同的实际基础流程生成的数据集会更好。这样,我们可以在现实的场景中测试我们的工作/模型,而不是在不现实的情况下进行测试。我们需要合成数据还有其他原因,例如数据理解,数据压缩,数据扩充和数据隐私[1]。
合成数据仓库(SDV)最初是在论文“合成数据仓库”中介绍的,然后在Neha Patki的主论文“合成数据仓库:关系数据库的生成模型”中的生成建模环境中使用。最后,SDV库是Andrew Montanez硕士论文“ SDV:用于合成数据生成的开源库”的一部分。雷旭(“使用条件GAN合成表格数据”)完成了向SDV添加新功能的另一篇硕士论文。
所有这些工作和研究都是在MIT数据到AI实验室中,在MIT信息与决策系统实验室(LIDS,MIT)的首席研究科学家Kalyan Veeramachaneni的监督下进行的。
之所以要介绍SDV的历史,是为了感谢该图书馆所进行的大量工作和研究。此处提供了一篇有趣的文章,探讨了使用此工具的潜力,尤其是在数据隐私方面。
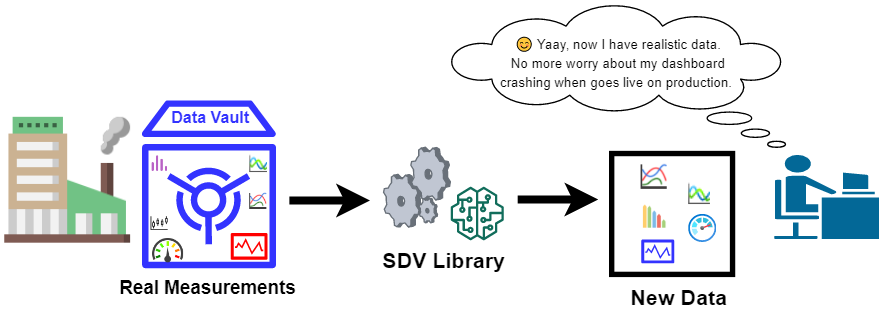
该库的工作流程如下所示。用户提供数据和架构,然后将模型拟合到数据。最后,从拟合模型中获得了新的综合数据[2]。此外,SDV库允许用户保存适合的模型(model.save(“ model.pkl”)),以备将来使用。
概率自回归(PAR)模型用于对多类型多元时间序列数据进行建模。 SDV库在PAR类中实现了此模型(来自时间序列模块)。
让我们举一个例子来解释PAR类的不同参数。我们将处理多个城市的温度时序。数据集将具有以下列:日期,城市,测量设备,位置,噪音。
序列索引:这是具有行依赖性的数据列(应按日期时间或数值排序)。在时间序列中,这通常是时间轴。在我们的示例中,序列索引将是“日期”列。
实体列:这些列是构成度量组的抽象实体,其中每个组都是一个时间序列(因此,应对每个组中的行进行排序)。但是,不同实体的行彼此独立。在我们的示例中,实体列将仅是城市列。顺便说一下,我们可以有更多的列,因为参数类型应该是一个列表。
上下文列:这些列提供有关时间序列实体的信息,并且不会随时间变化。换句话说,上下文列在组内应保持不变。在我们的示例中,“测量设备”和“上下文位置”列在哪里。
数据列:不属于上述类别的任何其他列将被视为数据列。 PAR类没有用于分配数据列的参数。因此,在前三个类别中未列出的其余列将自动被视为数据列。在我们的示例中,“噪声”列是数据列。
时间序列的PAR模型是从sdv.timeseries模块的PAR()类中实现的。如果要为单个时间序列数据建模,则只需将PAR()类的sequence_index参数设置为datetime列(该列说明了时间序列的顺序)。魔术发生在第8-16行!
SDV可以具有多个实体,这意味着多个时间序列。在我们的示例中,我们对多个城市进行了温度测量。换句话说,每个城市都有一组将独立处理的度量。
在使用sdv.Metadata()指定数据模式之后,SDV可以通过生成数据来对关系数据集建模。此外,您可以使用库内置函数来绘制实体关系(ER)图。准备好元数据之后,可以使用层次建模算法生成新数据。您可以在这里找到更多信息。
SDV还可以为单个表数据集建模。它使用统计和深度学习模型,这些模型是:
基于表格的通用对抗网络(GAN)(基于“使用条件GAN建模表格数据”一文)。
SDV库提供了使用SDGym库对合成数据生成器进行基准测试以评估合成器性能的功能。您可以在这里找到更多信息。



