HopsFS:比AWS S3快100倍
TLDR;许多开发人员认为S3是“文件系统历史记录的终结”。在AWS上构建可以与S3竞争成本的文件/对象存储系统是不可能的。但是,如果您可以在S3之上构建具有HDFS API的分布式文件系统,该系统可为您提供POSIX优势并提高性能呢?这就是我们使用云本地版本的HopsFS所做的工作,该版本在可用性区域中具有很高的可用性,成本与S3相同,但是在文件移动/重命名操作方面,S3的性能是S3的100倍,而S3的读取吞吐量是3.4倍(EMRFS)用于DFSIO基准测试(同行评审在ACM中间件2020中进行)。
由于其可扩展性,高可用性和低成本,S3已成为AWS中事实上的存储平台。但是,与分布式分层文件系统相比,S3提供的保证较弱且性能较低。尽管如此,许多开发人员错误地认为S3是文件系统历史的终结-没有替代S3的选择,因此只需重新编写应用程序以解决其限制(例如缓慢且不一致的文件列表,非原子文件/目录)重命名,封闭的元数据和有限更改数据捕获(CDC)支持)。 Azure在Azure Blob存储(ABS)服务的基础上构建了改进的文件系统Azure数据湖存储(ADLS)V2。 ADLS提供了HDFS API来访问存储在ABS容器中的数据,从而提高了性能并具有类似POSIX的优势。但是,直到今天,S3还没有等效于ADLS的产品。今天,我们将HopsFS作为Hopsworks的一部分启动。
分层的分布式文件系统(如HDFS,CephFS,GlusterFS)在云中的可用区域中的可伸缩性不足或高度不可用,从而促使人们选择S3作为可伸缩存储服务。除了技术挑战之外,AWS还对虚拟机存储和互用性区域网络流量定价过高,以至于没有第三方供应商可以构建一个存储系统,其每字节存储成本的价格接近S3。
但是,迁移到S3并非没有代价。许多应用程序需要重写,因为S3中弱化了的保证已取代了分层文件系统中更强的类似于POSIX的行为(原子移动/重命名,一致的文件列表,一致的写后读)。当您拥有足够的文件时,即使简单的任务(例如找出您拥有的文件)也无法在S3上轻松完成,因此引入了一项新服务,使您可以支付更多费用来获取文件的陈旧清单。大多数分析应用程序(例如在EMR上)使用EMRFS而不是S3,这是S3的新元数据层,它提供比S3稍强的保证-例如一致的文件列表。
从更强大的类似于POSIX的文件系统到较弱的对象存储范式再到返回的过程,与数据库近年来的过程相似。数据库从高度一致的单主机系统(关系数据库)过渡到高可用性(HA),最终从一致的分布式系统(NoSQL系统)过渡到处理由数据库管理的数据的大量增加。但是,对于开发人员而言,NoSQL太难了,并且数据库正在返回具有诸如Spanner,CockroachDB,SingleSQL和MySQL Cluster之类的数据库的高度一致(但现在可扩展)的NewSQL系统。
在此博客中,我们展示了分布式分层文件系统正在完成类似的过程,从高度一致的POSIX兼容文件系统到对象存储(具有较弱的一致性模型,但跨数据中心的可用性很高),再回到分布式分层文件跨数据中心的高可用性系统,而不会造成性能损失,并且最重要的是不会增加成本,因为我们将S3用作文件系统的块存储。
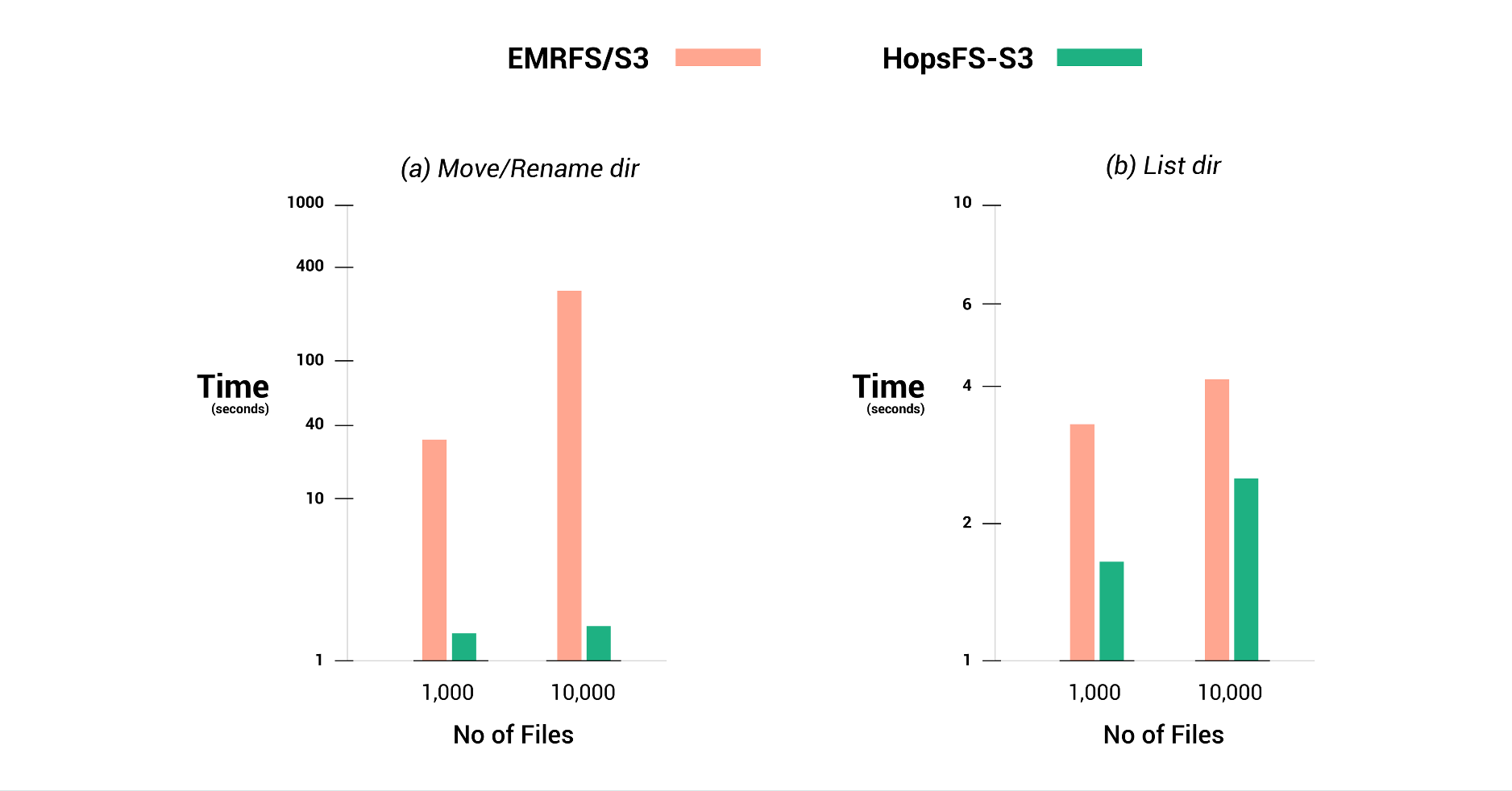
HopsFS是一个分布式的分层文件系统,提供了HDFS API(类似于POSIX的API),但将其数据存储在S3的存储桶中。我们将HopsFS重新设计为(1)在云中的各个可用区域具有高可用性,并且(2)在不牺牲文件系统语义的情况下透明地使用S3存储文件块。 HopsFS中的原始数据节点现在已成为无状态工作程序(标准Hopsworks集群的一部分),其中包括新的块缓存服务,以利用更快的本地VM存储来处理热块。需要特别注意的是,缓存是全局缓存,而不是其他供应商的Spark工作者中发现的本地工作者缓存,其中包括对缓存的安全访问控制。在我们的实验中,我们显示出HopsFS优于IO绑定工作负载的EMRFS(在DynamoDB中具有元数据的S3,以提高性能),性能提高了20%,并提供了3.4倍的EMRFS聚合读取吞吐量。此外,我们证明了HopsFS上的元数据操作(例如目录重命名或文件移动)比EMRFS快两个数量级。最后,HopsFS在S3中打开当前关闭的元数据,并通过HopsFS的变更数据捕获(CDC)API和元数据的自定义扩展来启用正确排序的变更通知。
在Logical Clocks,我们利用HopsFS的功能构建了业界第一个用于机器学习的功能存储(Hopsworks功能存储)。 Hopsworks Feature Store建立在Hops Hive和对HopsFS的自定义元数据扩展的基础上,从而确保了脱机Feature Store,在线Feature Store(NDB群集)和HopsFS中的数据文件之间的高度一致性。
ePipe以正确的顺序将文件系统突变事件流以低延迟交付给下游客户端。
可以将文件系统名称空间元数据更改透明地复制到Elasticsearch,以进行名称空间及其扩展元数据的低延迟自由文本搜索。该服务由Hopsworks提供。
HopsFS中的工作人员使用本地VM存储代表客户端安全地缓存文件块。 NameNode具有缓存意识,并重定向客户端以安全地从正确的工作程序中读取缓存的块。
我们将HopfFS与EMRFS而非S3的性能进行了比较,因为EMRFS在组成文件列表和对对象进行一致的更新后读取方面提供了比S3更强的保证。 EMRFS使用DynamoDB存储S3元数据的部分副本(例如在给定目录中找到了哪些文件/目录),与S3相比,可以更快地列出文件/目录,并具有更高的一致性(一致的文件列表和一致的更新后读取) ,尽管没有原子重命名)。
以下是我们经过同行评审的研究论文中的一些精选结果,这些研究论文被接受在ACM / IFIP Middleware 2020上发表。该论文包含的结果超过了下表所示的内容,并且对于写作,HopsFS平均约占EMRFS性能的90%- HopsFS的开销是先写给工作人员,然后再写给S3。 HopsFS具有全局工作程序缓存(如果将块缓存在任何工作程序上,则客户端将直接从工作程序中检索数据)以加快读取速度,并且HopsFS的元数据层建立在NDB群集上以加快元数据操作。
*增强的DFSIO基准测试结果,具有16个并发任务,可读取1GB文件。对于更高的并发级别(64个任务),性能提高从3.4倍降至1.7倍。
**截至2020年11月,每个S3前缀每秒最大PUT / COPY / POST / DELETE数量为3500 ops / sec,而每个前缀最大GET / HEAD请求数量为5500次读取/秒。您可以通过并行读/写不同的前缀来提高S3中的吞吐量,但这可能需要重写应用程序代码并增加错误的风险。对于HopsFS(不带S3),我们证明了它可以在3个可用区中达到160万个元数据操作/秒。
在ICDCS上发表的论文中,我们在3个可用区上以HA模式部署时测量了HopsFS的吞吐量。使用Spotify的工作负载,我们将性能与CephFS进行了比较。当两者均以完全HA模式部署时,HopsFS(1.6M ops / sec)达到CephFS吞吐量(800K ops / sec)的2倍。但是,CephFS当前不支持将其数据存储在S3存储桶中。
HopsFS可作为开源(Apache V2)使用。但是,云本地HopsFS当前仅作为hopsworks.ai平台的一部分提供。 Hopsworks.ai是用于大规模设计和运行AI应用程序的平台,并支持Spark,Flink,TensorFlow等形式的可扩展计算(与Databricks或AWS EMR相比)。您还可以将Hopsworks.ai连接到Kubernetes集群,并在Kubernetes上启动可以从HopsFS读取/写入的作业。您将群集连接到您的AWS账户中的S3存储桶,或者将Azure上的连接到Azure Blob存储存储桶。您可以动态地向集群添加/从集群中删除工作程序,并且工作程序充当HopsFS集群的一部分-使用最少的资源,但代表客户端向S3或ABS读写数据,提供访问控制和缓存块以便更快地检索。
Ismail Mahmoud,Salman Niazi,Gautier Berthou,MikaelRonström,Seif Haridi,Jim Dowling。 HopsFS-S3:使用类似POSIX的语义等扩展对象存储。 ACM / IFIP中间件2020。
Ismail Mahmoud,Salman Niazi,Mauritz Sundell,MikaelRonström,Seif Haridi,Jim Dowling。分布式分层文件系统在云中反击。 ICDCS 2020。
Ismail Mahmoud,MikaelRonström,Seif Haridi,Jim Dowling。 ePipe:HopsFS元数据的接近实时多语种持久性。 CC Grid 2019。



