可视解释SQL的递归
在SQL递归?但为什么?哦,有很多用途。在SQL中通常存储分层数据,而递归查询是从此类图表中提取信息的便捷方法。组织结构,应用程序菜单结构,项目中带有子任务的一组任务,网页之间的链接,将设备模块分解为多个部分和子部分的内容就是分层数据的示例。这篇文章不会详细介绍许多用例,而是看两个玩具示例来理解这个概念-最简单的数字递归和从族谱中查询数据的案例。
让我们考虑将查询作为函数。从某种意义上说,一个函数接受输入并产生输出。查询对关系进行操作,或者可以说表。我们将其表示为Rn。这是查询的图片。它具有三个关系R1,R2,R3,并产生输出R。足够简单。
查询(SELECT 1 AS n)现在有一个名称-R。我们可以稍后再使用该名称。这里R是包含数字1的单行单列表。整个表达式的结果是数字2。
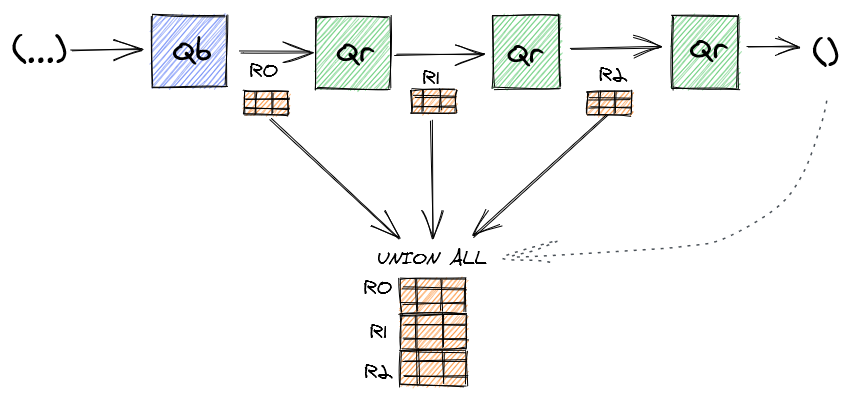
为了使递归正常工作,我们需要从一些事情开始,并决定何时应停止递归。为了实现这一点,通常使用语句的递归具有以下形式。
重要的是要注意,基本查询不涉及R,但是递归查询引用R。从最初的样子看,似乎是无限循环,要计算R,我们需要计算R。但这很重要。 R实际上并不引用自身,它仅引用先前的结果,并且当先前的结果为空表时,递归将停止。实际上,它可以将其作为迭代而不是递归来帮助!
这是发生了什么:首先执行基本查询,并采用所需的任何方法来计算结果R0。以R0作为输入执行第二个递归查询,即R在第一次执行时在递归查询中引用R0。递归查询产生结果R1,这就是R在下一次调用时将引用的结果。依此类推,直到递归查询返回空结果。那时所有中间结果都合并在一起。
基本查询返回数字1,递归查询将其以countUp名称命名并产生数字2,这是下一个递归调用的输入。当递归查询返回空表(n> = 3)时,调用结果将堆叠在一起。
提防,这样算数只能走那么远。递归是有限制的。它的默认值为100,但可以使用MAXRECURSION选项进行扩展。实际上,提高递归限制可能不是一个好主意。图可能具有循环,并且有限的递归深度可能是阻止行为不佳的查询的良好防御机制。
基本查询会找到Frank的父母-Mary,递归查询会以祖先的名字获取此结果,并找到Mary的父母Dave和Eve,一直到我们找不到任何父母为止。
现在,此树遍历查询可以成为用其他一些感兴趣的信息扩展查询的基础。例如,表中有出生年份,我们可以计算出孩子出生时父母的年龄。下一个查询完全可以做到这一点,并显示沿袭。为此,它从上到下遍历树。 parentAge在第一行中为零,因为我们无法从现有数据中得知爱丽丝何时出生。
带走—递归查询引用了基础查询或递归查询的先前调用的结果。当递归查询返回空表时,链停止。
在后续文章中,我们将对SQL递归进行代数分析,并研究递归存储过程。