现实世界中的拜占庭式失败
当我们在Cloudflare审查设计文档时,我们总是在寻找单点故障(SPOF)。消除这些是构建您有信心的系统的必要步骤。具有讽刺意味的是,当您设计具有内置冗余的系统时,您会花费大量时间来考虑丢失冗余时系统的功能。
2020年11月2日,Cloudflare发生了一个事件,该事件在6小时33分钟内影响了API和仪表板的可用性。在此事件期间,对我们API的查询成功率周期性下降至75%,并且仪表板体验比正常情况下慢80倍之多。尽管Cloudflare的优势已在全球范围内广泛分布(并且一直保持正常运行),但Cloudflare的控制平面(API和仪表板)由大量的在两个区域冗余的微服务组成。对于大多数服务,支持这些微服务的数据库一次只能写在一个区域中。
每个Cloudflare的控制平面数据中心都有多个服务器机架。这些机架中的每个机架都具有两个成对工作的开关-通常都处于活动状态,但是如果另一个发生故障,则其中一个可以处理负载。 Cloudflare通过在机架之间分布最关键的服务来抵抗机架级故障。每个硬件都有两个或多个电源不同的电源。每台存储关键数据的服务器都使用RAID 10冗余磁盘或存储系统,它们可以在不同机架中的至少三台计算机之间(或同时在这两者之间)复制数据。我们需要审查和要求每一层都有冗余。那么-怎么会出错?
在这篇文章中,我们介绍了发生的事情的时间表,以及称为拜占庭式故障的困难故障模式如何在一系列事件中发挥了作用。
14:43,网络交换机开始行为异常。警报开始触发有关ping无法到达的开关。设备处于部分运行状态:LACP和BGP等网络控制平面协议仍可运行,而vPC等其他协议则未运行。 vPC链接用于在多个交换机之间同步端口,以使它们在连接到与它们相连的服务器时显示为一台大型聚合交换机。同时,数据平面(或转发平面)未处理和转发从连接的设备收到的所有数据包。
由于LACP的负载平衡特性,每个服务器只能看到部分流量问题,因此这种故障情况对于连接的节点是完全不可见的。如果交换机完全故障,所有流量都将故障转移到对等交换机,因为所连接的链路将简单地断开,并且端口将从转发LACP捆绑中退出。
六分钟后,切换恢复,无需人工干预。但是这种奇特的故障模式导致了进一步的问题,这些问题在交换机恢复到正常操作后持续了很长时间。
交换机行为异常的机架在我们的etcd集群中包含一台服务器。每当我们需要在多个节点上可靠的高度一致的数据存储时,我们都会在核心数据中心大量使用etcd。
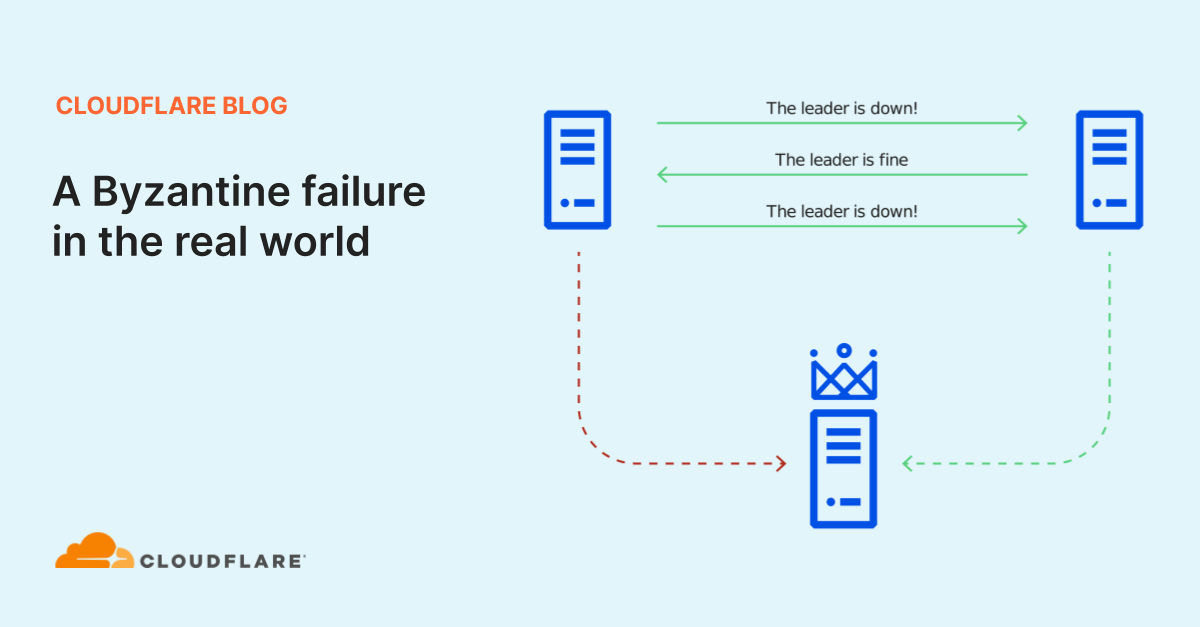
如果集群领导者发生故障,etcd将使用RAFT协议保持一致性并建立共识以提升新领导者。在RAFT协议中,假定群集成员可用或不可用,并且仅提供准确的信息或根本不提供任何信息。当计算机崩溃时,这可以很好地工作,但并不总是能够处理群集中不同成员具有冲突信息的情况。
节点1(在受影响机架中)和节点3(领导者)之间的网络流量正在通过处于降级状态的交换机发送,
节点1和节点2之间的网络流量正在通过其工作对等方,并且
这导致集群成员对现实有冲突的观点,在分布式系统理论中被称为拜占庭式错误。由于此冲突的信息,节点1反复发起了领导者选举,为自己投票,而节点2反复投票了仍可以连接到的节点3。这导致没有促进领导者节点1到达的联系。 RAFT领导者的选举具有破坏性,阻止所有写入,直到它们被解决为止,因此这使群集变为只读,直到故障交换机恢复并且节点1可以再次到达节点3。
Cloudflare的控制平面服务使用跨数据中心内多个群集托管的关系数据库。每个群集均配置为具有高可用性。群集设置包括一个主数据库,一个同步副本和一个或多个异步副本。此设置允许数据中心内的冗余。对于跨数据中心冗余,建立了类似的高可用性辅助群集,并在地理上分散的数据中心中进行复制以进行灾难恢复。集群管理系统利用etcd进行集群成员的发现和协调。
当etcd变为只读时,两个群集无法传达它们具有正常的主数据库的信息。这触发了自动升级同步数据库副本成为新的主副本。此过程自动发生,没有错误或数据丢失。
我们的集群管理系统中存在一个缺陷,当升级一个新的主数据库时,它需要重建所有数据库副本。因此,尽管新的主数据库是立即可用的,但是根据数据库的大小,副本将需要花费大量时间才能变得可用。对于其中一个群集,服务已快速恢复。重建了同步和异步数据库副本,并成功地从主数据库开始复制,并且影响很小。
但是,对于另一个群集,该数据库的高性能操作需要副本在线。由于该数据库处理API调用和仪表板活动的身份验证,因此需要进行大量读取,并且大量使用了一个副本来减轻主数据库的负担。当此故障转移发生且没有副本可用时,主数据库过载,因为它必须承担所有负载。这是主要影响开始的时间。
在这一点上,我们看到主要的身份验证数据库已不堪重负,并开始减少它的负载。我们回拨了将SSL证书推送到边缘,发送电子邮件和其他功能的速率,以为其提供空间来处理额外的负载。不幸的是,由于它的大小,我们知道完全重建一个副本要花费几个小时。
这里有一线希望是,我们主要数据中心中的每个数据库群集在我们次要数据中心中也都具有在线副本。这些副本不是本地故障转移过程的一部分,并且已联机并且在整个事件中都可用。将读取查询引导到这些副本的过程尚未实现自动化,因此我们手动将可能利用这些读取副本利用的API流量转移到了辅助数据中心。这大大改善了我们的API可用性。
与大多数Web应用程序一样,Cloudflare仪表板也具有用户会话的概念。创建用户会话后(每次用户登录),我们将执行一些数据库操作,并在该用户会话期间将数据保留在Redis集群中。与我们的API调用不同,我们的用户会话目前无法在不中断的情况下跨海移动。当我们采取措施改善API调用的可用性时,很不幸,我们使仪表板上的用户体验变得更糟。
该区域目前被设计为在发生灾难时能够跨数据中心进行故障转移,但尚未设计为可同时在两个数据中心中工作。在仪表盘上的用户变得越来越沮丧的第一阶段之后,我们完全无法通过身份验证调用返回到我们的主数据中心,并继续在我们的主数据库上工作,以确保在这种降级状态下我们可以提供最佳的服务水平。
重建第一个数据库副本后,它立即重新投入使用,性能恢复到正常水平。我们重新调整了所有已关闭的服务,以便所有异步处理都可以赶上,并且经过一段时间的监视后,事件已结束。
此事件中的级联故障很有趣,因为每个系统在表面上都具有冗余性。此外,没有系统完全失败-每个系统都进入降级状态。这种结合意味着所发生的事件链很难建模和预测。令人沮丧但又令人放心的是,某些可能的故障模式已经得到解决。
一个团队已经在努力解决需要升级时重建数据库副本的限制。我们的用户会话系统在需要引导流量并进行重新设计的情况下不灵活。
此事件还导致我们重新考虑为自动修复的事情而设置的配置参数。在过去的几年中,将数据库副本升级到主数据库花费的时间远远超过了我们希望的时间,因此,使该过程自动化并能够在一分钟内触发就可以了。同时,对于我们的至少一个数据库,治愈可能比疾病还差,实际上,我们可能不想这么快地调用推广过程。此事件发生后,我们立即调整了配置。
拜占庭容错(BFT)是一个热门的研究主题。解决方案自1982年以来就广为人知,但必须在各种工程设计之间做出选择,包括安全性,性能和算法简单性。大多数通用集群管理系统选择完全放弃BFT,而使用基于PAXOS的协议,或者使用PAXOS的简化版本(例如RAFT),其性能比BFT共识协议更好,更易于理解。在许多情况下,已知容易遭受罕见故障模式攻击的简单协议比难以正确实施或调试的复杂协议更安全。
BFT共识的最初用途是在安全关键型系统中,例如飞机和航天器控制系统。这些系统通常具有严格的实时延迟约束,这些约束要求将共识与应用程序逻辑紧密耦合,从而使这些实现不适用于etcd等通用服务。关于BFT共识的当代研究主要集中在跨越信任边界的应用程序上,这些应用程序需要防止恶意集群成员和故障集群成员的攻击。这些设计更适合于实现诸如etcd之类的通用服务,我们期待与研究人员和开源社区合作,使其适合生产集群管理。
对于中断造成的困难,我们深表歉意,并且随着我们的系统的发展,这种情况正在持续改善。此后,我们已修复了集群管理系统中的错误,并正在继续调整此事件中涉及的每个系统,以更灵活地应对依赖关系的失败。如果您有兴趣大规模解决这些问题,请访问cloudflare.com/careers。
Post Mortem API Postgres中断工程