从Panfrost到生产,都是开源图形的故事
自从上次更新Panfrost(用于Arm的Mali Midgard和Bifrost GPU的开源堆栈)以来,我们一直致力于将驱动程序从Midgard的反向工程起源发展到成熟的堆栈。我们已经全面改革了Gallium驱动程序和后端编译器,因此,Mesa 20.3(计划于月底发布)将具有一些Bifrost支持。
在Panfrost成立的头几年,我们对硬件的所有了解都来自于逆向工程,这种理解已被有关硬件的规范信息所取代。例如,我们现在知道数据结构和指令的规范名称,而在逆向工程过程中我们随意选择了它们的名称。为了加速驱动程序开发,删除未知的魔术场并暴露逻辑错误,我们需要集成此新信息。我们的方法有两个方面:
GenXML是为开源Intel图形驱动程序开发的工具,并经过修改以在VideoCore驱动程序中使用。对于Panfrost,我们修改了Broadcom GenXML,以生成针对Mali GPU优化的我们自己的Panfrost GenXML风格。
在进行逆向工程时,将数据结构布置为C头文件中的临时位域非常方便:
struct mali_blend_mode { 枚举mali_blend_modifier clip_modifier:2; 未签名的unused_0:1; 无符号negate_source:1; 列举mali_dominant_blend优势:1; 枚举mali_nondominant_mode nondominant_mode:1; 未签名的unused_1:1; 无符号negate_dest:1; 枚举mali_dominant_factor relative_factor:3; 无符号complement_dominant:1; } __attribute __((packed));
然后,代替直接填充位域,我们可以使用自动生成的打包宏,通过从程序员那里提取打包详细信息,可以更轻松地使用打包宏。它们不易出错,因为打包连续写入存储器,并且仅在所有数据完成后才写入,避免了细微的错误(位域导致CPU回读GPU存储器),这种错误比连续写入慢了一个数量级,原因是缓存行为。它们还可以更好地处理整数溢出:虽然定义了位域来回绕(非常需要的行为,经常隐藏错误,并且在运行时需要额外的按位和指令),但GenXML禁止溢出。这样,调试版本会验证整数值的范围,尽早发现错误,发布版本可能会完全忽略检查,并且比位域的发布速度更快。总而言之,GenXML对我们的直接好处是显而易见的。
更重要的是,过渡到GenXML的过程使我们可以重新访问驱动程序中使用的每个GPU数据结构,更正上述混合函数描述符中所看到的误解,这在纠正由于对硬件的误解而导致的长期错误方面具有连锁反应。作为一个真实的示例,上述混合函数重做修复了固定函数混合中用于减法和反向减法混合模式的显着错误,避免了不必要的回退到较慢的“混合着色器”路径。确实,GenXML重构需要进行的许多更改都超出了美学方面的考虑,并导致影响我们所有GPU的优化和错误修复。这是我书中很好的重构。
对于Bifrost编译器,我们希望采用类似的方法,自动生成指令编码处理,以说明有关完整Bifrost指令集的新信息。不幸的是,Bifrost打包非常不规则,其中_every_指令可以具有许多编码,而与任何其他指令都没有关系。这使硬件可以执行独特的优化以减小代码大小并提高指令缓存命中率,但会使编译器复杂化,并阻止使用GenXML等现成的工具。
我们的解决方案是使用基于XML的自定义文件格式来表示指令集,该格式旨在解决Bifrost的许多怪癖,并作为机器的基础。该文件列出了每条指令,并带有以下条目:
无 v2 v3 v4
特别注意,与常规体系结构不同,没有指定操作码。相反,确切字段和掩码字段一起指定了指令的特定位必须采用特定值,用作通用操作码。
从指令参考中,我们可以自动生成函数以从编译器的即时表示中打包指令,并从反汇编程序中的打包形式中反汇编指令。注意指令的编码和反汇编是比GenXML处理的简单打包和解压缩更高级的功能。 Bifrost的不规则性要求采取这种方法。尽管如此,我们现在已经拥有完整的Bifrost(体系结构版本7)开源和上游反汇编程序,并且随着我们对编译器的扩展,打包帮助者获得了丰厚的回报。
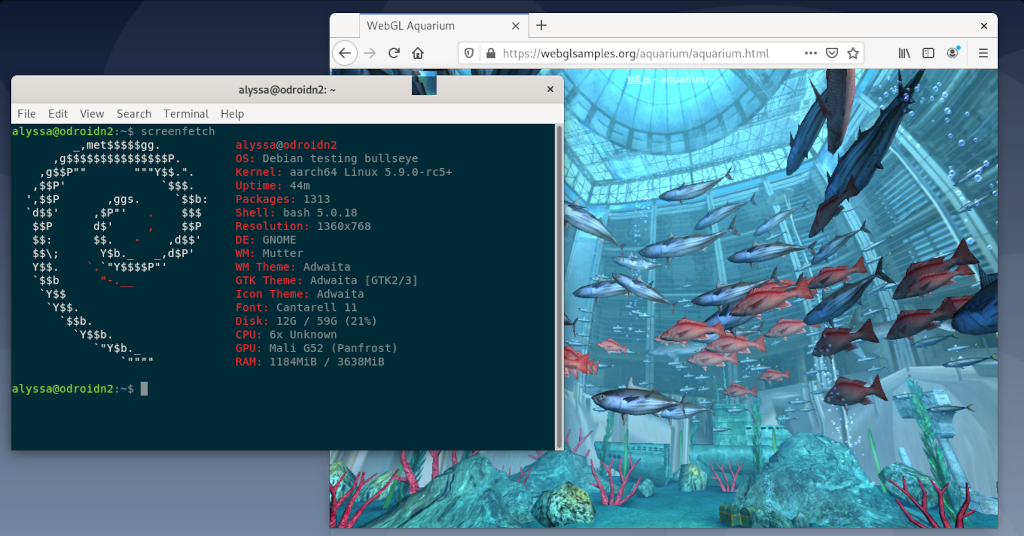
有了新的基础架构,我们就可以快速迭代编译器功能,例如嵌套控制流,复杂的纹理处理,包括Mesa阻击器中使用的OpenGL ES 3.0的texel fetch支持以及基本的寄存器溢出。总体而言,开源Bifrost编译器现在可以处理Glam臭名昭著的渐变渲染着色器,Glamour是X服务器的OpenGL后端。通过这些更改,Bifrost现在可以运行X11桌面(如MATE),以及通过Xwayland在Wayland桌面上运行X应用程序。没关系_why_循环和寄存器溢出用于2D加速。
对于使用Mali T860等GPU的人来说,Panfrost对Midgard的支持也得到了改善。尽管Bifrost编译器是单独的代码库,但通过GenXML进行的改进使Midgard受益。除此之外,在夏天,我们增加了对Arm FrameBuffer压缩(AFBC)的支持,这是对某些工作负载的重大优化。
Mesa的最新版本将自动压缩帧缓冲对象,以节省内存带宽,提高性能并降低功耗。 Panfrost甚至足够聪明,可以在需要时动态地压缩纹理作为AFBC,从而为不直接支持压缩纹理格式(例如ETC)的应用程序提高了纹理处理性能。将来,如果与兼容的显示控制器配对使用,Panfrost将能够压缩帧缓冲区本身,以将其传输到显示器,从而进一步减少高分辨率监视器的带宽。 AFBC的工作是在Midgard GPU上进行的,但将来会扩展到Bifrost。
Midgard编译器还看到了一系列活动,改进了调度程序以优化寄存器压力,支持原子操作和原子计数器,并修复了很多错误。
以上关于Bifrost和GenXML的工作是Collaboran Boris Brezillon和我本人之间的合作。此外,我们的实习生Italo Nicola一直在改进Midgard上对计算着色器的支持,并带头推动了原子操作支持。
我想特别感谢杰出的Icecream95,他添加了包括16位深度缓冲区,桌面样式遮挡计数器,8个同时渲染目标,双源混合和帧缓冲区获取的功能。 Icecream95专注于对Midgard GPU的桌面OpenGL支持,并在此取得了长足的进步,修复和优化了一系列3D游戏,这些游戏从未在像我们这样的嵌入式硬件上运行过。
请在此方框中打勾,以确认您已阅读并接受我们的隐私声明中有关收集/存储和使用您的个人数据的条款:*