使用Vitess在Slack扩展数据存储
从Slack开始,MySQL就被用作所有数据的存储引擎。 Slack在双活配置中运行MySQL服务器。这是关于我们如何将数据存储架构从主动-主动式群集更改为Vitess(用于MySQL的水平扩展系统)的故事。 Vitess是Slack数据存储的现在和将来,对我们来说仍然是一个成功的大故事。从扎实的可伸缩性基础,开发人员的人体工程学以及蓬勃发展的社区中,我们对这项技术的赌注对Slack的持续增长至关重要。
我们从2017年开始迁移到Vitess,现在Vitess可以满足我们整体查询负载的99%。我们预计将在2020年底之前完全迁移。在本文中,我们将讨论选择和采用Vitess时遇到的设计注意事项和技术挑战,并概述我们当前的Vitess用法。
数据存储层中的可用性,性能和可伸缩性对于Slack至关重要。例如,在Slack中发送的每条消息在通过实时Websocket堆栈发送并显示给频道的其他成员之前都会保留下来。这意味着存储访问需要非常快速且非常可靠。在过去的三年中,Vitess除了为消息发送提供了重要的基础之外,还使我们能够灵活地交付具有复杂数据存储需求的新功能,包括Slack Connect和国际数据驻留。如今,我们在高峰期可提供230万个QPS。这些查询中有2M是读操作,300K是写操作。我们的查询延迟中位数是2毫秒,而p99查询延迟是11毫秒。开始
Slack从一个简单的LAMP堆栈开始:Linux,Apache,MySQL和PHP。我们所有的数据都存储在基于MySQL的三个主要数据库集群中:
碎片:这些碎片实际上包含了与使用Slack关联的所有客户数据,例如消息,通道和DM。数据已按工作空间ID进行分区和水平扩展(工作空间是您登录的特定Slack域)。给定工作区的所有数据都存储在同一个分片上,因此应用程序只需要连接到该数据库即可。
元数据集群:元数据集群用作查找表,以将工作空间ID映射到基础分片ID。这意味着要找到工作区中特定Slack域的分片,我们必须首先在此元数据集群中查找记录。
厨房水槽群集:此群集存储了所有其他数据,这些数据没有绑定到特定的工作空间,但这仍然是重要的Slack功能。一些示例包括应用程序目录。任何没有与工作区ID关联的记录的表都将进入此集群。
分片由我们的整体应用程序“ webapp”进行管理和控制。所有数据访问均由webapp进行管理,其中包含逻辑以查找给定工作区的元数据,然后创建与基础数据库分片的连接。
从数据集布局的角度来看,该公司开始使用工作区分割模型。每个数据库碎片都包含工作区的所有数据,每个碎片都包含数千个工作区及其所有数据,包括消息和通道。
从基础结构的角度来看,所有这些集群都是由一个或多个分片组成的,每个分片都配备有位于不同数据中心的至少两个MySQL实例,并使用异步复制相互复制。下图显示了原始数据库体系结构的概述。
这种主动-主动配置具有许多优势,这使我们能够成功扩展服务。这对我们来说很好的一些原因:
高可用性:在正常操作期间,应用程序将始终倾向于基于简单的哈希算法查询两侧之一。当连接到其中一台主机发生故障时,由于分片中的两个节点都可以进行读取和写入,因此应用程序可以重试对另一台主机的请求,而不会对客户产生任何明显影响。
高产品开发速度:使用将给定工作区的所有数据存储在单个数据库主机中的模型设计新功能非常直观,并且可以轻松扩展到新产品功能。
易于调试:Slack的工程师可以在几分钟之内将客户报告连接到数据库主机。这使我们能够快速调试问题。
易于扩展:随着越来越多的团队签约Slack,我们可以简单地为新团队提供更多的数据库碎片,并跟上增长的步伐。但是,缩放模型存在根本限制。如果一个团队及其所有Slack数据都不适合我们最大的碎片怎么办?
随着公司的发展,致力于构建新的Slack功能的产品团队数量也随之增加。我们发现,在尝试将新产品功能融入此非常具体的分片方案时,我们的开发速度大大降低了。这带来了一些挑战:
规模限制:当我们加入越来越多的个人客户时,他们指定的分片达到了可用的最大硬件,并且我们经常达到单个主机可以承受的极限。
停留在一个数据模型上:随着我们的成长,我们推出了新产品,例如Enterprise Grid和Slack Connect,这两个产品都挑战了一个范例,即团队的所有数据都将位于同一数据库分片上。这种体系结构不仅增加了开发这些功能的复杂性,而且在某些情况下还会降低性能。
热点:我们发现我们遇到了一些主要的热点,同时也严重利用了我们大部分数据库资源。随着我们的成长,我们加入了由数千个Slack用户组成的大型团队的越来越多的企业客户。使用此体系结构的不幸结果是,我们无法将这些大客户的负载分散到整个机队中,并且最终在数据库层中出现了一些热点。由于拆分碎片和移动团队具有挑战性,并且随着时间的推移很难预测Slack的使用情况,因此我们过度配置了大多数碎片,从而使长尾巴的利用不足。
工作空间和分片可用性的问题:所有核心功能(例如登录,消息传递和加入渠道)都需要存储团队数据的数据库分片可用。这意味着,当数据库分片出现故障时,每个数据都在该分片上的单个客户也将遭受完全的Slack中断。我们需要一种架构,既可以分散负载以减少热点,又可以隔离不同的工作负载,以使不可用的第二层功能不会潜在地影响诸如消息发送之类的关键功能
操作:这不是标准的MySQL配置。需要我们编写大量的内部工具,才能大规模运行此配置。此外,鉴于在此设置中,我们的拓扑中没有副本,而且应用程序直接路由到数据库主机,因此如果不重新设计路由逻辑,我们将无法安全地使用副本。
该怎么办?在2016年秋天,我们每秒处理数十万个MySQL查询以及生产中的数千个分片MySQL主机。我们的应用程序性能团队经常遇到扩展和性能问题,并且必须针对工作区分片架构的局限性设计解决方法。我们需要一种新的方法来扩展和管理数据库,以便将来使用。
从该项目的早期阶段开始,脑海中浮现出一个问题:我们应该发展还是替代我们的方法?我们需要一种能够提供灵活的分片模型以适应新产品功能并满足我们的规模和运营要求的解决方案。
例如,我们不想将来自给定工作区中每个通道和DM的所有消息都放入同一个分片中,而是希望通过通道的唯一ID对消息数据进行分片。这将使负载分散得更加均匀,因为我们将不再被迫在同一数据库分片上为我们最大的客户提供所有消息数据。
我们仍然强烈希望继续使用在我们自己的云服务器上运行的MySQL。当时,应用程序中有成千上万个不同的查询,其中一些使用MySQL特定的结构。同时,我们针对部署,数据持久性,备份,数据仓库ETL,法规遵从性等等建立了多年的运营实践,所有这些都是针对MySQL编写的。
这意味着离开关系范式(甚至是从MySQL移开)将带来更大的破坏性变化,这意味着我们几乎排除了NoSQL数据存储区(如DynamoDB或Cassandra)以及NewSQL(如Spanner或CockroachDB)。
此外,历史背景对于理解如何制定决策始终很重要。就采用新技术而言,Slack通常是保守的,尤其是对于我们产品栈中关键任务的部分。当时,我们希望继续将我们的大部分工程精力投入到产品功能的交付中,因此小型数据存储和基础架构团队非常重视具有很少活动部件的简单解决方案。
一种自然的前进方式可能是在我们的应用程序中构建此新的灵活分片模型。由于我们的应用程序已经涉及数据库分片路由,因此我们可以满足新的要求,例如按通道ID在该层中分片。考虑了该选项,并编写了一些原型来更全面地探索这一思想。显然,应用程序逻辑与数据存储方式之间已经存在相当多的耦合。同样很明显,解决这个问题并建立新的解决方案将非常耗时。
例如,诸如获取通道中的消息数之类的事情与关于通道所在团队的假设紧密相关,并且在代码库中的许多地方都通过显式检查多个分片来解决具有多个工作区的组织的假设。
最重要的是,在应用程序中建立分片意识并不能解决我们的任何操作问题,也无法使我们更有效地使用只读副本。尽管它可以解决当前的扩展问题,但从长远来看,这种方法似乎可以应对同样的挑战。例如,如果一个团队的分片在写入路径上出奇地热,那么对其进行水平扩展就不是一件容易的事。
大约在这个时候,我们意识到了Vitess项目。自从其核心Vites提供了用于MySQL的水平扩展的数据库集群系统以来,这似乎是一项很有前途的技术。
在较高的级别上,Vitess勾选了我们的应用程序和操作要求的所有框。
MySQL Core:Vitess建立在MySQL之上,因此利用了多年来使用MySQL作为实际数据存储和复制引擎的可靠性,开发人员理解和信心。
可伸缩性:Vitess将许多重要的MySQL功能与NoSQL数据库的可伸缩性结合在一起。它的内置分片功能使您可以灵活地分片和扩展数据库,而无需向应用程序中添加逻辑。
可操作性:Vitess自动处理诸如主要故障转移和备份之类的功能。它使用锁定服务器来跟踪和管理服务器,使您的应用程序对数据库拓扑一无所知。 Vitess会跟踪有关集群配置的所有元数据,以便集群视图始终是最新的,并且对于不同的客户端是一致的。
可扩展性:Vitess是使用golang在开放源代码中100%构建的,它具有广泛的测试范围以及一个繁荣的开放开发者社区。我们有信心,我们将能够根据需要进行更改以满足Slack的要求(我们做到了!)。
我们决定构建一个原型,以证明我们可以将数据从传统架构迁移到Vitess,并且Vitess将兑现其承诺。当然,采用Slack规模的新数据存储并非易事。它需要大量的精力来建立所有新的基础架构。
我们的目标是为生产中的一个小功能构建一个工作中的Vitess端到端用例:将RSS feed集成到Slack频道中。它要求我们对许多操作流程进行重新设计,以进行部署部署,服务发现,备份/还原,拓扑管理,凭据等。我们还需要开发新的应用程序集成点,以将查询路由到Vitess,这是一个通用的回填系统,用于在从应用程序执行两次写入操作时克隆现有表,还需要一个并行的双读取差异系统,因此我们可以确保使用Vitess技术表具有与我们的旧数据库相同的语义。但是,这是值得的:应用程序使用新系统可以正确执行,性能要好得多,并且群集的操作和扩展也更简单。同样重要的是,Vitess兑现了弹性和可靠性的承诺。最初的迁移使我们有信心继续进行该项目的投资。
同时,重要的是要指出,在这个初始原型期间并持续了数年,我们已经确定了Vitess中的不足之处,以至于无法满足某些特定于Slack的需求。由于该技术在解决我们面临的核心挑战方面显示出了希望,因此我们认为值得我们在工程上进行投资以补充缺少的功能。
弥补完全MySQL查询兼容性方面的一些空白。 [a],[b],[c],[d],[e]。
如今,可以肯定地说开源社区中的某些人是我们团队的一部分。自采用Vitess以来,Slack已成为并将继续成为开源项目的最大贡献者之一。
现在,距这次迁移仅三年时间,已经有99%的Slack MySQL流量迁移到了Vitess。我们有望在未来两个月内完成剩余的1%。我们一直想分享这个故事很久了,但是我们一直等到我们完全有信心这个项目成功了。
这是一张图表,显示了过去几年的迁移进度和一些里程碑:
在这三年的迁移中,还有许多其他故事要讲。从0%提高到99%的采用率也意味着从0 QPS到我们今天服务的2.3 M QPS。选择适当的分片键,对我们现有的应用程序进行改造以使其能够与Vitess一起正常工作,并且有必要进行大规模操作Vitess的更改,这是我们学习新知识的每个步骤。在Slack的一名高级工程师Maude Lemaire撰写的Scale Rescaleing案例研究中,我们分解了一个表的特定迁移,该表占我们整体查询负载的20%。我们还计划在未来的博客文章中介绍有关迁移策略和技术的更改,以移动整个分片而不是表格。
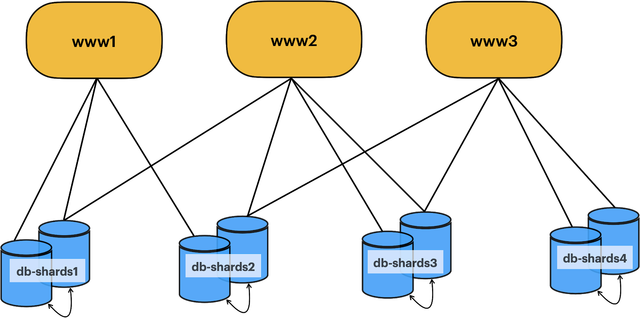
今天,我们在全球不同地理区域中运行带有多个键空间的多个Vitess集群。我们的主要Web应用程序整体以及其他服务都使用Vitess。每个键空间都是数据的逻辑集合,可以按相同的因素(用户,团队和渠道数)大致扩展。与仅按团队分片以及对团队热点说再见! Vitess提供给我们的灵活分片使我们能够扩展和扩展Slack。
2020年3月,随着我们的首席执行官Stewart Butterfield发推文,随着COVID-19大流行的现实席卷美国,工作/学校搬离办公室并分布起来,我们看到了Slack的使用空前增加。在数据存储方面,仅一周时间,我们就发现查询率提高了50%。为此,我们使用Vites的拆分工作流程水平扩展了我们最繁忙的键空间之一。如果不进行分片和迁移到Vitess,我们将根本无法为最大的客户扩展规模,从而导致停机。当Slack的产品团队开始编写新服务时,他们能够使用与Webapp相同的存储技术。选择Vitess而不是在我们的Webapp整体中建立新的分片层,使我们能够将相同的技术用于Slack的所有新服务。 Vitess还是我们的国际数据驻留产品的存储层,为此,我们在总共六个区域中运行Vitess群集。在这里使用Vitess有助于在创纪录的时间内发布此功能。它使我们的产品工程团队能够专注于核心业务逻辑,而数据的实际区域局部性则是从他们的努力中抽象出来的。当我们选择Vitess时,我们没想到会写新服务或交付多地区产品,但是由于Vitess的适用性以及我们过去几年对它的投资,我们已经能够利用相同的这些新产品领域的存储技术。
现在迁移已完成,我们期待利用Vitess的更多功能。我们已经在VReplication上进行了投资,该功能使您可以加入MySQL复制以实现数据的不同视图。
下图显示了我们在Slack的Vitess部署的简化版本。
这种成功仍然引出一个问题:这是正确的选择吗?在西班牙语中,有一句话说:“ Como anillo al dedo”。通常在解决方案非常精确时使用。我们认为,即使有了事后的见识,Vitess仍然是我们的正确解决方案。这并不意味着如果Vitess不存在,我们就不会想出如何扩展数据存储区。相反,根据我们的要求,我们本可以找到与Vitess非常相似的解决方案。在某种程度上,这个故事不仅涉及Slack如何扩展其数据存储。这也是一个讲述我们行业中合作重要性的故事。
我们想向所有为这一旅程做出贡献的人们大声疾呼:亚历山大·达拉尔,阿米特·科蒂安,安德鲁·梅森,安朱·班萨尔,布莱恩·拉莫斯,克里斯·沙利文,达伦·希格拉夫,迪帕克·驳船,迪皮·西吉雷迪,周慧清,乔什·瓦纳 ,雷·约翰逊(Leigh Johnson),曼努埃尔·方丹(Manuel Fontan),玛纳西·林巴希亚(Manasi Limbachiya),马尔科姆·阿金耶(Malcolm Akinje),麦琳娜·塔拉维拉(Mikena Demmer),摩根·琼斯(Morgan Demmer),尼尔·哈金斯(Neil Harkins),保罗·奥康纳(Paul O'Connor),保罗·塔克菲尔德(Paul Tuckfield),雷南·兰格尔(Renan Rangel),里卡多·洛伦佐(Ricardo Lorenzo),理查德·贝利(Richard Bailey),瑞安·帕克(Ryan Park),莎拉·比尔(Sara Bee),Serry Park ,Sugu Sougoumarane,V。Brennan和我们可能忘记的所有其他人。