不讲毛利语的新西兰人有一个毛利语原始词汇
Warning: Can only detect less than 5000 characters
有人批评统计学习的研究缺乏生态有效性,因为人工语言不能完全解决自然语言的复杂性和噪音,实验室环境不像自然学习环境22,23。在我们的研究中,我们没有提供人工语言在学习环境中,我们调查了不说但在日常生活中已经接触过这种语言的成年人中对一种真实语言的了解。具体来说,我们调查了成年新西兰人中毛利人的知识。
毛利人是新西兰的土著语言。自从欧洲人到达后,该语言就受到了威胁,尽管自1987年成为官方语言以来,政府已提供资金并制定了策略来促进和振兴毛利人。大多数新西兰人会定期以书面和口头形式接触毛利人24。例如,所有小学生都会接触到毛利人的歌曲,指示和颜色词。一些单词已成为新西兰英语的一部分(例如:whānau“ family”; kai“ food”),并且所有地名中大约有一半是毛利人。新西兰人也接触到毛利人的问候语,例如用于召开会议和正式活动的讲话。
尽管存在这种情况,但非毛利语使用者(NMS)的活跃毛利语词汇量仍然很小:多项选择定义任务建议平均只有25到70-80个单词的语义知识。NMS的活跃毛利语小词汇量及其接触毛利人为研究通过环境暴露获得的成人原始词典提供了理想的环境。
由于毛利人的音素存量很小,只有十个辅音和五个元音(每个元音有短和长的对应关系,按字元排列在字面上就可以区分),因此符号和声音之间存在透明的关联。因此,书面刺激提供了一个合适的代理,通过它我们可以研究音韵学知识。
为了探究NMS的潜在原始词典,我们进行了在线单词识别任务,其中包含频率,音位概率和音素长度(范围从3到12个音素)不同的毛利人单词,以及跨类似范围的类似毛利人的非单词音符概率的长度相同且长度分布相同。删除无法使用的参与者后,可以从85个成人NMS中获取数据进行分析。大多数参与者自我报告说,他们对毛利人有一些非常基础的知识,并且对毛利人的持续接触水平很低。
全套刺激材料包括1000个毛利人单词和1000个类似毛利人的非单词。单词和非单词都跨越一系列音韵学的概率分数,以使我们能够评估参与者基于音韵知识的评分的程度,尽管真实单词的分数往往比非单词的分数高。单词跨越五个频点,范围从高频率单词到相对罕见的单词,并且每个单词与具有相似音韵分数(即在固定范围内)的非单词配对,该非单词被分配给相同的频点用于比较的目的。更多详细信息,请参见《详细材料和方法补充》;有关单词及其成对的非单词的属性的详细信息,请参见“第节”。 2.1,有关音位控制分数的详细信息,请参见Sect。 4.2。
每个参与者以随机顺序响应这些单词的不同子集,而不用对真实单词和非单词进行配对:300个刺激,其中包含30对单词和非单词,它们是从五个频点中随机选择的。要求参与者评估他们对所看到的每个项目是一个毛利单词的自信程度,评分范围从1(“确信它不是毛利单词”)到5(“确信它不是毛利单词”)。 。实验1和2中的所有实验方案均已获得坎特伯雷大学人类伦理委员会的批准。所有实验均按照相关指南和法规进行,并获得所有参与者的知情同意。
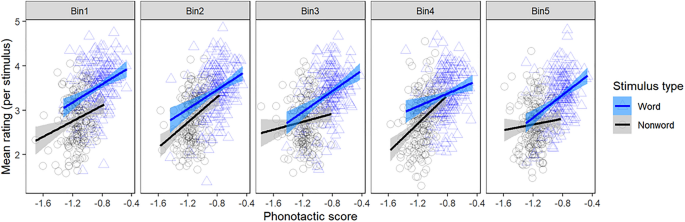
如图1所示,NMS平均对每个刺激给毛利人单词的评级要高于类似毛利人的非单词,如图1所示。这种模式得到了有序混合效应回归模型中所有五个频点的显着单词/非单词区分的支持,即使分析仅限于在音位上更紧密匹配的单词和非单词,也是如此(请参见《详细分析和结果补充》第2.4-2.5节)。有迹象表明,对于频繁出现的单词来说,这种区别最为明显,正如Bin1中比其他bin中的间距更大(图1)所证明的那样,但即使对于频率非常低的单词也很明显。换句话说,成年的非毛利语使用者即使在频率很低的情况下也可以成功地识别出许多真实的毛利人单词。
非毛利语使用者对每个刺激频率的每个刺激的平均单词置信度评分,以及它们与音律得分的关系。 Bin1包含最频繁的实词,而Bin5包含最不频繁的实词,以及成对的非单词。点表示每个bin中每个真实单词(蓝色)和非单词(黑色)的平均评分,直线显示与音位得分的相关性。在所有垃圾箱中,与非单词相比,真实单词获得更高的评级,并且具有更高的音符得分的项目获得更高的评级。
在执行此任务时,参与者显示出利用了音法知识的证据:物品的平均等级随着其音法概率而显着提高。但是,重要的是要注意,参加者在此任务上的成功无法通过了解毛利人的光复律概率来完全解释。除了音符规则概率的影响之外,有证据表明,参与者实际上知道哪些项目是真实的单词,哪些是非单词,如上述图1中单词/非单词区分的显着主要效果所反映的。但是,他们并不确定在这方面的知识。尽管单词和非单词的评级有很大不同,但它们在数字上彼此接近,并且参与者通常不会以“ 5:确信这是一个毛利单词”来对真实单词进行评级。
实验1的结果表明,环境暴露于自然语言会导致成年人在没有任何主动学习的情况下发展出原始词汇。现在,我们调查他们可以在此原始词典上进行概括以创建毛利人的音韵学知识的程度。当出现非单词的程度与毛利人的单词相似的非单词时,不讲毛利语的新西兰人是否能够评价类似毛利人的单词的外观?而且,如果是这样,他们的评分与流利的毛利人的评分相比如何?
在实验2中,我们进行了一系列类似于毛利人的非单词的在线格式评定任务。在该实验的每个试验中,参与者使用从1(“非毛利人样非单词”)到5(“高度毛利人”)的等级来评定类毛利人的非单词作为真实毛利人单词的质量。 -like non-word')。每个参与者对单个音素长度(范围从3到8)的非单词进行评分。每个长度有240或320个刺激,总共总共有1760个不同的非单词。有关刺激的更多详细信息,请参见《详细材料和方法补遗》第6节。 2.2。
实验2包括三组成年参与者:不讲毛利语的新西兰人(NMS; N = 113),流利的讲毛利语的新西兰人(MS; N = 40)和不讲毛利语的美国人(US; N = 94) 。尽管数据集保留了12名出生于新西兰以外但已在新西兰居住至少10年的NMS参与者,但大多数NMS参与者都自称说新西兰英语为第一语言。熟练的讲毛利语的人在没有完整的词典和反音法知识的情况下为任务执行提供了基准,而在美国的讲者的语言却没有词典和很少的音法知识。
我们通过评估对音素三字母组合计算的音符概率的敏感性来对毛利人的音符知识进行建模(请参见《详细材料和方法补充》第4.2节)。我们希望MS参与者对拟音符概率表现出高度的敏感性,而US参与者则表现出较低的敏感性。我们预测NMS对音符概率具有中等程度的敏感度,反映了音符知识的中等程度。
Warning: Can only detect less than 5000 characters
......