起始网看不到什么
诸如Inception Net之类的深度学习视觉模型在图像识别方面实现了最先进的性能。但是,我很好奇这些模型何时无法正常运行。我在大量自然图像上测试了Inception Net,这是模型无法很好预测的一系列结果。注意:我只提供了示例,其中正确的类是1,000个有效ImageNet类之一。
自己尝试:每个示例都带有指向模型演示的链接(使用Gradio构建),您可以在其中直接从浏览器直接尝试图像。
倒车时,Inception Net根本无法识别汽车类别
尽管Inception Net可以识别许多切成薄片的水果,但确信切成薄片的苹果实际上是黄瓜或其他水果。
Inception Net可以很好地检测出西式礼服的新郎,但当他们穿着巴基斯坦/印度服装时却无法识别
“如果不是圆形,就不是气球” – Inception Net
诚然,ImageNet是在COVID-19之前被收集的,当时它们并不常见。但是,奇怪的是,即使口罩和防毒面具是有效的类别,也无法预测常规的手术口罩。
通常,Inception Net无法对图像的卡通版本进行分类。以我的经验,卡通狮子很难对其正确分类。
好像Inception Net对Roomba吸尘器一无所知,因为它始终将其误识别为另一个小工具。
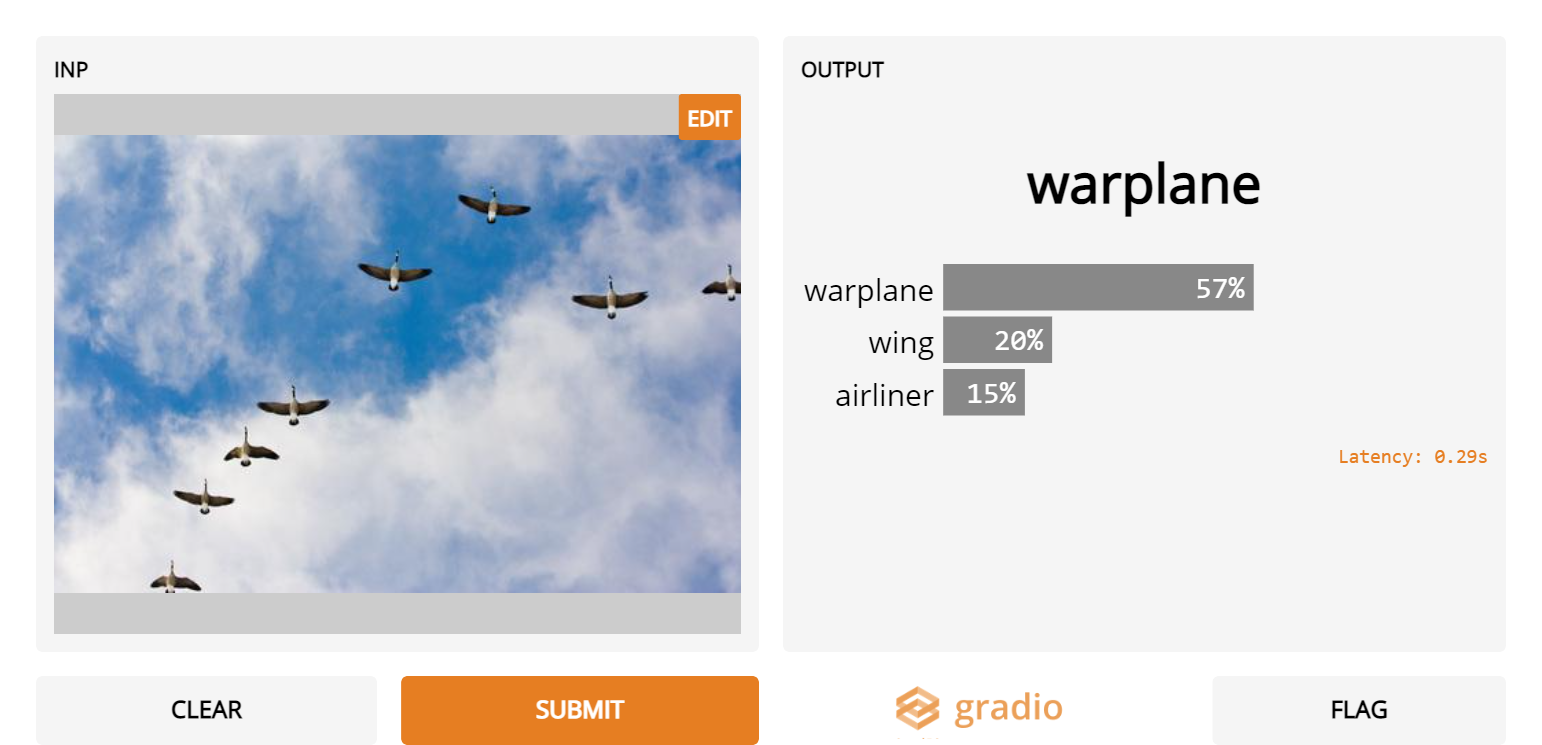
Inception Net不会擅长于威胁检测,因为它会将这些无害的鹅误认为是战机!
因此,我们找到了Inception Net失败的一些示例……那又如何呢?好吧,像Inception Net这样的基于深度学习的图像分类器被认为是高度准确的,以至于许多公司将它们作为旨在供公众使用的API [1、2、3]发布。该发行版很少附有模型失效点的描述,因此用户并不真正知道何时期望模型可靠,何时不可靠。
通过简单地通过Web界面对模型进行实验,我发现了Inception Net的几个盲点:例如,处于异常位置的物品(#1)或来自非西方文化的物品(#3)甚至是非标准艺术品的图像样式(#6)。 Gradio库还使我可以轻松地尝试自然的图像操作(例如旋转,裁剪或直接通过Web界面在图像上添加噪点),从而更容易发现模型问题。这些故障点应进行彻底调查和记录,以便用户知道何时信任已部署的图像识别模型。
使用我可以访问的图像来尝试Inception Net真的很容易(我只是在Google Image上搜索过,或者在计算机上尝试过图像)。自己尝试该模型(http://www.gradio.app/hub/abidlabs/inception),并在注释中让大家知道您发现了哪些其他盲点!