实践中的2次方选择权
访问模式决定了应如何存储数据。经常写入的数据应采用面向行的格式,而经常查询的数据应采用面向列的格式。
Mixpanel的内部数据库Arb支持实时事件提取和对所有历史记录的快速分析查询。存储节点从队列中读取数据,然后使用面向行的预写日志(WAL)将其写入磁盘。
我们运行一个称为压缩器的服务,该服务将数据从行格式转换为列格式。此服务在Google Kubernetes Engine(GKE)上的自动缩放节点池中运行。当存储节点具有一定大小或使用期限的行文件时,它会向随机压缩器节点发送请求以对其进行压缩。压缩程序将返回生成的列文件的句柄或错误。如果所有压缩程序都处于繁忙状态,则它们会减轻负载,并且存储节点会重做一些尝试。
尽管压缩程序在查询的关键路径之外运行,但它必须可靠且高效,因为Arb中的所有新数据每天都会经过它。考虑到必须要做的工作,压缩服务在计算上非常昂贵。
压缩器成本在2019年下半年稳步增长,部分原因是我们的客户不断增长,部分原因是用于数据转换的新用例。
更糟糕的是,压实机未能在正确的时间自动缩放以吸收负载峰值。这导致工程师在负载高或服务范围内的事件期间手动将自动定标器的最小副本数设置为高数量。这既浪费了我们的工程师时间,又使我们花在了浪费资源的实例上。
我们首先看一下利用率,对于计算范围自动缩放服务,我们希望达到80-90%。由于Kubernetes的Horizontal Pod Autoscaler(HPA)的工作方式,因此这种假设似乎是合理的。您可以使用目标服务(压缩器)和该服务的目标指标(平均CPU利用率为90%)对其进行配置。如果CPU利用率超出目标某个阈值,它将调度更多的Pod,如果利用率较低,则反之亦然。内置一些迟滞以避免持续的抖动。
但是,在我们的情况下,平均CPU利用率约为40%。平均值可以隐藏偏斜,因此我们绘制了利用率中位数和第90个百分位数。这表明一半的压实机几乎没有工作,而前10%的压实机已用尽!聚合利用率很低,因为自动缩放算法使用平均值而不是百分位数来做出缩放决策:
压缩器每分钟收到1000个请求,因此通过大量定律,这些请求应在我们拥有的30-40个节点之间达到平衡。
事实证明,即使您随机分配请求,但是当单个加载项的分配非常不均匀时,也会发生偏差。在我们的情况下发生这种情况是因为我们拥有广泛的客户,从每天有数千个事件的初创公司到每天有数十亿个事件的大型公司。这种功率定律,最大的用户比最小的用户大得多,因此简单的平均值就没那么有用了。
一旦我们确定歪斜是问题所在,我们就考虑了一些复杂程度各异的解决方案:
(高)使用队列:在我们的存储节点(客户端)和压缩程序之间插入一个队列。这将从当前的推模型切换到异步拉模型,在这种情况下,压缩器仅在有容量时才起作用。虽然这可以实现最佳利用,但它需要对基础架构进行更改,添加队列组件,并需要跟踪正在进行的压缩工作。
(中)使用代理:在存储节点和压缩程序之间插入负载平衡服务。该服务可以跟踪所有压缩程序的负载,并将传入的请求转发到负载最小的压缩程序。这维持了我们当前基于推的架构,但是在两者之间添加了代理。我们考虑了这一点,但决定用更简单的方法验证我们的假设。
2种随机选择(P2C)的(低)功效:这里的想法很简单。他们不是随机选择1个压缩器,而是随机选择2个压缩器。它们然后向每个压缩器询问其当前负载,并将请求发送到两个负载较小的负载。从理论上讲,这属于上述两个解决方案的恒定因素。我们还编写了一个快速的Python模拟程序,以确认我们对此工作原理的直觉。
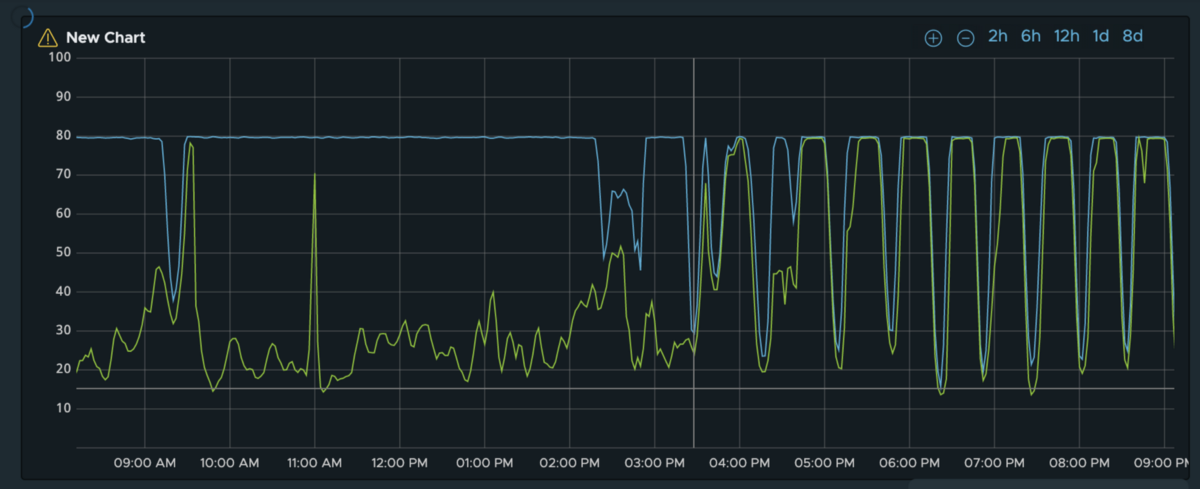
我们从P2C方法开始,因为我们可以在不到一天的时间内实现它。我们并没有感到失望。这是在实施2的幂平衡之前和之后,我们的压缩节点上的中位数负载和第90个百分点负载。
通过对平衡的上述改进以及其他一些较小的调整,我们可以可靠地使用平均利用率进行自动缩放,并看到压实机可预测地对负载峰值做出反应。反过来,由于不再需要减轻负载,因此在稳定状态下,我们的平均利用率提高到了约90%,错误率降低到了接近0。
鉴于我们对系统行为的信心日益增强,我们决定采用可抢占式VM采取更高级的自动扩展策略。
可抢占式VM是Google提供的低成本VM,非常适合无状态的后台工作负载。虽然价格是普通VM的1/3,但价格却是可靠的:Google可以在容量有限的情况下任意终止可抢占的VM。
以前,我们仅将可抢占式VM用于Compacter。在喜人的情况下,这很好,但是当Google终止它们时却是灾难性的。因此,我们决定完全切换到常规VM,这提高了可靠性,但价格更高。
但是,这一次,我们希望两全其美:如果在常见情况下可以获得可抢占式VM的成本收益,而在最坏情况下获得常规VM的可靠性收益,该怎么办?
原来,我们可以!在进行了一些研究并找到了这篇出色的文章之后,我们对节点池进行了配置,以使Kubernetes会自动尝试使用便宜的VM(如果可用),然后转而使用更昂贵的VM。
我们在2020年1月的两周内交付了这两种优化,这使我们的紧凑型服务成本降低了近70%。重要的是,这些方法经受了时间的考验,而团队的后续行动却很少。
我们在学习过程中吸取了一些教训,希望对团队在云中构建大规模服务有用:
自动缩放很难正确!它需要一个高信号目标指标,可以对偏斜具有弹性。在某些情况下,您可以将自动伸缩服务放在队列前面,并根据队列长度自动伸缩。但是,当呼叫者阻塞等待结果或错误时,引入队列会给系统增加实质性的复杂性。
怀疑平均值。始终查看百分位数或完整分布,以更好地了解您的负载。由于功率法的原因,可能有一些请求构成了整个负载的重要部分。
P2C是解决偏斜的一种非常简单的技巧。在随后的几个月中,我们将其应用于Mixpanel的其他一些计算密集型自动缩放服务,并取得了类似的成功。也就是说,这并非没有取舍。使用P2C之前,请注意以下两个警告:
它要求所有客户合作。如果您的服务只有一个要控制的客户端,则可以确保该客户端首先检查负载并始终将请求发送到负载较小的节点。但是,如果您有很多客户端,或者您无法控制这些客户端,则无法使用。如果哪怕一个客户都不遵守2协议的功能,那么所有的赌注都将偏斜!就我们而言,现在Compacter的内部客户数量很少。我们创建了一个客户端库,其中封装了所有客户端都使用的P2C逻辑和其他便利。如果客户真正是外部客户,最好使用现成的代理/负载平衡器来路由请求(该请求本身可能在后台使用P2C!)。
它为每个请求引入了两个额外的往返行程,以检查2个随机节点上的负载。当实际请求比较繁重(例如在我们的案例中)并且客户端-服务器的延迟可以忽略不计(例如,单个GCP区域中的内部服务)时,此开销就可以了。当请求本身很小或客户端与服务器之间的往返延迟很高时,这不是很好。
如果您对解决基础设施难题的创新解决方案感兴趣,我们正在招聘! 通过我们的职业页面与我们联系。