简而言之,Linux功能
功能的使用越来越多,这主要归功于SystemD,Docker和Kubernetes等编排器。但是我认为文档有点难掌握,并且发现功能实现的某些部分令人困惑,因此我决定将我的当前知识浓缩为一篇较短的文章。
有关功能的最重要参考是最新的手册页功能(7)。但这并没有提供易于阅读的介绍。
普通用户的权限非常有限,而“ root”用户的权限非常强大。但是在“ root”下运行的进程通常不需要完整的root功能。
为了帮助降低“ root”用户的权限,POSIX功能提供了一种方法来限制进程及其子级可以执行的特权系统操作组。他们基本上将完整的“ root”特权划分为一组不同的特权。在1997年撤消的POSIX 1003.1e草案中描述了功能的概念。
每个Linux进程(任务)具有五个具有保持能力的64位数字(组)(在Linux 2.6.25之前为32位),可以通过读取/ proc /< pid> / status进行检查。
这些数字(此处显示为十六进制数字)充当对一组功能进行编码的位图。全名是:
边界集–在Linux 2.6.25之前,边界集是所有线程共享的系统范围的属性,可能意味着描述无法扩展功能的集合。当前,它是按任务设置的。它是execve转换逻辑的一部分(稍后会介绍),并且还限制了使用capset()将进程可以设置为其可继承集的内容。
环境集(自Linux 4.3起)–已添加,可轻松为非0用户提供功能,而无需使用setuid或文件功能(稍后会介绍)。
如果任务要求执行特权操作(例如,对端口<1024进行绑定),则内核会检查有效边界集,以查看是否设置了CAP_NET_BIND_SERVICE。如果是,它将继续。否则,它将拒绝使用EPERM进行的操作(不允许进行操作)。内核源中的这些CAP_定义是按顺序编号的,因此CAP_NET_BIND_SERVICE为10意味着位1 << 10 = 0x400(在我之前的示例中为“ 4”十六进制数字)。
您可以在最新的手册页功能(7)中找到当前定义功能的完整人类可读列表(此处仅供参考)。
此外,还有一个库libcap使功能管理和检查更加容易。除了库API外,该软件包还包括capsh实用程序,该实用程序除其他功能外,还可以打印其功能。
#capsh --printCurrent:= cap_setgid,cap_setuid,cap_net_bind_service + eipBounding set = cap_setgid,cap_setuid,cap_net_bind_serviceAmbient set = Securebits:00 / 0x0 / 1&#39; b0 secure-noroot:no(unlocked)secure-no-suid-fixup:否(未锁定)安全保持上限:否(未锁定)安全无环境提升:否(未锁定)uid = 0(root)gid = 0(root)groups = 0(root),1(bin), 2(守护程序),3(sys),4(adm),6(磁盘),10(滚轮),11(软盘),20(拨号),26(磁带),27(视频)
当前-以cap_to_text(3)格式显示capsh进程的有效,可继承和允许的功能。同样,它以cap_to_text格式显示,基本上将功能列为功能[,capability ...] +(e | i | p)组,其中“ e”表示有效,“ i”可继承,“ p”被允许。如您所料(cap_setgid + eip,cap_setuid + eip),列表之间没有以“”分隔。 “,”将功能分成一个+…(动作)组。然后,将实际的操作组列表用空格分隔。因此,具有两个操作组的另一个示例是“ = cap_sys_chroot + ep cap_net_bind_service + eip”。而且,这两个操作组“ = cap_net_bind_service + e cap_net_bind_service + ip”的编码含义与单个“ cap_net_bind_service + eip”相同。
边界集/环境集。为了使事情更加混乱,这两行仅包含这些集合中的一系列功能,并以空格分隔。这里不使用cap_to_text格式,因为它没有一起列出允许的,有效的,可继承的集,而仅列出了一个(边界/环境)集。
Securebits:以十进制/十六进制/ fancy-verilog-convention-for-binary字符串的形式显示任务的securebits整数(是的,每个人都希望在这里看到它,并且用“ b完全清楚”,因为每个sysadmin都编写自己的FPGA和ASIC)。安全位的状态如下。实际位在securebits.h中定义为SECBIT_ *,并在capabilities(7)中进行了描述。
该工具缺少一个重要状态,即“ NoNewPrivs”,也可以通过检查/ proc /&lt; pid&gt; /状态来查看。仅在prctl(2)中对此进行了描述,即使它与文件功能结合使用时会直接影响功能(稍后会介绍)。 NoNewPrivs被描述为“ no_new_privs设置为1,execve(2)承诺不授予特权以执行没有execve(2)调用无法完成的任何操作(例如,呈现set-user-ID和set-组ID模式位,文件功能不起作用)。设置后,就不能取消设置此no_new_privs属性。该属性的设置由fork(2)和clone(2)创建的子代继承,并保留在execve(2)中。”这是在pod的securityContext中将allowPrivilegeEscalation设置为false时Kubernetes设置为1的标志。
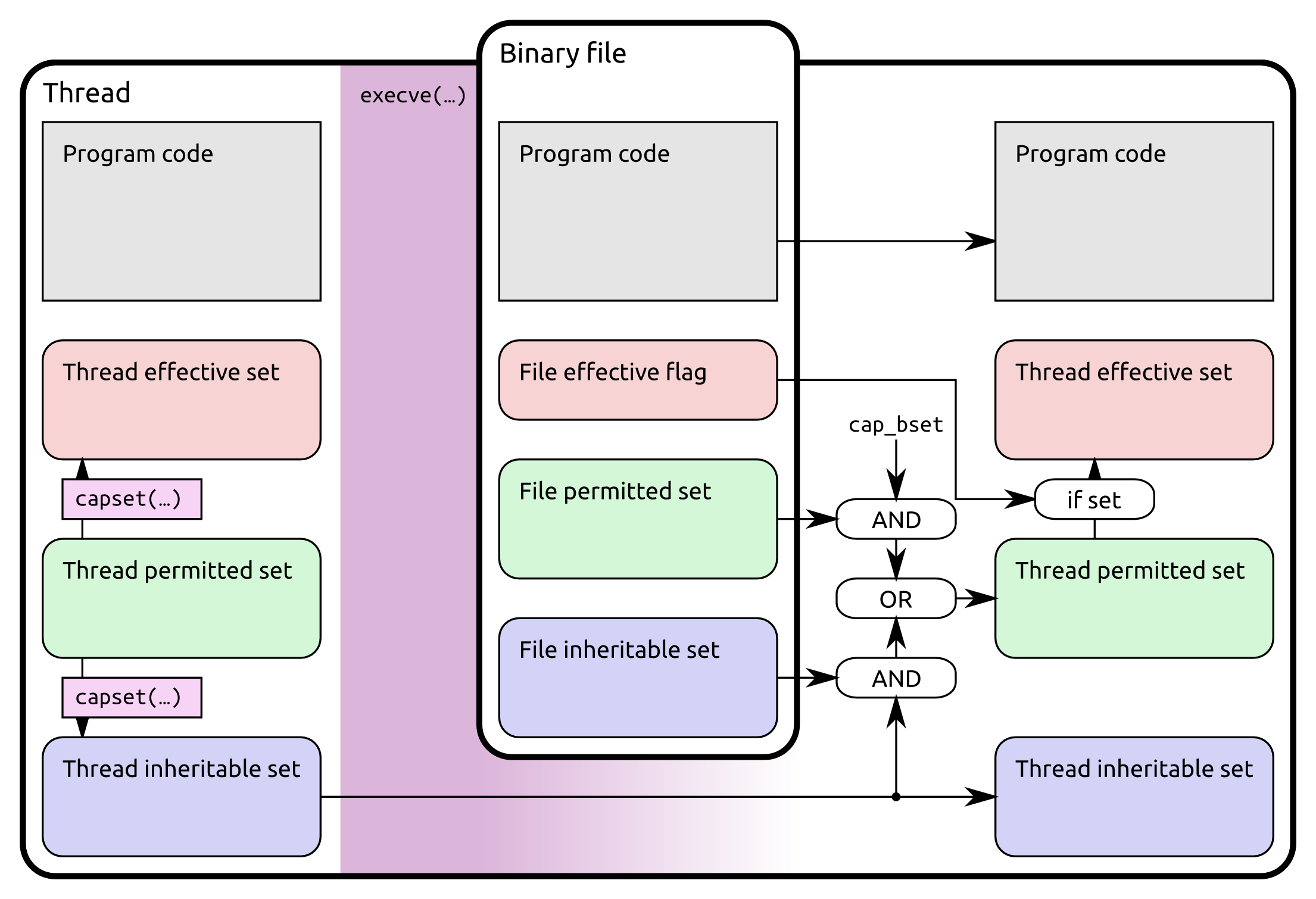
当一个进程通过执行execve(2)启动一个新进程时,将使用capabilities(7)中提到的公式将能力转换为子代:
P&#39;(环境)=(文件具有特权)? 0:P(环境)P&#39;(允许)=(P(可继承)&F(可继承))| (F(允许)&P(边界))| P&(环境)P&(有效)= F(有效) P&#39;(允许):P&#39;(环境)P&#39;(可继承)= P(可继承)[即不变] P&#39;(边界)= P(可边界)[即不变] :P()表示在execve(2)之前的线程能力集的值P&#39;()表示在execve(2)之后的线程能力集的值F()表示文件能力的集
这些规则描述了对环境/许可/有效/可继承/边界集中的每一位所采取的操作。它使用标准C语法(&amp;用于逻辑AND,| |用于逻辑OR)。 P’是子进程,P是当前调用execve(2)的进程。 F就是被执行文件的所谓“文件功能”。
另外,进程可以根据以下规则随时使用libpcap以编程方式更改其可继承集,允许集和有效集:
除非调用者具有CAP_SETPCAP,否则新的可继承集必须是P(heritable)&amp; P的子集。 P(允许)
(从Linux 2.6.25开始)新的可继承集必须是P(可继承)&amp;的子集。 P(有界)
有时,功能集减少的用户需要运行需要更多功能的二进制文件。以前,这是通过setuid二进制文件(chmod + s ./executable)实现的。如果这样的二进制文件由root拥有,则在由任何用户执行时都将为其分配完全root特权。
这给了二进制文件太多的特权,因此POSIX功能实现了一个称为“文件功能”的概念。它们存储为名为“ security.capability”的扩展文件属性,因此您需要功能强大的文件系统(ext *,XFS,Raiserfs,Brtfs,overlay2等)。要使进程写入该属性,需要CAP_SETFCAP功能(在进程的有效集中)。
$ getfattr -m--d`ping'#文件:usr / bin / pingsecurity.capability = 0sAQAAAgAgAAAAAAAAAAAAAAAAAAAA = $ getcap`which ping` / usr / bin / ping = cap_net_raw + ep
当然,生活并不简单,功能的实现也不是那么简单,capabilities(7)手册页中描述了几种特殊情况。可能最重要的是:
如果设置了NoNewPrivs或安装了文件系统nosuid或正在跟踪调用execve的进程,则会忽略setuid文件位和文件功能。使用no_file_caps引导内核时,文件功能也将被忽略。
Capability-dumb二进制文件是将setuid转换为文件功能的二进制文件,而无需更改其代码。此类二进制文件通常通过在其上设置+ ep功能来转换,例如“ setcap cap_net_bind_service + ep ./binary”。重要的部分是有效的“ e”。执行后,此功能将同时添加到允许的和有效的,以便可执行文件可以使用特权操作。相反,使用libpcap或类似功能的功能智能二进制文件可以在任何时候使用cap_set_proc(3)(或capset)来设置“有效”或“可继承”位,只要该功能已在“允许”设置中即可。因此,“ setcap cap_net_bind_service + p ./binary”对于功能智能的二进制文件就足够了,因为它可以在调用特权操作之前自行设置有效位。参见我的示例代码。
setuid-root二进制文件继续工作,当由非root用户运行时,会赋予root所有特权。除非设置了文件功能,否则将仅授予这些功能。尽管没有任何功能,也可以使用空文件功能集创建setuid二进制文件,使其执行为0。在某些特殊情况下,root用户运行setuid-root二进制文件,并且设置了各种安全位(请咨询man)。
边界集会屏蔽文件允许的功能,但不会屏蔽可继承的功能-请记住P&#39;(permitted)= F(permitted)&amp; P(边界)。如果线程在其可继承集合中维护的功能不在其边界集中,那么它仍然可以通过执行一个在其可继承集合中具有该功能的文件来在其允许的集合中获得该功能–记住P&#39;(允许) = P(可继承)&amp; F(可继承)。
执行由于设置用户ID或设置组ID位而更改UID或GID的程序,或者执行具有任何文件功能集的程序,将会清除环境设置。使用PR_CAP_AMBIENT prctl将功能添加到环境设置。这种功能必须已经存在于流程的允许和可继承集合中。
如果具有非0 UID的进程执行execve(2),则将清除其允许和有效集中存在的所有功能。
除非设置了SECBIT_KEEP_CAPS(或更广泛的SECBIT_NO_SETUID_FIXUP),否则将UID从0更改为非0会从允许的,有效的和环境的设置中清除所有功能。
…这只是意味着它试图以非特权(非0)用户身份监听端口80,并且其有效功能集中没有CAP_NET_BIND_SERVICE。要获得这种功能,必须使用xattr文件功能并将nginx文件功能设置(至少使用cap_net_bind_service + ie)(使用setcap)。此文件功能将与继承的集(由pod的securityContext / capabilities / add / NET_BIND_SERVICE设置的设置以及边界设置)一起进行扩展,并使其也成为允许的设置。有效地导致最终结果= cap_net_bind_service + pie。
只要securityContext / allowPrivilegeEscalation为true并且您的docker / rkt存储驱动程序(请参阅docker信息)支持xattrs,那么一切就可以正常工作。
如果nginx是功能智能二进制文件,那么cap_net_bind_service + i文件功能就足够了。然后,它可以使用libcap将功能从允许集扩展到有效集。也会导致= cap_net_bind_service + pie。
除了使用文件xattrs之外,在非根容器中实现cap_net_bind_service的唯一方法是让Docker设置环境功能。但截至4/2019,尚未实施
这是使用libcap将cap_net_bind_service添加到有效集中的示例代码。这需要在二进制文件上设置cap_net_bind_service + p文件功能。要编译并运行它:$ gcc -lcap captest.c -o captest $ ./captest当前进程功能(+设置):= cap_set_proc:不允许操作添加文件功能之后:$ sudo setcap cap_net_bind_service + p ./captest $。 / captest当前进程功能(+ set):= cap_net_bind_service + p绑定成功! :)
H.Plötz还制作了一个漂亮的图表,总结了线程集,二进制集和应用于被执行子级的集之间的关系。图片来源归功于H.Plötz。