关于整数的概念
最近关于(和质疑)AVX512的效用有相当大的讨论。虽然已经有许多学术论文和商业系统通过使用传染媒介指令,但在这里,我将在这里展示一个更多的行人和简单的分析用例。本文部分受到理查德网站的优秀ACM文章的精彩ACM文章。只有通过深入了解简单的程序,我们希望解决更大的程序。
假设您希望总结32位整数的序列。如果数据存储为STD :: Vector< int> ,Naive循环求和元素甚至可能会自动矢量化,并且您将获得直接转发代码的明智性能。
假设您现在知道更多关于您的数据的内容,即大多数值实际上可以适合单个字节。使用4个字节将每个值存储在ram容量和存储器带宽(&能量等)方面浪费,在求解数据时消耗的内存带宽(&能量等)。
可以使用我们对价值分布的知识的数据的一种可能的编码(肯定不是最佳的)是以下(越怪诞链接;媒体有可怕的格式):
结构数据{std :: vector< char> bytevals; // bytevals [i] == -128意味着看看INTVALS STD :: Vector< Int> Intvals; //长度为bytevals void push_back(int v){char bv = v; if(bv == -128 || bv!= v){bytevals.push_back(-128); Intvals.push_back(v); } else {bytevals.push_back(bv); }};
这里的值[-127,127]只需要一个字节来存储,每个其他int值有效地存储5个字节才能存储。如果所有值的大小分数都在[-127,127]中,则在存储和求解值时,这将取得更少的空间(&带宽等)。请注意,此编码保留了值的原始顺序。我们不会在下面使用此属性,但它可能有用,例如,如果将其用作柱状数据库中的轻重压缩策略。
对于博客文章的其余部分,我们将假设数据中的75%的值在范围内[-127,127],另一个〜25%不是。数据将包括1亿整数。我们还将仅关注单线性能。我们还将忽略下面的C ++代码中的未定义行为,因为这只是玩具代码。
现在考虑求解在此数据结构中表示的值的任务。一个天真的标量循环可能看起来像这样:
int sum_scalar(数据& d){int intvalindex = 0; int sum = 0; //忽略overflow UB for(自动b:d.bytevals){if(b == -128){sum + = d.intvals [IntvalIndex]; IntvalIndex ++; } else {sum + = b; }}返回总和; } ------------------------------------------- -----------------基准时间CPU迭代--------------------------- -------------------------------- BM_SCALAR /迭代:10 269462740 NS 270312500 NS 10
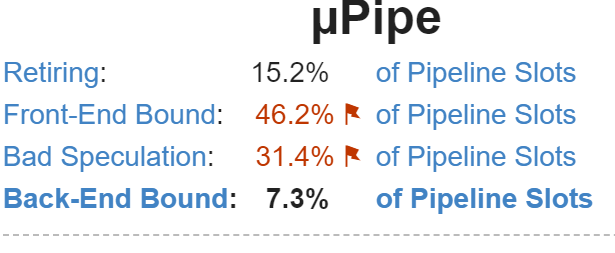
如果您使用VTUNE进行了配置文件,您会发现相当数量的执行插槽(〜31.4%)浪费在“糟糕的猜测”上。如果您不熟悉此,请参阅[1]。
如果我们认为回到我们的数据分发,那么易于看出为什么这可能是这种情况:处理器在检查Sentinel值时,处理器没有希望从分支历史中锁定到可预测的模式上。这将导致众多分支机构错误预测,导致由于管道冲洗而浪费的工作和摊位。
可以通过以下方式对此进行补救并将其转换为分支的求和:
int sum_scalar_branchless(数据& d){int intvalindex = 0; int sum = 0; //忽略溢出UB for(自动b:d.bytevals){int cond = b == -128; SUM + =(1 - COND)* B; //可能的OOB访问权限,然后乘以0;忽略UB Sum + = Cond * D.Intvals [IntvalIndex]; Intvalindex + = Cond;返回金额; } ------------------------------------------- -------------基准时间CPU迭代----------------------------------- --------------------------- - bm_scalar_branchless 125660283 ns 125000000 ns 6
这结果略高于2倍。 VTUNE显示〜84%的执行插槽是退休的UOPS。
要大大提高(未声称这是绝对最快的),我们将利用各种AVX512功能/说明(在ICELAKE I5-1035G4笔记本电脑上):字节颗粒混合物,字节粒度比较和VNNI(在神经网络之外!):
更新:请参阅https://www.realworldtech.com/forum/?threadid=200693 & zhostid=200694为戏剧性的简化。没有抓起这是我的疏忽。此帖子将被更新以包含所提到的策略的数字。
更新:到我的惊喜,经过大量摆弄,我没有设法编写一个可测量的版本,比下面所示的手写Sum_avx512更快(确实它们至少是较慢的百分比)。几乎肯定是我做错了,但我似乎无法弄清楚它是什么。我将借此机会将此作为读者的锻炼:)。
int sum_avx512(数据& d){int n = d.bytevals.size();断言(n%64 == 0); int intvalindex = 0; //忽略溢出UB自动vsum = _mm512_set1_epi32(0);自动vsum2 = _mm512_set1_epi32(0);自动numintvals = d.intvals.size();自动numintsprocessed = 0; for(int i = 0; i< n; i + = 64){__m512i v = _mm512_loadu_epi8(& d.bytevals [i]); // 1在其中值为-128,0否则__mmask64 mask = _mm512_cmp_epi8_mask(v,_mm512_set1_epi8(-128),_mm_cmpint_eq); //将-128值转换为0,因此我们避免求和它们v = _mm512_mask_blend_epi8(mask,v,_mm512_set1_epi8(0)); / * DST = _MM512_DPBUSD_EPI32(SRC,A,B)将4个相邻的A相对的无符号8位整数组乘以B中的相应符号的8位整数,产生4个中间符号16位结果。使用SRC中的相应的32位整数以及将Packed 32位导致DST存储的32位整数。在DNN&#39之外的vnni使用!!! * / vsum = _mm512_dpbusd_epi32(vsum,_mm512_set1_epi8(1),//乘以1保留值v); // Interleave处理INTS填充执行插槽(NumintVals - NumintsProcessed> = 16){vsum2 = _mm512_add_epi32(vsum2,_mm512_loadu_epi32(& d.intvals [numintsprocessed]); numintsprocessed + = 16;自动RET = _mm512_reduce_add_epi32(_mm512_add_epi32(vsum,vsum2)); //无需在这里尝试最佳;只有剩下的剩余元素int,剩余时间= 0; for(; numintsprocessed< numintvals; numintsprocessed ++)剩下+ = d.intvals [numintsprocessed];返回RET +余量; } ------------------------------------------- ----基准时间CPU迭代------------------------------------ ----------- bm_avx512 9435973 ns 9375000 ns 75
很难做到的那么好(至少使用此数据表示),因为我们几乎处于单核存储带宽的极限:
您可能会想知道在仅仅存储为STD :: Vector< Int&gt的数据时,可以想知道性能是自动矢量化循环(通过查看组装验证)。 (没有压缩技巧)。
int sumvec(std ::: vector< int& vec){auto v = vec.data(); int sum = 0; for(int i = 0; i< n; i ++)sum + = v [i];退货总和; } ------------------------------------------- ----基准时间CPU迭代------------------------------------ ---------- - BM_VEC 20682647 NS 21139706 NS 34
事实证明,比压缩数据表示的手矢量化总和慢〜2.19x。 VTune数据:
显示〜82.4%的执行插槽停止在内存上。对于这两个和之前的手矢量化AVX512代码,我们基本上接近/在单核内存带宽附近。压缩表示的总和仅仅是因为从DRAM转移了更少的字节。实际上,带宽改善大约为4 /(1 * 0.75 + 5 * 0.25)= 2,这与观察到的性能改善相当接近。
虽然数据量爆炸,但CPU的性能改进继续缓慢,DRAM价格继续停滞不前。我相信这最终将强迫软件行业远离浪费和“硬件不可知论码”。少收获,我会考虑它的硬件无知代码。正如Amin Vahdat在这个优秀的关于硬件和软件的未来的主题演示中,我们将无法再忽略整数因素潜在改进。 AVX512和硬件感知/硬件特定代码更广泛地,将成为本未来的关键部分。
[1]亚辛,艾哈迈德。 “绩效分析和柜台架构的自上而下方法。” 2014 IEEE系统和软件性能分析国际研讨会(ispass)。 IEEE,2014。