使用基因座方法的耐用记忆和高效的神经编码
Warning: Can only detect less than 5000 characters
Warning: Can only detect less than 5000 characters
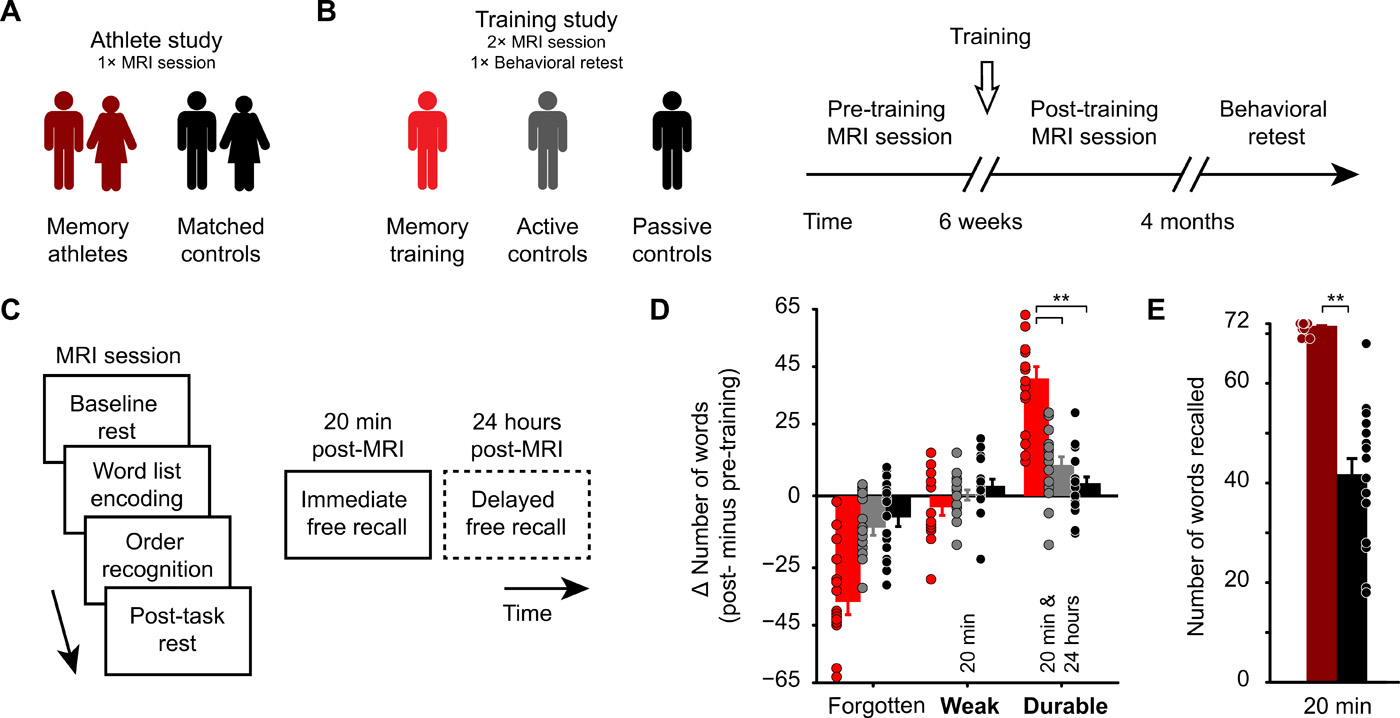
为了阐明结果是否实际上是由于内存训练组中的激活减少而不是通过群体差异已经预先训练,我们执行了额外的兴趣区域(ROI)分析,并从显着的相互作用提取平均激活值群集,确认上面的结果(结果S3)。此外,在编码文字列表中的记忆运动员和记忆训练组(训练训练组(训练后)之间的激活水平没有显着差异[独立样本T测试,对比度编码>基线,协变量在立即免费召回测试期间召回的单词数量;记忆运动员,n = 17;内存组(训练后),n = 17],表明运动员的类似激活概况,最初在训练基因座方法后的助记符 - Naïve参与者。
最后,我们执行了额外的后续内存分析(结果S4;请注意,这仅基于参与者的子集)。如果激活减少与耐用的存储器形成有关,同时应用基因座的方法,我们预计与弱或被遗忘的编码相比耐用的更强的减少。虽然结果证实我们在与对照组相比,我们在内存训练组(训练后)中的激活普遍下降,但结果没有特定于持久的内存形成。因此,激活减少与在不同组中编码期间的通用存储器处理有关,但与耐用的存储器形成没有显着相关。
在基因座的方法中的专业知识可以积极影响识别性能,同时减慢响应时间
在Word List编码之后,参与者完成了时间顺序识别任务,其中以先前研究的相同或不同的顺序以相同或不同的顺序呈现单词三元组的时间顺序识别任务(图1C和3A)。我们专门开发这项任务作为召回的先生兼容衡量标准,并且由于记忆培训组(培训后)的记忆运动员和参与者被要求在时间顺序识别期间使用基因座的方法(即,他们被要求在精神上通过他们的记忆宫,串行检索Word-Loci关联),这些参与者应该在判断单词顺序时擅长。
与匹配的控制相比,记忆运动员确实显示出明显更高的识别性能(通过D-Prime指定)(Wilcoxon签名 - 等级测试;一个匹配对被排除在分析中;记忆运动员,N = 16,中位数= 3.54;匹配的控件,n = 16 ,中位数= 2.38; v = 131.5,p = 0.001;图3B;请参阅结果S5进行响应时间)。然而,尽管在训练后的记忆训练组中的D-Prime分数数量增加,但三组之间的识别性能没有显着差异(D-Prime的变化;图3C;单向ANOVA;记忆训练组,N = 17;有源控制,n = 16;被动控制,n = 17;组的主要效果,p = 0.133,成对比较:内存训练>主动控制:p = 0.135,效果d = 0.592;记忆训练>被动控制:P = 0.294,d = 0.569;活性>被动控制:p = 0.898,d = -0.161;请参阅结果S6,从训练前和训练后的D-Prime一般增加)。此外,记忆培训组的参与者在训练后显示较慢的响应时间(结果S5)。因此,在记忆运动员中具有积极影响的识别性能的基因座的专业知识。虽然记忆培训对最初的助记符 - 诺维参与者的识别性能的影响似乎是阳性的(但注意结果不显着),结果伴随着一般较慢的反应。
在运动员中的时间顺序识别期间,基因座的方法降低了后部PARAHIPPocampal和retrosplenial的激活,并且在训练后最初助记符 - Naïve参与者
接下来我们转向时间顺序识别期间获取的神经影像数据。由于在订单识别期间,要求记忆培训组(培训后的参与者的记忆培训组(训练后)的参与者,我们预计通常与诸如海马,例如海马的成功内存检索相关的大脑区域的接合和逆血管皮质(4,7-9,12,15,17)。由于在组之间不均匀地分布了正确和不正确的试验,我们将识别试验与隐式,活动基线(音节计数)进行了比较,其中单个D-Prime分数作为协变量(参见“MRI数据处理:任务数据”部分) 。
类似于激活的轮廓在前面的单词列表编码任务期间减少(见上文),结果表明右后疗成堆PPocampal和双边逆血平皮质内的激活减少(x = 30,y = -40,z = -12,z值= 4.54,142体素),以及双侧上顶部的旋转(左:X = -16,Y = -58,Z = 23,Z值= 5.31,501体素;右:X = 20,Y = -60, z = 22,z ......