真实世界的GPT-3简单语言根本原因摘要
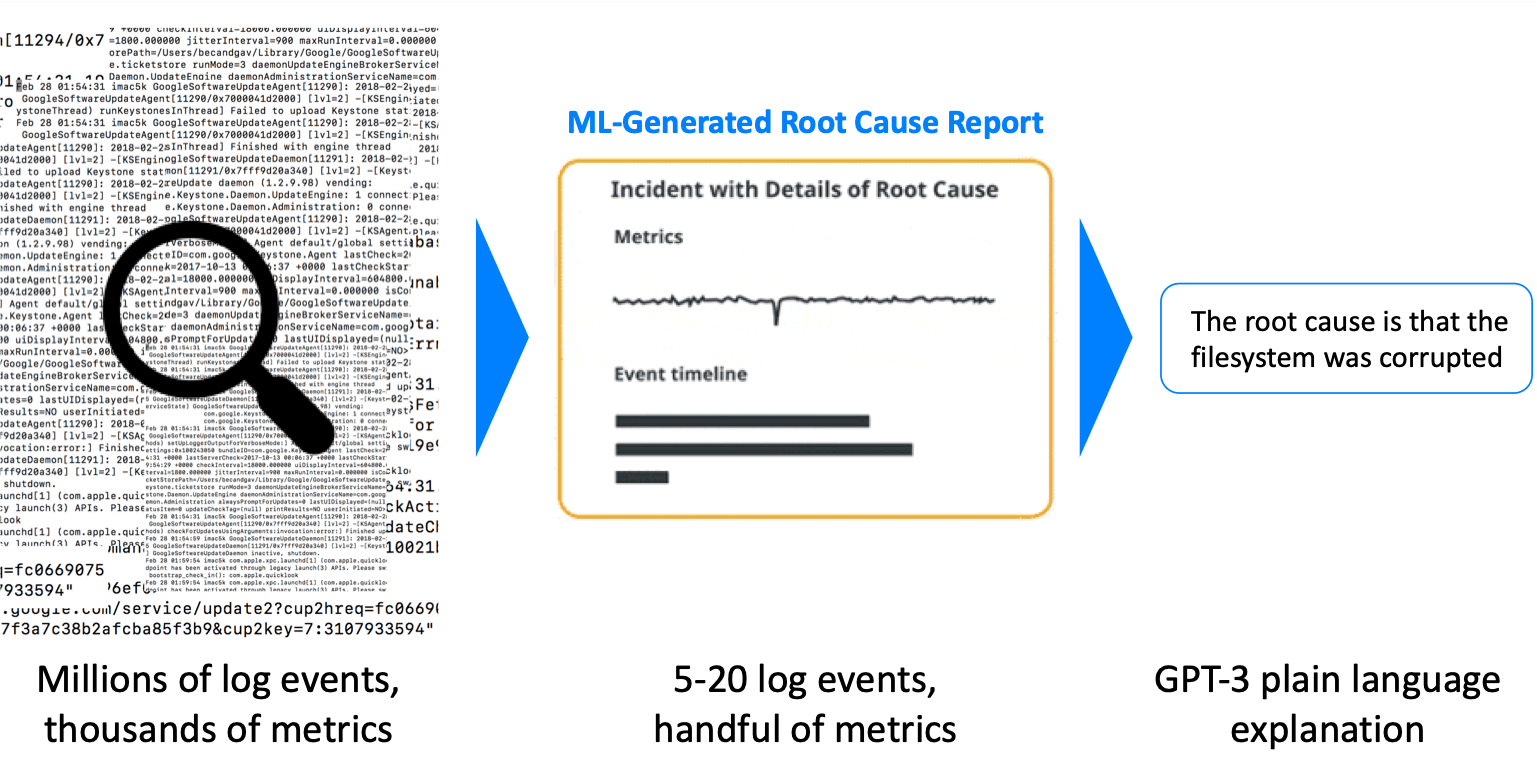
几周前,Larry我们的首席技术官写了一个新的测试版功能,它利用了GPT-3语言模型 - 使用GPT-3从日志中使用GPT-3进行纯语言入射根原因。重新覆盖 - 斑马中的无人监督ML标识事件的根本原因,并在序列(通常是根本原因),最差症状,其他相关事件和相关度量异常中识别第一个事件的简明报告(通常在5-20日志事件之间)。
由于Larry指出,这适用于熟悉日志的开发人员,但如果SRE或Frontline Ops工程师不熟悉应用程序内部,则可能很难消化。 GPT-3集成允许我们采取下一步 - 蒸馏这些根本原因通过扫描整个互联网来提示自然语言摘要,以便提取用户扫描的简要“英语”描述。
在几周后,使用有限的小组测试此功能,并审查了几百个事件的结果,我们现在准备分享一些令人兴奋的结果并扩大对所有斑马用户的访问,甚至可以免费试用。
简而言之 - 它起作用如此良好,在如此广泛的情景中,我们觉得大多数用户将受益于访问它。这些摘要既准确无误,真正有用 - 将日志事件蒸馏出来,描述了前线或经验丰富的工程师可以轻松理解。
这仍然是我们的早期阶段,并且有些情况下,GPT-3位进入猜测,并建议似乎与核心RCA报告相关的摘要,但并不完全正确。为了确保用户知道这一点,我们将摘要标记在UI中的“实验”徽章。
还有特定的RCA报告不会生成特别照明的自然语言摘要,而不是重新映射密钥日志事件。例如 -
第一个日志消息是一个致命错误,指示程序检测到问题并中止。
这些次优不可思议的结果有几个可能的原因。一种可能性是,在公共领域中的那种问题的情况下简单的例子,因此GPT-3正在响应它可以找到的最接近的细节。另一种是我们还没有探索我们可以与GPT-3模型一起使用的提示和选项的所有变体。
好消息是,即使结果是次优,它们也大多不误导,很容易被忽视。更重要的是,我们的ML生成的根本原因摘要是GPT-3的完美输入来源,并且随着更多的工作,结果将从这里变得更好。
伟大的消息是它实际上比不是常用,结果实际上非常有用。以下是GPT-3摘要真正描述了事件收集的一些示例,并且对用户真的有帮助快速消化RCA。注意:我们有可能具有潜在敏感的混淆详细信息,我们不会出于同样的原因分享原始日志事件,尽管它们与摘要相比将是有用的。
作为第一个桶,这里有一些与记忆饥饿有关的一些有趣和有用的事件摘要:
该应用程序正在尝试攻击子流程,但是叉呼叫失败,因为系统退出内存。
Memcached进程被Oom杀手杀死,因为它会消耗太多的记忆。 OOM killer是一个Linux内核功能,允许系统在内存中运行时杀死过程。
内存cgroup没有内存,所以内核杀死了进程****和它的孩子****。
AWS机器图像AMI,客户使用的是x86_64架构,但客户的实例类型是ARM64。 问题的根本原因是Jenkins Master无法连接到vCenter Server。 群集在沉重的负载下,调度程序无法安排POD。 第一条消息是SQL错误,这意味着数据库服务器无法执行查询。 问题的根本原因是证书链与任何信任锚不匹配。 问题的根本原因是服务器上的SSHD守护程序被配置为仅允许每个IP地址的三次身份验证尝试。 服务器拒绝了连接,因为它已经看到了该用户的太多无效的身份验证尝试。
我们的重点是使用机器学习剪切故障排除时间来总结基于日志和相关度量异常的事件序列的关键事件序列。 GPT-3集成对我们的目标来说是一个很大的一步 - 使任何人都能快速审查RCA报告,甚至可能不熟悉申请内部的人员。 如上所述 - 仍然存在改进,但它在真实世界的场景中起作用,我们现在将其开放到所有用户。