我用一个python脚本击败了柏林租赁市场
通常,这意味着价格往往会增加。这就是曾经在柏林发生的东西。然后,几年前,城市市政府通过了一个有争议的租金控制政策,防止价格增加了至少5年。
由于缺乏财务激励,住房供应(而不是扩大)。那些合同的人尽力不要远离它,即使他们喜欢。
今天,在柏林租赁与消费能力有关,与竞争有关:您可以找到租金优惠,您可以享受十几个人的公寓,您祈祷房东将在其他人中选择您。
有两个元素会影响您选择的能力并获得合同:您的个人资料,以及您的速度。
至少在短期内,您没有太多的空间来改变您的个人资料。然而,速度是你可以玩的东西。
这是一项琐碎的策略:你先要求访问,你先去观看,你申请先拿到房子。没有保证它将工作,但它给你了一个优势。一些机构被迫在给定的时间范围内分配房屋,并可能满足于“足够好”。其他人可能是没有经验的业余爱好者,鸡出来,只是在队列中迈出第一个。
这种方法的关键问题是您有效地制定了大规模的财务决策 - 至少1-2岁 - 在几小时内的收入的50%,如果不是分钟。一个大的否。
要反击这一点,你应该用你的思想来看看。然而,这并不总是容易:需要几个月的经验,开始制定一个在特定房屋的价格是什么意义上的直觉。讨价还价或福福?很难说。
在混合中,您还应该考虑租赁报价将改变价格的机会:真实,竞争是坏的,但有时房东的含量非常糟糕,并获得一组申请人,他们判断得太小。所以他们最终降低了希望吸引更好的候选人的价格。
如果你能负担得起,那么等待很多,然后尽可能快地努力。像股票市场一样。
当我开始追捕时,我意识到这一切都归结为量化房子与类似房屋的昂贵程度。这比完成更容易。 “类似的房子”真的是什么意思?它比采取平方米的成本更加差别:在考虑其阳台或其位置或其在该地区缺乏犯罪时,更昂贵的房屋可能会比较便宜。这是一个搜索优化问题,但在播放时有一个具有相当虚弱的变量。
我会破坏这个故事的结束:我最终能够找到一个我喜欢的房子。
我付出的价格低于市场如何评估其价值(平均)。观看中有10个人,但他们仍然选择了我,最有可能因为我是第一个申请的人。在观看后,我从公寓前面的街道上派出了文档。
我能够这样做,因为我敏锐地意识到邻里的具体特征,因为房子已经改变了两次( - 7%,而另一个--6%),不太可能再次改变价格,因为很可能很快租来。我认识到这一切,感谢几个预测模型和几个周末刮掉了房地产数据。
我需要的第一件事是数据。我写了一个快速刮刀,在服务器上部署它,让它松动。目标是建立城市所有住房优惠的数据集:成本,地理位置和描述属性的基本参数。
我想快速移动和切割 - 这是(应该是)周末项目,而不是一个巨大的种类产品。我为MongoDB定居为首选数据库。我读了许多关于蒙古的坏事,但它是坏的原因是我喜欢它的原因:超高的灵活性,超低约束(规模需要,但速度妨碍速度)。我只需要在某处抛弃一些数据:我无法不在乎迁移和DTO一致性。
我也没有复杂的chron:它是一个在Tmux窗格上不断运行的Python脚本,连接到MongoDB Atlas免费实例。为此,我只添加了一个jupyter scratchpad来玩结果。
在房地产中,这完全是关于地点的。虽然位置是什么意思?是邮政编码吗?这是城市社区吗?我尝试了一切。邮政编码缺乏粒度:它们太宽阔而不合适。社区有点更好,但它们也太广泛而无法实现精确分析。
我最终定义了这个城市的所有社区 - Prenzlauer Berg,Kreuzberg,Charlottenburg等,那么,我迭代地切成两半,直到得到的细胞(我称之为“Quarters”)并不小于a从一个边界到另一个边境的步行距离5分钟。
在一个理想的世界中,我应该用一个无监督的算法(更加权更多的算法来定义这些群集,但我缺乏足够的租赁提供,并且我在所有现有建筑物上发现的历史数据不可靠(它返回到70年代,在墙壁落后:不是描述当今柏林的最佳方式)。
要存储信息,我使用了Geojson。它是由Mongo的本地支持,并且开放使得可以轻松找到我可以使用的图书馆。
最棘手的部分是计算距离。从点-A到point-B的距离不是一条直线,因为它们在圆形表面的顶部。幸运的是,像pyproj这样的图书馆和匀称地来到救援。
通过关于租金的信息和在合理区域中对其进行分组的简洁方式,我继续向数据集添加一些功能。
我继续抛弃我可以的所有数据。对于每个地区,我创建了一组分数和指数,描述了公共交通的质量,汽车分享车辆的平均密度,安全和犯罪,户外活动,酒吧和食品场地的数量和质量。
我用了一系列服务来这样做。在某些情况下,我必须自己制作数据(汽车分享和公共交通工具:在这里有些好老刮)。在其他情况下,数据在公共数据集中方便地交出。
我标准化了分数,使它们容易跨越地区。结果是我在城市关心的有趣数据的一个很好的地图。
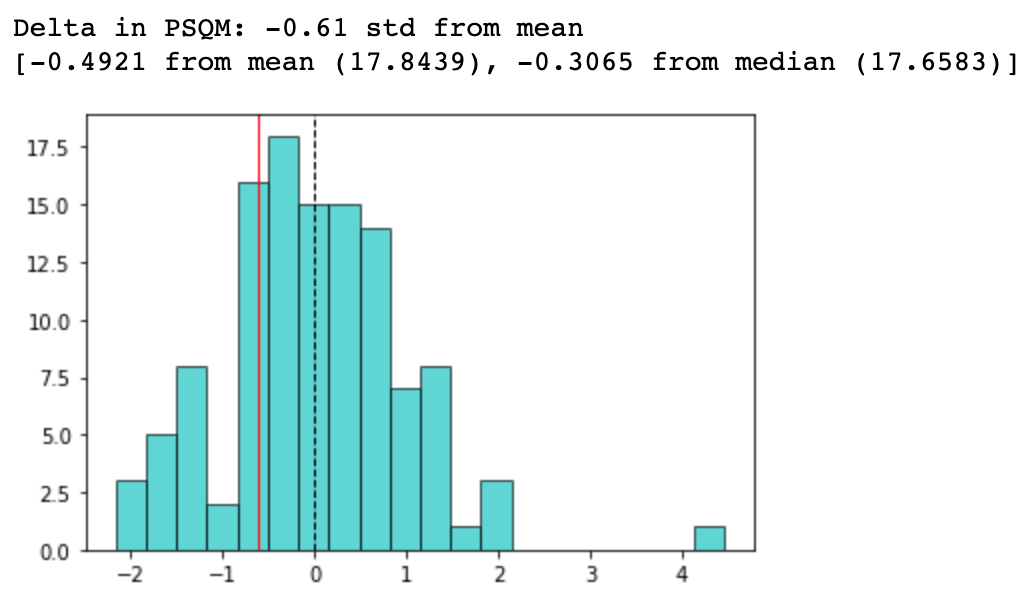
我工作的第一个号码是一个“市场对齐”得分:与市场上类似的产品相比,给定提供的价格有多远?换句话说:它是值得的,他们要问吗?
为了计算市场对齐,我从被考虑的人中占据了5km的半径范围内的所有产品。然后,我只保留在池中,那些是:
»在租金价格的±1标准偏差范围内,其客房数量,生活空间及其建设年份,
»在±1.5内的标准偏差范围内,它位于该地区的一般特征内,
这通常持续〜5%的初始优惠组。可以使用数字 - 例如,通过增加初始半径:更多数据但可能更加精确。经验上,这效果很好。
在这个子组中,我然后计算每平方米的价格,并看到租金提供的租金来自子集团的平均值:
这个号码足以让我有一个合理的想法,市场考虑了“公平价格”,而且如何提供该报价的实际价格。如果是一个基本上负面的delta,我是一个很好的交易。
我还计算了两个人:租金即将售罄的可能性很快,价格下降的可能性下降。
要获得这些数字,我训练了两个监督模型。我精致的管道和封闭式遗传编程在AWS GPU-reforms上(仍然是机器学习的最简单方法,而且非常昂贵:这个空间中有这么多的破坏空间)。我没有时间在模型上工作 - 再次:这是一个周末项目 - 所以拥有一台机器对我进行沉重的提升,即使较低的是我需要的。
我不会撒谎,我有一种感觉,所有这一切都有点过度设计。我发现了一个我超级满意的房子,但也许有一种更简单的方法。无论如何,这是一个有趣的机会,了解柏林房地产市场,探索我不熟悉的技术。
我现在正在将这项工作转变为Web应用程序。再次,探索技术和营销策略的良好机会。
如果是这个产品的市场,我真的没有线索。我也不知道谁可能是最有效的人口,以从作为上市战略开始。我目前正在测试一些想法(周末严格!),初步结果非常有趣。
这不会解决柏林的房地产问题。为此仅有一种解决方案:构建更多的房屋。这个工具的目标是(并且将是,前进)最多发现很大的优惠,而不是在最坏的情况下拧紧。
我正在考虑的两个人的主要集群:房地产经纪人,试图利用套利的机会,年轻的外籍人士与中等高度的消费电力(例如,您的平均开发人员)试图有意识地租用。
如果您享受此内容,请在Twitter上关注我,我将继续发布关于我的建筑活动的更新。如果您有疑问,请随时伸出协议:我的DMS是开放的。
/ *感谢艺术&呃,这帮助我编辑了这篇文章的早期草案。 * /



