行动前缀树
帕累托原则和性能:20%的认识性分析工具和数据结构通常足以解锁80%的优化
这常说,你在大学里学到了什么,只有你毕业的那一天。毕竟,大多数软件开发人员都不编写自己的排序算法,或从头开始创建双链接列表。但这也可以是自我实现的预言 - 如果您不希望使用更高级的数据结构,您将无法寻找机会。
我们最近遇到了一个这样的机会,在其中替换一个数据结构,通过少于一百条代码解决了我们的性能问题。
我们的团队构建的一个功能是处理我们从外部源获得的HTML文档,并通过添加链接将它们连接到我们自己的医疗内容。例如,在下面的片段中,我们可以用与我们知识库的联系取代术语“急性心力衰竭”。
< p>关于急性心力衰竭等的东西,等等< / p> < p>一些关于< href =“https://www.amboss.com/us/knowledge/acute_heart_failure" ;>> an>,等等。
但我们如何知道哪些词可以链接?此数据来自amboss的内部服务。更确切地说,我们可以向该服务发送一个字符串列表并获取目标对象列表,其中每个对象包括可以链接的确切项以及构造锚元素的一些元数据。在上面的赛段中,该服务将返回一个目标对象,其中术语是急性心力衰竭。
我们的工作现已扫描我们为我们收到的目的地提供的单词(或单词序列)的文档,并用锚替换它们。
这个程序的第一个版本是我们以编程方式生成的巨大,正则表达式。但这太慢了,所以我们将它转换为自定义循环。
基本上我们通过字符完成了文档字符的文本内容(虽然Go使用Unicode CodePoints,名为Runes),我们将每个字符添加到可变的变量,该变量跟踪当前短语。对于上面的代码段,该变量将像这样进化:
S→SO→SOM→......→某种东西→白色空间→检查是否有目的地,插入链接,清空变量并继续前进。
这首先努力工作,但我们很快意识到它有一个巨大的缺陷 - 它不会用于跨越多个词的目的地,如急性心力衰竭。我们的算法会找到单词心脏并用链接替换它。然后它将处理下一步失败的单词。但是,它永远不会陷入心力衰竭。
我们通过首先检查当前短语是否是任何目标对象的子字符串来解决此问题。在这种情况下,我们将继续迭代并将字符添加到当前短语。这给了我们可以链接的最长序列。这基本上是嵌套循环:
对于_,字符:=范围DocumentContent {// ...执行其他东西,直到我们遇到Dest的空白空间:=范围目标{如果strings.hasprefix(dest.term,currentphrase){fall.writerune(空格)继续外}}}
此时,您可能会想知道为什么我们会写一个嵌套循环,当时显然效率低下。
正如我所提到的,第一次迭代使用了正则表达式。这结果是一个瓶颈,所以我们使代码更快。与其余的程序相比,有问题的代码不再是一个问题。当我们优化了该程序的其余部分时,链接加法器功能再次成为最慢的代码路径。所以我们回到了绘图板。
这种迭代的发展方法可以很好地工作,因为它鼓励您将更改的范围限制为仅在手头上修复问题。但是我还承认我们可以跳过一次迭代,我们意识到我们的第一次修复(从正则表达式到循环)仍然有巨大的改进潜力。
请记住,始终始终是关于权衡的重要意义。许多代码基础都充满了嵌套循环,但这不会使这些程序固有慢。它始终取决于您循环的数据。一个嵌套的循环运行10次不是问题,但是一个必须处理十亿个元素的单个循环可能是。
因此,快速节目的道路上的第一步是测量!跳转并编写一些代码很诱人,但这一切都经常导致良好的意思修复并没有帮助。制作一个占总运行时的1%的操作速度速度越快,比制作占Runtime10%的50%的东西更快的效果远得更加有效。
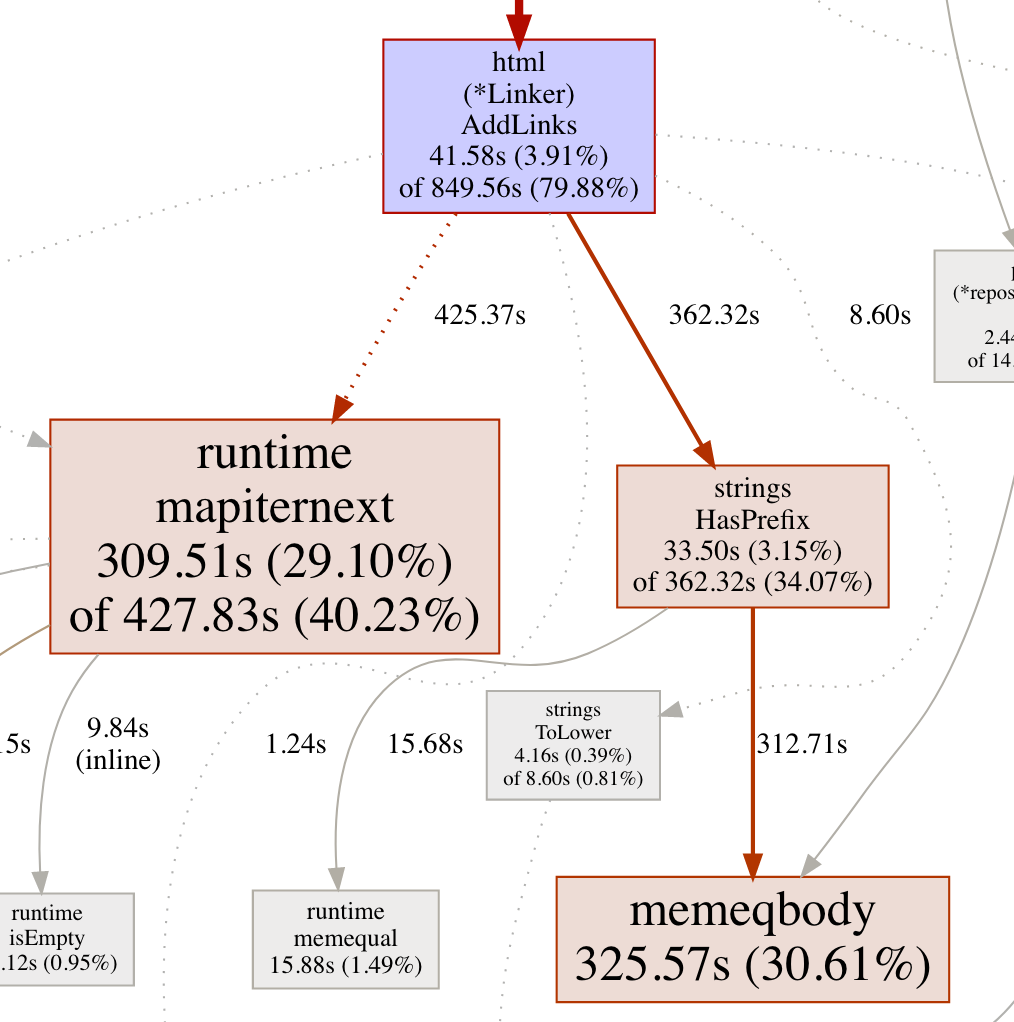
幸运的是,剖析很容易。我们有一个环境变量,当打开时,在main()中调用pprof.startcpuprofile(filename)。然后,我们使用go tool pprof -http localhost与go tool pprof-hpprof hprof ./cpu.pprof并找到了它:
即使你以前从未见过剖面产出,那么大红色盒子似乎是善候选人来调查。 runtime.mapiternext是一个函数调用,它占用了近30%的采样运行时。 Memeqbody甚至更糟糕,30.61%。这两个功能单独构成我们的运行时的大部分。
谁叫这些功能?我们在AddLinks中做到了 - 在本文的第一部分中描述的所有扫描和链接的函数。
现在我们知道哪些功能很慢,但我们尚未知道哪条线路负责。如果我们能弄清楚地图内容所做的,我们也可以铭刻它的位置。文档ISN' t非常有用,但从查看源并考虑代码的名称和上下文,它表明该功能涉及从一个地图键移动到下一个地图。换句话说,我们花了太多时间为k,v:=范围映射{}。
另一个拼图是MEMEQBODY,其参与串比较。由于此函数调用是strings.hasprefix和we'重新调用在内部循环中,它很清楚嵌套循环确实负责我们的代码的速度速度。
因为数学使任何博客帖子看起来很想,我们也可以检查我们代码的大o复杂性。
我们迭代n个单词,当我们遇到一个字边界时,我们会在m链接目的地上嵌套循环。对于每个目的地,我们调用hasprefix,它必须至少遍历p(前缀长度)字符。
让我们忘记代码,并立即考虑我们在正常的人类语言中尝试在这里做的事情。我们希望用链接替换单词并始终支持最长的顺序。如果我们有“心脏”和“心力衰竭”的目的地,我们希望偏爱后者。
因此,我们需要知道我们正在处理的短语是否是任何目的地的子字符串。实际上,我们对这句话是一个目的地的前缀。 🤔
这是一小位教科书知识的观点很长。您不必记住每个树数据结构,只要您含糊地意识到整个树木擅长处理前缀搜索:尝试。
一个Trie,也称为前缀树,非常适合自动完成和搜索建议 - 用户进入一个单词的第一部分,您需要快速查找适合该前缀的更多单词。
用图表解释比单词更容易,所以这是“心脏”和“心力衰竭”案例的假设表示。
在TRIE中,节点通常是字符串,节点由各个字符连接。在上面的示例中,第一非空节点H和节点(之后)通过字符e连接。我崩溃了这两片叶子(心力衰竭和心脏燃烧),就是如此'更容易想象。另请注意,任何节点的子项共享前缀,这意味着心脏的孩子都分享了心脏前缀,这对于我们的用例非常完美。
在这个三个节点中,三个节点将保持一个值:心脏,心力衰竭和心脏烧伤。这些值可能是任何东西,但在我们的情况下,他们是目标对象。因此,我们不仅可以使用TRIE来检查Therphrase是否是已知目标的前缀,但我们还可以检索该目标对象。
如果我们向Trie询问心脏的目的地对象,我们期望回来了什么?
显然,我们'重新寻找与节点心脏相关联的值。但是有两个可能是相关的节点,因为它们包含我们要求的前缀。在这样的情况下,它的'检查你和#39的任何库的文件很重要;重新使用。它可能会区分精确匹配(例如,询问心力衰竭)和含糊不清的比赛(例如,询问心脏)。
最后,我们可以预期使用Trie什么样的性能?对于任何查找,我们可以将搜索字符串中的每个字符视为路径段。您可以想象搜索心脏以类似于根节点的开始,并按照字符H的连接,然后通过他的连接,等等。
因此,大o复杂性是O(k),其中k是搜索字符串的长度,无论我们拥有多少个目标对象。
通过以前的解决方案,我们有O(n * m * p)复杂性。我们用O(n * p)替换了。这是一个巨大的改进,因为我们有数千个目的地(M),而搜索字符串(P)通常在1-20个字符范围内。
添加尝试对我们的代码非常直接。它基本上是为了更换内部环,如下所示。
对于_,字符:=范围DocumentContent {// ......执行其他内容,直到我们遇到白色空间,如果destinisttrie.hasprefix(currentphrase){短语.Writerune(空格)继续外部}}
因此,而不是迭代地图中的所有键,并将每个键与当前前后进行比较,我们只需对我们的Trie进行一次呼叫,这里称为DestinationTrie。周围的代码可以保持完全相同,这使得一个相当小的提交!
当然,我们仍然需要验证我们的变化确实明显更快地取得了巨大的东西。因此,我们以前跑得完全相同的基准(否则很难真正比较数据),实际上Memeqbody占用325.57s即可仅为11.43s。 Mapiternext不再显示在前10个函数调用中。
除了整个运行中,我们还使用Go的支持,以获得更详细的思想,以便addlinks的新实现是多少:
在367244 3231 NS / OP 1728 B / O 38 Allocs / OP之后775364 1344 NS / OP 944 B / O 23 Allocs / OP
新实现每次操作需要1344纳秒(NS / OP),因此速度快2.4倍。它还分配较少(每次操作38 vs分配),甚至没有焦点我们的焦点。
我们计划的整体运行时间,由人类坐在机器前面的人面前,也达到了大约三分之二。
代码复杂性很难衡量,但我认为代码现在比以前更简单。
因此,我们需要知道我们正在处理的短语是否是任何目的地的子字符串。
前缀树实现是上述要求的代码中的相当等效。我们之前有过的循环是一个实施细节,并使我们从整体目标分散了。从某种意义上说,代码现在正在采用更高的抽象。
最后,代码大小没有增加,因为这些数据结构存在各种开源实现。
尝试是前缀树,他们很高兴问,“你有这个前缀有什么吗?” 这篇文章是否达到了兴趣? 我们正在招聘整个工程团队。 今天申请!