Git作为NoSQL数据库(2016年)
Git的人页陈述它是一个愚蠢的内容跟踪器。这可能是世界上使用最常用的版本控制系统。这是非常奇怪的,因为它没有将自己描述为源控制系统。事实上,您可以使用Git跟踪任何类型的内容。您可以例如创建Git NoSQL数据库。
它在人页中说愚蠢的原因是它没有假设您存储的内容。底层Git模型是基本的。在此帖子中,我想探索使用Git作为NoSQL数据库(键值存储)的可能性。您可以使用文件系统作为数据存储,然后使用Git添加和Git Commit以保存文件:
#保存文档回声' {" id&#34 ;: 1,"姓名&#34 ;:" kenneth"}' > 1.JSON GIT添加1.json git commit -m"添加了一个文件" #阅读文档git show master:1.json => {" id&#34 ;: 1,"姓名&#34 ;:" kenneth"}
这是有效的,但您现在使用文件系统作为数据库:路径是键,值是您存储的任何内容。有一些缺点:
我们需要在将它们保存到Git之前将所有数据写入磁盘
文件存储不是重复数据删除的,我们丢失了福利Git为我们提供了自动数据重复数据删除
如果我们想同时在多个分支机构上工作,我们需要多个检查的目录
我们想要的是什么是一个裸露的存储库,文件系统中没有文件中都存在的裸帐,但仅在git数据库中。让我们来看看Git的数据模型和管道命令来制作这项工作。
git是一个*内容可寻址的文件系统*。这意味着它是一个简单的键值存储。每当您将内容插入其中时,它会让您回到稍后检索该内容的键。让我们创建一些内容:
#Initialize一个存储库Mkdir myRepo CD MyRepo Git Init#保存一些内容回声{" ID":1,"名称&#34 ;:" kenneth"} | git hash-object -w --stdin da95f8264a0ffe3df10e94eed6371ea83aee9a4d
哈希对象是一个git管道命令,它占用内容,存储在数据库中并返回键
- W Switch告诉它来存储内容,否则它将计算哈希。 --stdin switch告诉git从输入中读取内容,而不是文件。
返回的键是基于内容的SHA-1。如果您在计算机上运行上述命令,您将看到它返回完全相同的SHA-1。现在我们在数据库中有一些内容,我们可以读回来:
只有一个问题:我们无法更新此问题,因为如果我们更新内容,则键将更改。这意味着对于我们的每个版本,我们必须记住不同的键。我们想要的是,要指定我们可以使用的键来跟踪版本。
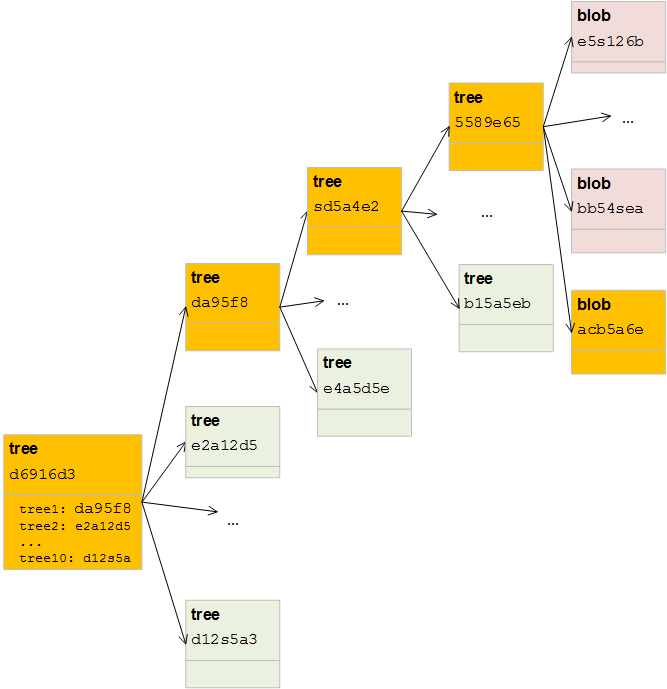
考虑树的最佳方式就像文件系统中的文件夹。要创建树,您必须遵循两个步骤:
#创建和填充暂存区域git更新 - index --add --dd --cacheinfo 100644 da95f8264a0ffe3df10e94eed6371Aea83aee9a4d 1.json #writy树git写树d6916d3e27baa9011a1
#添加一个blob echo {" id&#34 ;: 1,"姓名&#34 ;:"肯尼斯特鲁耶斯"} | git的哈希对象-w --stdin 42d0d209ecf70a96666f5a4c8ed97f3fd2b75dda#创建并填充暂存区的git更新索引--add --cacheinfo 100644 42d0d209ecf70a96666f5a4c8ed97f3fd2b75dda 1.json#写树的git写树2c59068b29c38db26eda42def74b7142de392212
我们现在有两棵树木,代表我们文件的不同状态。这没有多大帮助,因为我们仍然需要记住树的SHA-1值来达到我们的内容。
一个级别,我们得到提交。提交持有5件关键信息:
一个或多个以前的提交(现在我们只考虑仅用单个父级的提交,与多个父母的提交是合并提交)。
#提交第一棵树(没有父母)echo"提交第1版" | git comput-tree d6916d3 05c1cec5685bbbb84e806886dba0de5e2f120ab2a#用第一个提交作为父echo&#34的第二棵树;提交第2版" | Git Comput-Tree 2C59068 -P 05C1CEC5 9918E46DFC4241F0782265285970A7C16BF499E4
现在我们建立了我们文件的完整历史记录。您可以使用任何Git客户端打开存储库,您将看到正确跟踪json。要演示,这是运行Git日志的输出:
git log --stat 9918e46 9918e46dfc4241f0782265285970a7c16bf490a7c16bf490a7c16bf499e4"提交第2版" 1.json | 1 + 1文件已更改,1个插入(+)05C1CEC5685BBB84E806886DBA0DE5E2F120AB2A"提交第1版" 1.JSON | 1 + 1文件已更改,1插入(+)
我们仍然不在那里,因为我们必须记住上次提交的哈希。到目前为止,我们创建的所有对象都是Git的*对象数据库的一部分。 *该数据库的一个特征是它仅存储不可变的对象。一旦您编写Blob,一棵树或提交,您就不会在不更改键的情况下修改它。您也不能删除它们(至少不是直接,Git GC命令确实删除悬垂的对象)。
另一个级别,是git引用。引用不是对象数据库的一部分,它们是参考数据库的一部分,并且是可变的。有不同类型的参考文献,例如分支,标签和遥控器。它们的性质上与少数微小差异相似。暂时,让我们只考虑分支机构。分支是指向提交的指针。要创建分支,我们可以将提交的散列写入文件系统:
我们现在有一个分支大师,指向我们的第一次提交。要移动分支,我们发出以下命令:
最后,我们现在能够阅读我们的文件的当前状态:
即使我们添加了我们的文件和后续树的较新版本,也将继续工作,并且只要我们将分支指针移动到最新提交即可,即使我们添加了较新版本。
以上所有似乎是一个简单的键值存储似乎相当复杂。但是,我们可以摘要这些内容,以便客户端应用程序只需要指定分支和一个密钥。我会在不同的帖子中回到那个。目前,我想讨论使用Git作为NoSQL数据库的潜在优势和缺点。
Git在存储数据时非常有效。如前所述,由于如何计算哈希,仅存储具有相同内容的斑点。您可以通过将具有相同内容的整个文件添加到空GIT存储库中,然后检查.git文件夹的大小与磁盘上的大小一起尝试此操作。你会注意到.git文件夹相当较小。
但它不会阻止那里,Git对树木做同样的事情。如果在子树中更改文件,Git将仅创建一个新的子树,并仅引用不受影响的其他树。以下示例显示了指向具有两个子文件夹的层次结构的提交:
现在,如果我想替换Blob 4658844,Git只会替换那些改变的项目,并保持那些没有参考的项目。用不同的文件替换blob并提交更改后,图形如下所示(新对象标记为红色):
如您所见,Git仅替换必要的项目并引用已存在的项目。
虽然GIT在引用现有数据时非常有效,但是,如果每个小型修改都会导致完整的副本,我们仍然会在一段时间后获得一个巨大的存储库。为了缓解这一点,有一个自动垃圾收集过程。当git gc运行时,它会看看你的blob。它可以删除BLOB,而是将基本数据的单个副本存储在一起,以及每个版本的BLOB的Delta。这样,Git仍然可以检索每个唯一版本的斑点,但不需要多次存储数据。
您可以免费获得完全版本的系统。通过该版本传播,也可以是不删除数据的优势。我在SQL数据库中看到了这样的例子:
这是一个像这样的简单记录,但这通常不是整个故事。数据可能具有对其他数据的依赖关系(无论是外键是否是一种实现详细信息),并且当您想要恢复时,您可能无法孤立地进行机会。使用git,只需将分支指向不同的提交,以返回数据库级别的正确状态,而不是记录级别的问题。
这种做法甚至更有用:你知道它是更新的,但没有关于实际更新的信息以及以前的价值是什么。每当您更新数据时,您实际上才会删除数据并插入新数据。旧数据永远丢失。使用git,您可以在任何文件上运行git log,看看更改了什么,谁更改它,何时何种。
Git有一个丰富的工具集,您可以使用它来探索和操作您的数据。他们中的大多数都专注于代码,但这并不意味着您无法使用其他数据。以下是一种无穷详尽的工具概述,我可以提出我的思想之上。
使用git diff找到两个提交/分支/标签/ ...之间的确切变化
使用Git Bisect在由于数据的变化而停止工作时
使用git挂钩获取自动更改通知并构建全文索引,更新缓存,发布数据,...
您可以在合并后使用GITHUB上的拉请求,例如GitHub上的Like请求
因为它是一个键值存储,因此您可以获得NoSQL商店的常用优势,例如含有模式的数据库。您可以存储所需的任何内容,甚至不必是JSON。
git可以在分区网络中工作。您可以将所有内容放在USB棒上,在您未连接到网络时保存数据,然后在网上返回时按住它。我们经常在开发代码时使用的优势是相同的优势,但它可能是某些用例的救生员。
在上面的示例中,我们向文件提交了所有更改。您不一定必须这样做,您还可以将各种更改作为单一提交。这将使原子稍后会滚压更改。
长寿的事务也是可能的:您可以创建分支,对其进行多次更改,然后合并它(或丢弃它)。
使用传统数据库,通常有一点麻烦为完全备份和增量备份创建计划。由于Git已经存储了整个历史记录,因此永远不会有需要完成完整备份。此外,备份简单地执行Git推送。这些推动可以去任何地方,github,bitbucket或自主的git-server。
复制同样简单。通过使用Git挂钩,您可以在每次提交后都设置触发器以运行Git推送。例子:
您可以通过键查询......这就是关于它的。这里唯一的好消息是您可以以这样的方式在文件夹中构建数据,以便您可以通过前缀轻松获得内容,但这是关于它的。除非您想执行完整的递归搜索,否则任何其他查询都已关闭限制。这里唯一的选择是构建专门用于查询的指数。如果Stalites不担心,您可以在预定的基础上执行此操作,或者您可以使用Git Hooks在提交时立即更新索引。
只要我们编写Blob,就没有并发的问题。当我们开始编写提交和更新分支时,会出现问题。以下图表显示了两个进程同时尝试创建提交时的问题:
在上面的情况下,您可以看到,当第二个进程用其更改修改树的副本时,它实际上在过时的树上工作。当它提交树时,它将丢失第一个过程所做的更改。
同样的故事适用于移动分支头。在您提交并更新分支头的时间之间,另一个提交可能会进入。您可能会将分支头更新到错误的提交。
计数这一点的唯一方法是通过在读取当前树的副本之间锁定任何写入并更新分支的头部。
我们都知道git快速。但这是在创建分支的背景下。当暂时提交时,它实际上并不快,因为你一直在写到磁盘。我们没有注意到它,因为通常在编写代码时,我们通常不会执行每秒许多人(至少我没有)。在我的本地机器上运行一些测试后,我达到了大约110个提交/秒的限制。
在几年前,布兰登守护者在视频中展示了一些结果,他达到了大约90个/秒,似乎符合硬件前进所带来的一线。
110提交/秒足够大量的应用程序,但不是所有的应用程序。这也是我当地的开发机器的理论最大值,具有许多资源。有可能影响速度的各种因素:
通常,您希望使用大量子目录,而不是将所有文档放在同一目录中。这将使写入速度保持尽可能最大。出于此之原因是,每次创建新提交时,您必须复制树,对其进行更改,然后保存修改的树。虽然您可能认为影响大小,但实际上并非如此,因为运行Git GIT GIT将确保将其另存为Delta而不是两棵不同的树。让我们来看看一个例子:
在第一种情况下,我们有10.000个Blob存储在根目录中。当我们添加文件时,我们复制包含10.000项的树,添加一个并保存。由于树的大小,这可能是一个可能冗长的操作。
在第二种情况下,我们有4个级别的树,每个10个子树和最后一个级别的10个斑点(10 * 10 * 10 * 10 = 10.000文件):
在这种情况下,如果我们想添加一个blob,我们不需要复制整个层次结构,我们只需要复制通向BLOB的分支。以下图像显示了必须复制和修改的树木:
所以,通过使用子文件夹,而不是必须用10.000条目复制1棵树,我们现在可以用10个条目复制5棵树,这比这一点更快。您的数据越多,将越想要使用子文件夹。
如果您需要完成100多个提交/秒,您不需要能够在个人基础上滚动它们。在这种情况下,您可以在一次提交中提交多个更改。您可以同时编写blob,因此您可以将1000多个文件同时写入磁盘,然后执行1 Commit以将它们保存到存储库中。这有缺点,但如果你想要原始速度,这就是去的方式。
解决此方法的方法是将不同的后端添加到Git,它不会立即将其内容刷新到磁盘,但首先写入内存数据库,然后将其异步刷新到磁盘。实施这并不容易。当我使用libgit2sharp连接到存储库时,我尝试使用voron-beftend(它作为开源可用的解决方案,以及使用Elasticsearch的变量)。这种速度提高了一点,但你失去了能够使用任何标准Git工具检查您的数据的好处。
另一个潜在的痛点是当您将数据与不同分支机构合并时。 只要没有合并冲突,它实际上是一种相当愉快的经历,因为它可以实现很多好的场景: 从本质上讲,您可以获得您在开发的分支机构的所有乐趣,但在不同的水平。 问题是存在合并冲突。 合并数据可能相当困难,因为您将永远无法解决如何处理这些冲突。 一个潜在的策略是只要存储合并冲突就像你正在编写数据然后读取时,向用户介绍差异,所以他们可以选择哪一个是正确的。 尽管如此,它可能是一个正确的管理这一任务。 Git可以在某些情况下非常适用于NoSQL数据库。 它有它的位置和时间,但我认为它在以下情况下特别有用: 所以,你走了,这就是你如何使用Git作为NoSQL数据库的方式。 让我知道你的想法!



