一年的编译器模糊竞选活动
在2020年夏天,我们描述了我们的工作模糊巩固编译器,Solc。所以现在我们想重新审视这个项目,因为模糊运动往往会“饱和”,以时间随着时间的推移找到较少的新结果。坚固的模糊耗尽气体吗?欺骗一个高赌注项目值得的,特别是如果它有自己的积极和有效的模糊努力?
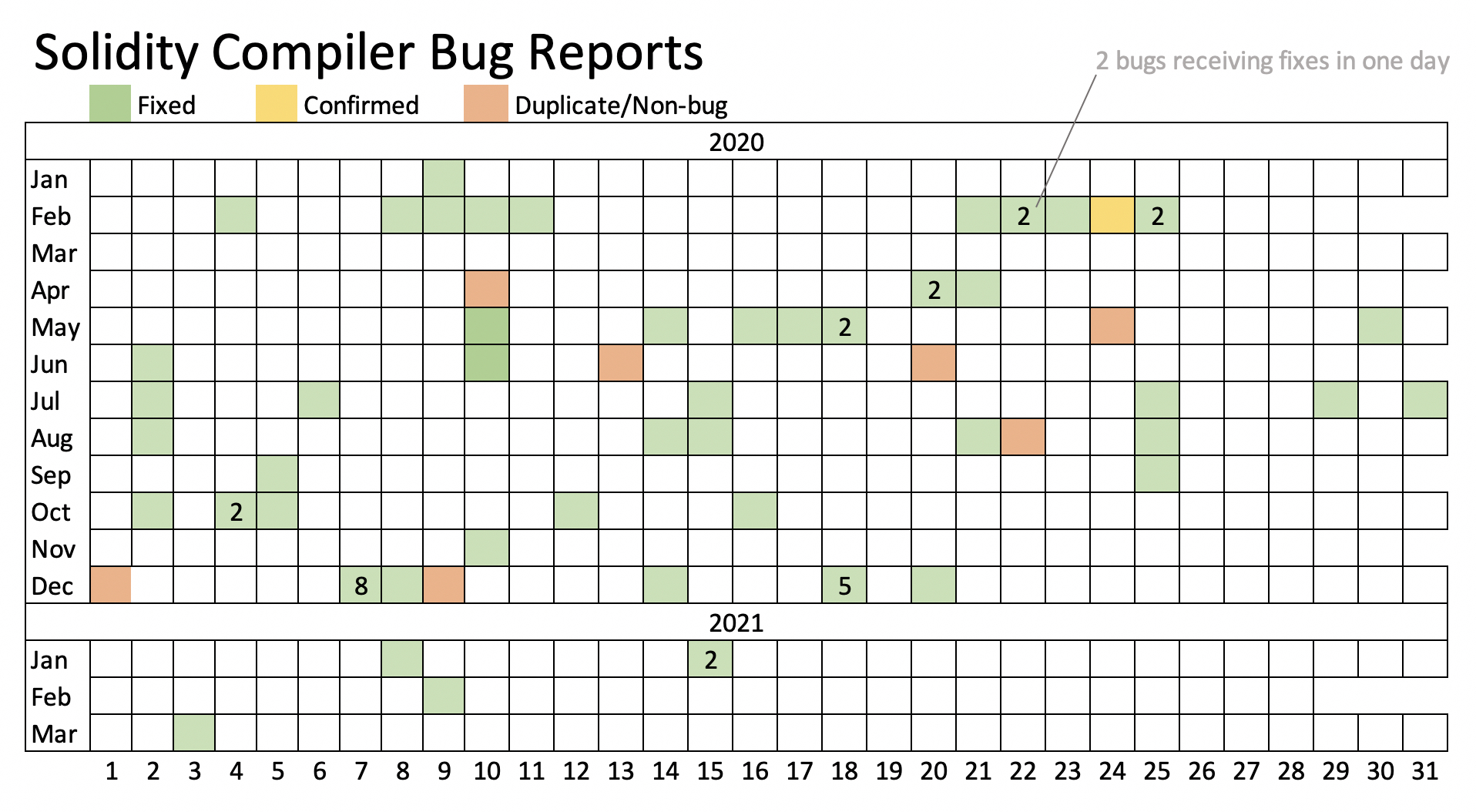
使用AFL Variant的2月20日2月份提交了该模糊运动的第一个错误。从那时起,我们已经提交了74个报告。六十七被确认为错误,66人已得到修复。七个是重复的或不被认为是真正的错误。
鉴于自去年12月以来提交了21个错误,说我们的模糊运动为为什么独立的模糊仍然重要而且可以找到不同的错误,即使也在基于OSSFuzz的测试也是如此。
为什么不确定地模糊这样的项目是有用的?答案有三个部分。首先,更具模糊涵盖更多的代码执行路径,长模常用尤为有用。在路径覆盖饱和子附近有任何我们所知道的任何模糊的地方,很难得到任何情况。即使在运行30天或更长时间时,我们的测试仍然在每1-2小时内找到新的路径,有时会找到新的边缘。我们报告的一些错误仅在一个月的模糊后被发现。
生产编译器非常复杂,因此深入模糊很有用。生成输入需要时间,例如我们发现的最新错误,我们发现的SOLC的稳定性级别:
Pragma实验SMTChecker;合同A {函数f()内部虚拟{v(); }函数v()内部虚拟{}}合同b是{function f()内部虚拟覆盖{super.f();合同C是B {函数v()内部覆盖{if(0 == 1)f(); }}
此代码应没有错误编译,但它没有。直到错误是固定的,它导致SMT检查器崩溃,抛出致命的“超合同不可用”错误,由于在分支机构内的虚拟呼叫中的可变访问权限不正确。
编译器应该在长时间的时间内进行绒毛测试,因为它们的复杂性和可能的执行路径数量。经验法则是,在达到一百万个执行之前,AFL尚未在任何非琐碎的目标上真正开始,并且编译器可能需要多大程度上。在我们的经验中,编译器运行的任何地方都会在少于一个执行每秒到每秒40个执行。刚刚获得一百万个执行可能需要几天!
我们希望独立于OSSFuzz的第二种原因是从不同的角度接近目标。而不是严格地使用传统的模糊突变运算符的基于字典或语法的方法,而是从任何语言突变测试中使用了思想,将“代码特定的”突变运算符添加到AFL,并依赖于那些(但不是完全),与AFL更通用的突变相反,这倾向于专注于二进制格式数据。做一些不同的事情可能会成为模糊饱和的良好解决方案。
最后,我们一直抓住最新的代码并开始对新版本的索尔公司进行模糊。由于OSSfuzz持续集成不包括我们的技术,因此有时会出现对其他模糊物而且易于用于我们的代码突变方法的错误,并且我们的模糊将立即找到它们。
但我们不抓住每一个新的释放并重新开始,因为我们不想失去与我们的长模糊的竞选活动获得的地面。我们也不会不断占据我们离开的地方,因为这是AFL可以生成的数万个测试Corpora可能充满了可能在新代码中发现错误的不感兴趣的路径。我们有时会从现有的运行中恢复,但不常。
在Solc这样的严重模糊程序中找到错误并不容易。索尔曼团队在OSSFuzz窗口帖子中的索尔姆·米特罗斯的下一个最佳独立的模糊努力,也提到了Solc队伍,只会发现了8个错误,即使它自2019年10月以来一直在进行中。
我们的成功与Solc启发了我们欺骗其他编译器。首先,我们尝试模糊vyper编译器 - 一种旨在提供更安全,python的替代方面的语言,以稳定地编写国内区块链智能合同。我们以前的Vyper模糊通过Python-AFL使用基本上使用基于语法的方法使用基于语法的方法的一些有趣的错误。我们在这个广告系列中找到了一些错误,但选择不去极端,因为仪表般的Python测试的速度和吞吐量差。
相比之下,我的合作师Rijnard Van Tonder在SourceGraph中,迪姆项目的移动语言更加壮大 - 被称为Facebook的Libra的区块链的语言。在这里,编译器很快,仪器便宜。 Rijnard在编译器中报告了14个错误,到目前为止,所有这些都已确认和分配,其中11个已被修复。鉴于这只是两个月前开始的模糊,这是一个令人印象深刻的虫子!
使用RIJNARD关于使用AFL.RS模糊锈蚀码的注释,我尝试了我们的工具,以Ethereum基金会支持的新智能合同语言。在某种意义上,FE是vyper的继承者,但是从生锈和更快的编译器中有更多的灵感。我在第一个alpha发布之日开始模糊FE,并在九天后提交了我的第一个问题。
为了支持我的模糊运动,FE团队在YUL后端改变了失败,它使用SOLC编译YUL,以产生AFL可见的生锈恐慌,我们已离开赛道。到目前为止,这项努力已经产生了31个问题,占FE的所有GitHub问题的18%以上,包括特征请求。其中,14已经被证实为虫子,其中十是固定的;剩下的错误仍在审查中。
我们不仅仅是Fuzz Smart合同语言。 RIJNARD模糊了ZIG编译器 - 一种新的系统编程语言,旨在简单和透明度,并发现两个错误(确认,但不固定)。
我们发现在我们的AFL编译器模糊运动期间修复的88个错误,以及另外14个确认,但尚未修复错误。
有趣的是,模糊不使用词典或语法。他们对超出了来自测试用例的示例程序的适度语料库表达的任何语言的任何语言都不了解。那么我们如何有效地模仿编译器?
模糊物以常规表达水平运行。它们甚至没有使用无背景语言信息。大多数模糊都使用了基于快速的C字符串的启发式方法来使“代码类似”更改,例如递除括号,更改算术或逻辑运算符之间的代码,或者只是交换代码线,以及更改为陈述和删除函数参数。换句话说,他们应用这种改变的类型突变测试工具。即使Vyper和Fe不是非常的C形,刚刚的空格,逗号和括号使用,也可以很好地运作良好。
自定义词典和语言感知突变规则可能更有效,但目标是提供具有有效模糊的编译项目,而无需许多资源。与FE语言一样,我们还希望看到良好的模糊策略在项目期间可以对项目的影响。我们已经报告的一些错误突出显示的开发人员的棘手的角落案例早比可能是否则的情况。我们希望这一讨论,例如这一讨论将有助于生产更强大的语言和编译器,而且具有更少的黑客,以适应设计缺陷检测到的,以便轻松改变。
我们计划自从SOLC努力表明,长时间的模糊运动可以保持可行的模糊运动,即使还针对相同的编译器的其他模糊努力,我们都可以继续模糊这些编译器。
编译器很复杂,大多数也在迅速变化。例如,FE是一种不完全全新的全新语言,并且众所周知,对用户面向用户的语法和编译内部的剧烈更改众所周知。
我们还与Bhargava Shastry交谈,他领导着坚固的内部模糊努力,并应用了一些语义检查,他们在他们自己的Protobuf-fuzzing中应用了它们。我们通过Solc的严格组装选项开始直接模糊yul,我们已经发现了一个有趣的错误,这是快速修复和煽动了相当多的讨论!我们希望能够找到不仅仅是仅仅输入崩溃索尔科将把这种模糊的输入达到下一级别。
大大问题是由于编译器无法检测到许多错误代码错误,模糊都限制了它可以找到的错误。在关闭优化时,两个编译器或编译器的差异比较,并且在优化时的输出,通常需要更多的程序的限制形式,这限制了所发现的错误,因为必须编译和执行程序以比较结果以比较结果。
解决这个问题的一种方法是使编译器更频繁地崩溃。我们想象一个编译器包括像测试选项的内容的世界,这使得能够在正常运行中不能实际的攻击性和昂贵的检查,例如在寄存器分配上的Sanity-Checks。虽然这些检查可能太昂贵,但对于正常运行可能是过于昂贵的,但它们可以打开一些模糊运行,因为编译的节目通常很小,并且甚至更重要的是,在最终的批判代码中的最终生产汇编中(Mars Rover Code ,核 - 反应堆控制代码或高价值智能合同),以确保没有错误代码错误蠕动到这样的系统中。
最后,我们希望教育将源代码作为输入的源代码的其他工具的编译器开发人员和开发人员,这种有效的模糊不一定是需要显着开发人员时间的高成本工作。查找编译器的崩溃输入通常很容易,只使用了一些备用CPU周期,语言中的一组体面的源代码示例,以及AFL-Compiler-fuzzer工具!
我们希望您喜欢了解我们的长期编译器模糊项目,我们喜欢听到您在Twitter @trailofbits上的虚拟体验。