NoSQL数据建模技术
NoSQL数据库通常由各种非功能标准进行比较,例如可伸缩性,性能和一致性。在实践和理论中,NoSQL的这一方面在实践和理论中都是很好地研究,因为特定的非功能性质通常是NoSQL使用和基本结果的主要理由,就像帽定理一样适用于NoSQL系统。与此同时,NoSQL数据建模并不是很好地研究,并且缺乏在关系数据库中发现的系统理论。在本文中,我提供了从数据建模的数据建模和摘要几个常见建模技术中的NoSQL系统系列的短暂比较。
我要感谢Daniel Kirkdorffer审查了这篇文章并清理了语法。
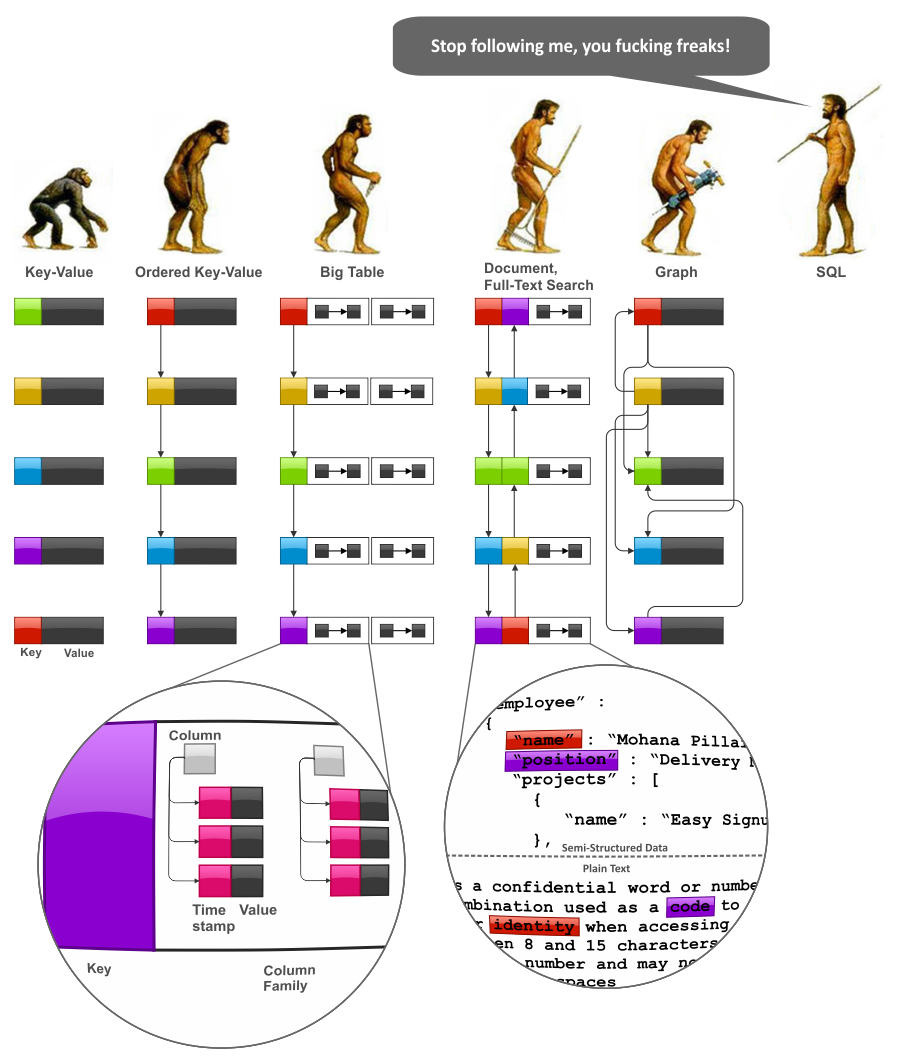
为了探索数据建模技术,我们必须从一个或多或少地系统的NoSQL数据模型视图开始,优选地揭示趋势和互连。下图描绘了主要的NoSQL系统系列的虚构的“演变”,即键值存储,BigTable样式数据库,文档数据库,全文搜索引擎和图形数据库:
首先,我们应该注意,SQL和关系模型通常是长时间设计的,以与最终用户进行交互。这种面向用户的大自然具有巨大影响:
最终用户通常对聚合报告信息感兴趣,而不是在单独的数据项中,并且SQL对此方面有很大的注意。
没有人可以预期人类用户明确控制并发,完整性,一致性或数据类型有效性。这就是为什么SQL对事务担保,模式和参照完整性付出很多人关注。
另一方面,它证明了软件应用程序通常对数据库内聚合并能够控制,至少在许多情况下,完整性和有效性本身都有感兴趣。除此之外,消除这些功能对商店的性能和可扩展性具有极大的影响。这是数据模型的新演变开始的地方:
钥匙值存储是一种非常简单,但非常强大的模型。以下描述的许多技术完全适用于该模型。
关键值模型最重要的缺点之一是对需要处理关键范围的情况的适用性差。订购的键值模型克服了这个限制,显着提高了聚合能力。
订购的键值模型非常强大,但它没有提供任何框架的值建模。通常,值建模可以通过应用程序完成,但是大型式数据库可以进一步完成,并将值作为映射地图,即列,列族,列和时间戳版本。
文档数据库推出了两种重大改进的BIGTABLE模型。第一个是具有任意复杂性方案的值,而不仅仅是映射地图。第二个是数据库管理的索引,至少在一些实现中。完整文本搜索引擎可以被视为一个有关的物种,以至于它们还提供灵活的架构和自动索引。主要区别在于,文件数据库组索引由字段名称,而不是搜索引擎,该引擎由字段值组索引。还值得注意的是,Oracle Cherce等一些键值存储通过添加索引和数据库内输入处理器逐渐转向文档数据库。
最后,图数据模型可以被视为从有序键值模型起源的侧面分支。图表数据库允许一个模型业务实体非常透明地(这取决于此),但分层建模技术也使其他数据模型在该区域中非常竞争。图形数据库与文档数据库有关,因为许多实现允许将一个型号为映射或文档。
本文的其余部分介绍了具体数据建模技术和模式。作为序言,我想提供关于NoSQL数据建模的一些概要说明:
NoSQL数据建模通常从应用程序特定的查询开始,而不是关系建模:关系建模通常由可用数据的结构驱动。主要设计主题是“我有什么答案?”
NoSQL数据建模通常由特定于应用程序的访问模式驱动,即要支持的查询类型。主要设计主题是“我有什么问题?”
NoSQL数据建模通常需要更深入地了解数据结构和算法,而不是关系数据库建模。在本文中,我描述了几种没有特定于NoSQL的众所周知的数据结构,但在实用的NoSQL建模中非常有用。
关系数据库不是非常方便的层次结构或图形数据建模和处理。图表数据库显然是这个领域的完美解决方案,但实际上大多数NoSQL解决方案对于此类问题令人惊讶地强大。这就是当前文章将单独的部分分离到分层数据建模的原因。
虽然数据建模技术基本上是实现不可知论,但这是我在研究本文时所遇到的特定系统的列表:
DeNormalization可以定义为将相同数据复制到多个文档或表中,以便简化/优化查询处理或将用户的数据拟合到特定数据模型中。本文中描述的大多数技术利用了一种或另一种形式的非正规化。
查询数据卷或每个查询的IO与总数据卷。使用DeMormAlization可以将所有数据组分组在一个地方处理查询所需的数据。这通常意味着对于不同的查询流,将以不同的组合访问相同的数据。因此,我们需要重复数据,这增加了总数据量。
处理复杂度与总数据卷。建模 - 时间归一化和随后的查询时间加入显然提高了查询处理器的复杂性,尤其是分布式系统。 Denormalization允许一个存储在查询友好结构中的数据以简化查询处理。
键值存储和图形数据库通常不会在值上放置约束,因此值可以包含任意格式。还可以通过使用复合键来改变一个商业实体的多个记录。例如,用户帐户可以用userid_name,userid_email,userid_messid_messidage等组合为一组与复合键的条目建模。如果用户没有电子邮件或消息,则不会记录相应的条目。
Bigtable模型通过列族内的变量一组列支持软架构,以及一个单元格的可变版本。
文档数据库本质上是概要的,尽管其中一些允许使用用户定义的架构验证传入数据。
软架构允许其中一个组成具有复杂内部结构(嵌套实体)的实体类,并改变特定实体的结构。这功能提供了两个主要设施:
使用一系列文件或一张表掩盖业务实体与异构企业实体建模之间的“技术”差异。
这些设施如下图所示。该图描绘了电子商务业务域的产品实体的建模。最初,我们可以说所有产品都有ID,价格和描述。接下来,我们发现不同类型的产品具有不同的属性,如牛仔裤的书籍或长度。其中一些属性有一个多对多或多对多的性质,如音乐专辑中的曲目。接下来,可能无法使用固定类型建模某些实体。例如,牛仔裤属性在品牌上并不一致,并且对每个制造商特定。可以在关系规范化数据模型中克服所有这些问题,但解决方案远非优雅。软架构允许人们使用单个聚合(产品),可以模拟所有类型的产品及其属性:
嵌入Denormalization可以极大地影响性能和一致性的更新,因此应特别注意更新流程。
NoSQL解决方案很少支持联合。由于“面向问题的”NoSQL性质,Joins通常在设计时处理,而不是在查询执行时间处理连接的关系模型。查询时间连接几乎总是意味着性能损失,但在许多情况下,可以避免使用DeNormalization和聚合,即嵌入嵌套实体。当然,在许多情况下,加入是不可避免的,应该由申请处理。主要用例是:
当实体内部是频繁修改的主题时,聚合通常不可应用。通常更好地保留事件发生的记录并在查询时间下加入记录,而不是更改值。例如,消息传递系统可以被建模为包含嵌套消息实体的用户实体。但是,如果往往附加消息,则可以更好地将消息作为独立实体提取,并在查询时间将其加入用户:
在本节中,我们讨论适用于各种NoSQL实现的一般建模技术。
许多人,虽然不是全部,NoSQL Solutions的交易支持有限。在某些情况下,人们可以使用分布式锁或应用程序管理的MVCC来实现交易行为,但是使用聚合技术模拟数据以保证一些酸性。
强大的交易机械是关系数据库的不可避免部分的原因之一是归一化数据通常需要多个地点更新。另一方面,聚合允许将单个业务实体存储为一个文档,行或键值对并原子更新:
当然,作为数据建模技术的原子聚集体不是完整的事务解决方案,但如果商店提供某些保证的原子性,锁定或测试和设置的指令,则可以适用原子聚集体。
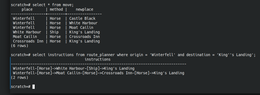
也许无序键值数据模型的最大益处是,只需散列密钥即可通过多个服务器划分条目。排序使事情变得更加复杂,但有时应用程序即使存储不提供这样的功能也能够采取某些优点。让我们考虑电子邮件的建模作为示例:
一些NoSQL存储提供原子计数器,允许一个生成顺序ID。在这种情况下,可以使用userid_messageid作为复合密钥存储消息。如果已知最新消息ID,则可以遍历先前的消息。对于任何给定的消息ID,也可以遍历前面和后续消息。
消息可以分组为桶,例如,每日存储桶。这允许一个人从任何指定的日期或当前日期开始向后或向前遍历邮箱。
减少维度是一种允许人们将多维数据映射到键值模型或其他非多维模型的技术。
传统地理信息系统使用四叉树或R树的一些变体进行索引。这些结构需要更新,并且当数据量大时,可以操纵昂贵。替代方法是遍历2D结构并将其平坦化为纯粹的条目列表。本技术的一个众所周知的例子是岩石。 Geohash使用z样扫描来填充2D空间,并且每个移动根据方向编码为0或1。经度和纬度移动的比特是交错的以及移动。编码过程在下图中示出,其中黑色和红色位分别用于经度和纬度:
Geohash的一个重要特征是它能够使用位方面的代码接近区域估计区域之间的距离,如图所示。 Geohash编码允许使用普通数据模型存储地理信息,例如保留空间关系的排序键值。 [6.1]中描述了Bigtable的维数减少技术。有关地磁和其他相关技术的更多信息,请参见[6.2]和[6.3]。
索引表是一种非常简单的技术,允许一个人利用在内部不支持索引的商店中的索引。这些商店中最重要的类别是BigTable风格的数据库。该想法是创建和维护一个特殊的表,其中包含遵循访问模式的键。例如,有一个主表,用于存储可以由用户ID访问的用户帐户。可以通过额外的表来支持检索指定城市所有用户的查询,其中City是一个键的额外表:
可以为主表或批处理模式更新索引表。无论哪种方式,它会导致额外的性能惩罚并成为一致性问题。
复合键是一种非常通用的技术,但是当使用有序密钥的商店时,它是非常有益的。复合键与二级排序结合允许一个人构建一种多维指标,它基本上类似于先前描述的维度减少技术。例如,让我们拍一组记录,每个记录是用户统计信息。如果我们将通过用户来自的区域聚合这些统计信息,我们可以使用格式(状态:城市:userid)使用键,该键允许我们迭代特定状态或城市的记录,如果该商店支持选择钥匙范围由部分关键匹配(作为Bigtable-Signd Systems):
复合键不仅可以用于索引,而是用于不同类型的分组。让我们考虑一个例子。有一个大量的日志记录,其中包含有关Internet用户的信息及其来自不同站点的访问(单击流)。目标是计算每个站点的唯一用户的数量。这类似于以下SQL查询:
该想法是保留一个用户并源的所有记录,因此可以将这种帧提取到内存中(一个用户不能产生太多事件)并使用哈希表或其他任何用户消除站点复制品。当事件到达时,替代技术是将一个用户的一个条目和将站点附加到该条目。尽管如此,进入修改通常比大多数实现中的进入插入效率低。
该技术更像是数据处理模式,而不是数据建模。然而,数据模型也受到这种模式的使用影响。此技术的主要思想是使用索引来查找符合标准的数据,但使用原始表示或全扫描聚合数据。让我们考虑一个例子。有许多日志记录具有有关Internet用户的信息及其来自不同站点的访问(单击流)。假设每个记录包含用户ID,该用户属于(男性,女性,博主等),城市这个用户来自和访问的网站。目标是描述在本次受众中发生的每个类别的唯一用户(即,在符合标准的用户集中)的唯一用户,符合某些标准(网站,城市等)。
很明显,使用像{类别 - &gt等{类别 - &gt这样的反相索引可以有效地完成符合标准的用户搜索[用户IDS]}或{site - > [用户IDS]}。使用这种索引,可以相交或统一相应的用户ID(如果用户ID被存储为排序列表或比特集)并获得受众,则可以非常有效地完成。但是描述了类似于聚合查询的受众
如果类别数量大,则无法使用反相索引有效处理。要应对这一点,可以构建形式的直接索引{userid - > [类别]}并迭代它才能建立最终报告。此模式如下所示:
作为最终说明,我们应该考虑到观众中每个用户ID的记录随机检索可能效率低。可以通过利用批处理查询处理来掌握此问题。这意味着可以预先计算一些用户集(对于不同的标准),并且可以在直接或逆索引的一个全扫描中计算本批次的所有报告。
树木甚至是任意图(借助非正式化)可以被建模为单个记录或文档。
当一次访问树时,此技术是有效的(例如,获取整个博客评论的整个树以显示具有帖子的页面)。
邻接列表是图形建模的直接方式 - 每个节点都被建模为独立的记录,其中包含直接祖先或后代的数组。它允许人们通过父母或儿童的标识来搜索节点,当然,当然,通过每查询执行一跳来遍历图形。对于给定节点的整个子树,这种方法通常是低效的,用于深层或宽遍历。
物化路径是一种有助于避免树状结构的递归遍历的技术。这种技术可以被认为是一种非正规化。该想法是通过其所有父母或儿童的标识符来归因于每个节点,因此可以在没有遍历的情况下确定节点的所有后代或前辈:
这种技术对全文搜索引擎特别有帮助,因为它允许其中将分层结构转换为平面文档。一个人可以在上图中看到,可以使用简称为类别名称的短查询来检索男鞋类别中的所有产品或子类别。
物化路径可以存储为一组ID或作为单个连接ID串。后一个选项允许一个人搜索使用正则表达式遇到某个部分路径标准的节点。此选项如下图所示(路径包括节点本身):
嵌套集是一种用于建模树状结构的标准技术。它广泛用于关系数据库,但它完全适用于键值存储和文档数据库。该想法是将树的叶子存储在阵列中并使用开始和结束索引将每个非叶节点映射到一系列叶片,如下图所示:
这种结构对于不可变数据非常有效,因为它具有小的内存占用空间,并且允许一个在没有遍历的情况下为给定节点获取所有叶子。然而,插入和更新是非常昂贵的,因为添加一个叶子会导致索引的大量更新。
搜索引擎通常使用平面文档,即,每个文档都是字段和值的平面列表。数据建模的目标是将业务实体映射到纯文档,如果实体具有复杂的内部结构,这可能是具有挑战性的。一个典型的挑战映射具有层次结构的文档,即内部具有嵌套文档的文档。让我们考虑以下例子:
每个企业实体都是某种简历。它包含一个人的姓名和他或她的技能列表,技能水平。一种模拟此类实体的显而易见的方法是使用技能和级别字段创建纯文档。该模型允许一个人通过技能或级别搜索人,但是将两个字段组合的查询易于导致假匹配,如上图所示。
在[4.6]中提出了一种克服这个问题的方法。这种技术的主要思想是将每个技能和对应级别索引为专用对字段skill_i和level_i,并同时搜索所有这些对(查询中的术语数量高达最大值一个人的技能数量):
这种方法并不是可以扩展,因为查询复杂性随着函数而迅速增长
......