如何阅读着色器组件
当我开始图形编程时,像HLSL和GLSL这样的着色语言在游戏开发中尚未流行,并在装配中直接开发着色器。当介绍HLSL时,我记得我们尝试乐趣,通过手工制作更短,更紧凑的汇编代码来击败编译器,这不是那么难的东西。从那时起,Shader编译器技术已经完全进展,在现在,在大多数情况下,它很难通过手工制作更好的装配码(也是着色器已经变得如此大而复杂的是,无论如何都没有成本效益)。
尽管现在没有人直接在组装中写入着色器,但是对于能够读取和理解编译器生成的着色器组件(ISA)代码仍然有用。首先,它有助于一个了解编译器如何解释高级着色器指令。某些指令,例如TAN()或整数划分不会直接映射到硬件,并可以扩展到许多装配说明中。其次,它可以帮助了解GPU的工作原理,如何请求数据,执行分支,写入输出等。第三,它可以帮助着色器调试当实际着色器代码不可用时。虽然我们通常不再使用调整着色器组装,但了解它可以帮助我们做出更好的高级着色器创作决策,这可能导致更高的性能汇编代码。最后,对于我个人而言,它是相当于有时读取没有抽象层的代码的宣告,清楚地了解它尽可能靠近金属。
在此博客文章中,我们将讨论着色器组件一点并提供一些指针如何阅读它。该讨论主要集中在DirectX和HLSL上,类似的想法适用于其他API /着色语言。同样在我使用AMD的着色器组件(ISA)的示例中,因为它可以很好地记录并且易于使用像优秀的着色器游乐场等工具,即使一个人无法访问AMD GPU。
在我们开始之前,值得一提的是,着色器编译在2个阶段完成:首先是FXC或DXC等工具,将HLSL代码编译为称为中间语言(IL)的GPU无人物格式。然后GPU驱动程序将IL转换为可以在特定GPU上执行的最终着色器组件(ISA)。我们将重点关注ISA,而不是在IL上,因为它更具代表性的代表实际执行。在以下示例中,将两个数字乘以两个数字的HLSL着色器在右侧的IL代码和ISA代码中产生。 IL代码仍然比较高,并隐藏了很多实现细节。
S_MOV_B32 M0,S8 S_BUFFER_LOAD_DWORDX4 S [0:3],S [4:7],0x00 V_INTERP_P1_F32 V2,V0,attr0.x v_interp_p2_f32 v2,v1,attr0.x v_interp_p1_f32 v3,v0,attr0.y v_interp_p2_f32 v3,v1,attr0 .y v_interp_p1_f32 v4,v0,attr0.z v_interp_p2_f32 v4,v1,attr0.zv_interp_p1_f32 v0,v0,attr0.wv_interp_p2_f32 v0,v1,attr0.w s_waitcnt lgkmnt(0)v_mul_f32 v1,s0,v2 v_mul_f32 v2,s1, V3 v_mul_f32 v3,s2,v4 v_mul_f32 v0,s3,v0 v_cvt_pkrtz_f16_f32 v1,v1,v2 v_cvt_pkrtz_f16_f32 v0,v3,v0 exp mrt0,v1,v1,v0,v0完成了VM S_ENDPGM结束
让我们考虑这个虚构的HLSL着色器。虽然它没有做任何有用的事情,但它使用了许多语言功能,虽然是一个在更现实的方案中使用的语言功能,如属性插值,常量缓冲区,纹理读取,数学操作和分支:
这是它产生的着色器组装,它使用Radeon GPU分析仪定位AMD的GCN GPU架构:
乍一看,它看起来像是一系列的隐秘指令和数字,但是让我们先尝试两个着色器之间的彩色代码相应的区域,以获得HLSL如何转化为装配的粗略感觉。
float4 psmain(psInput输入):sv_target {float4结果= tex.sample(Samplerlinear,Input.uv);浮动因子= data.x * data.y; if(因子> 0)返回data.z *结果;否则返回data.w *结果; }
S_MOV_B32 M0,S20 S_MOV_B64 S [22:23],EXEC S_WQM_B64 EXEC,EXEC v_interp_p1_f32 v2,v0,attr0.x v_interp_p2_f32 v2,v1,attr0.x v_interp_p1_f32 v3,v0,attr0.y v_interp_p2_f32 v3,v1,attr0.y s_and_b64 EXEC,EXEC,S [22:23] IMAGE_SAMPLE V [0:3],V [2:4],S [4:11],S [12:15] DMASK:0xF S_BUFFER_LOAD_DWORDX4 S [0:3],S [16:19],0x00 S_WAITCNT LGKMCNT(0)V_MOV_B32 V4,S1 V_MUL_F32 V4,S0,V4 V_CMP_LT_F32 VCC,0,V4 S_CBRANCH_VCCZ标签_0017 S_WAITCNT VMCNT(0)V_MUL_F32 V0,S2,V0 V_MUL_F32 V1,S2,V1 V_MUL_F32 V2, S2,V2 V_MUL_F32 V3,S2,V3 S_BRANCH标签_001C LABET_0017:S_WAITCNT VMCNT(0)V_MUL_F32 V0,S3,V0 V_MUL_F32 V1,S3,V1 V_MUL_F32 V2,S3,V2 V_MUL_F32 V3,S3,V3 LABED_001C:S_MOV_B64 EXEC,S [22 :23] v_cvt_pkrtz_f16_f32 v0,v0,v1 v_cvt_pkrtz_f16_f32 v1,v2,v3 exp mrt0,v0,v0,v1,v1完成了vm s_endpgm结束
uncolourted部分对应于代码GPU必须执行以设置突出显示的主要指令。
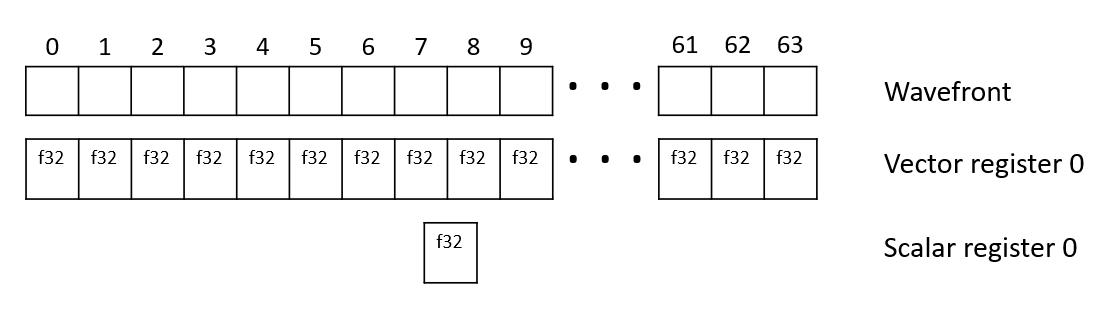
在我们开始深入挖掘代码之前,一些值得讨论的事情。首先,我们注意到几乎所有指令都以前缀v_或前缀s_,例如v_mul_f32和s_mov_b32开始。这为我们提供了一些关于硬件本身的信息:GCN架构批量批量为64,称为Wavefronts的工作项(像素,顶点等),并并行执行每个着色器指令,无论是对每个线程唯一的数据运行(使用对所有线程共用的V_前缀,矢量)或数据共用(SCALAR的S_前缀)。值得一提的是工作项目也经常被称为“线程”。将像素的颜色乘以值是使用每个线程唯一的数据的操作,因此GPU将使用矢量指令。从常量缓冲区读取值使用所有线程共用的数据,因此GPU将使用标量指令。
这是一个很好的机会,还简要讨论寄存器的类型矢量和标量指令的操作。上面列出的着色器代码用载体(Vxx)和标量(SXX)寄存器,例如v_mul_f32 v1,s3,v1。寄存在本地存储数据,即在操作中使用着色器指令。向量寄存器存储每个波前螺纹的32位数量(总共64个),标量寄存器存储所有线程共用的32位数量。我尝试了一个图表展示了64个线程波前以及矢量和标量寄存器如何映射到它来帮助澄清这一点。
上面提到的MUL指令将与所有线程,共同的所有线程,S3标量寄存器值乘以每个线程V1向量寄存器值,并将结果存储在V1向量寄存器中。有时寄存器指数以括号呈现为例如S [22:23]。这表示可用于存储大于32位的数量的寄存器范围(在该示例中的标量寄存器22和23。
最后,值得注意的是,每个指令都指示数据类型是开启的。例如,v_mul _f32在32位浮点数上操作,v_mov _b32“副本”32位(非款待)寄存器之间的数量,v_cvt_pkrtz _f16_f32将32位浮点数转换为16位。这对于了解每个指令使用的数据类型和大小(16,32,64位)是有用的。
通过该信息,让我们开始一次解码装配汇编代码一块。
着色器从某些设置代码开始。由于我们将在进行一些插值后,编译器将M0寄存器(每个波前,32位)与本地数据存储(LDS)偏移到插值数据(在这种情况下每个顶点UV坐标)。接下来,它将EXEC寄存器的副本到标量寄存器22和23。因为该寄存器对所有波前线程常见,所以使用标量(S_)指令。此外,这是组合寄存器来存储值较大的寄存器的一个很好的例子。最后,执行S_WQM_B64指令,以确定波前中的哪个线程属于活动像素四边形。像素着色器始终在2×2像素的组上运行。如果Quad中的像素处于活动状态,这意味着它覆盖三角形,则Quad中的所有像素将被标记为活动状态。这样做是为了允许GPU确定哪些四边形是有效的衍生计算。
下一段代码段通过本地数据存储器(LDS)存储器插入由顶点着色器提供的FLOAT2 UV坐标,使用上面M0寄存器中存储的偏移量。在这种情况下,我们使用矢量指令(前缀v_),因为每个线程(像素)都有自己的UV值。我们注意到每个UV.X和UV.Y组件的插值都是在两个步骤P1和P2,每个组件的两个指令中完成。在这两个步骤中,GPU读取3个UV分量值,每个顶点一个,以及2个重心坐标,并插入最终值。这为我们提供了另一种关于GPU硬件的知识,即在着色器中发生插值,并且没有专用硬件。 UV坐标现在存储在向量寄存器V2和V3中。
此指令更新所有波前线程的执行掩码。如果一个线程不属于活动像素Quad,则它会停用。
这是纹理样本指令。 _Sample Postfix意味着该操作还可以通过Samplertate对象过滤数据,这是示例使用中的HLSL代码。第一个向量寄存器范围V [0:3]表示将用于存储结果的4寄存器(V0-V3,4浮点值),V [2:4]范围包含上述内插的UV坐标(v2和v3),标量寄存器范围[4:11]包含用于存储纹理描述符的8个寄存器(它指向纹理的内存地址),另一个标量范围[12:15]包含4个寄存器用于存储用于过滤纹理样本的采样器对象的描述符(内存地址)(HLSL着色器中定义的Samplertate对象)。最终的DMASK(4位数据掩码)操作数指定纹理读取应该处理的组件数量。 0xF的值指定所有4个组件。即使它没有v_前缀,image_sample也是向量指令。
接下来,我们需要从常量缓冲区读取常量数据以将纹理颜色乘以。从恒定缓冲区读取是所有波前线程共有的标量操作,因此发出S_BUFFER_LOAD_DWORDX4。第一个标标量指定用于存储负载结果的标量寄存器(S0-S3,4 FP32值),第二范围指定恒定缓冲区的描述符(指向它存储的存储器地址)。所有内存负载都具有延迟,这意味着它需要多个时钟周期(潜在大)从带有S_buffer_load和返回的值可以在后续v_mov_b32指令中使用时,因此着色器编译器添加了一个S_WAITCNT指令在两者之间会停止,如果数据未准备好用于使用。等待指令中的LGKMCNT参数表示指令等待常常缓冲区(或本地/全局数据存储)读取返回。一旦数据在这里,着色器就会发出移动指令,将S1的值复制到V4寄存器,然后将v_mul指令与s0寄存器乘以(有效地实现浮动因子= data.x * data.y hlsl指令。
此代码公开了关于硬件的另一个信息,即不支持标量值的直接乘法,必须首先将两个中的一个复制到向量寄存器。这对于所有数据类型都是如此?显然不是,如果我将常量缓冲区数据更改为UINT4而不是float4,那么着色器将发出一个整数乘法指令s_mul_i32,以直接乘以两个标量值:
现在,着色器具有v4中乘法的结果,它可以执行v_cmp_lt_f32指令,以确定它是否小于零。该指令设置矢量条件代码寄存器(VCC,1表示通过的线程,0失败了比较)。请记住,虽然它是矢量比较(即每个线程的不同一个),但V4包含所有线程的相同值,因此结果将对所有线程相同。如果存储在VCC中的比较结果为零(S_CBRANCH_VCCZ),这意味着“小于”比较失败,则着色器将跳过以下代码的分支并继续从LABEL_0017执行。
另一点关于硬件的洞察力也是如此。虽然“比较”指令是矢量(以不同方式处理波前的每个线程),但实际的分支指令是标量,即所有线程都是相同的。在GCN上,对于所有类型的分支机构来说,它们是由标量单元处理的。此外,在这种情况下,分支是全部或全部,所有线程的因子编码值小于零或大于零,因为编译器知道该值源自标量,并且对所有线程都是相同的没有分歧。如果我将比较值更改为每个线程的变化:
float4 psmain(psInput输入):sv_target {float4结果= tex.sample(Samplerlinear,Input.uv); if(结果.x> 0)返回data.z *结果;否则返回data.w *结果; }
image_sample v [0:3],v [2:4],s [4:11],s [12:11] dmask:0xf s_mov_b64 s [0:1],exec s_waitcnt vmcnt(0)v_cmpx_gt_f32 s [2: 3],v0,0 s_cbranch_execz label_0017
现在,着色器编译器将执行掩码放入使用(哪个控制哪个线程是活动的),使用v_cmpx_gt_f32指令将Per-Thread比较的结果直接存储到其中。当然后执行时,当S_CBRANCH_EXECZ指令(使用执行掩码而不是VCC寄存器的分支)时,将“跳过”的线程将“跳过”。
这是if-stalal的第一个分支,以乘以常量值(data.z)乘以纹理读取指令的结果。与上面的恒定缓冲负载类似,现在需要纹理读取结果,GPU必须确保它们在此处或未定义的行为将发生。为此,着色器编译器添加了另一个待等待指令S_WAITCNT。这次VMCNT操作装置意味着它正在等待向量存储器返回(而不是在常量缓冲器读取的情况下的标量存储器返回)。在代码段的末尾,代码将无条件地跳转到标签_001c以避免执行第二个分支。
这是代码中的第二个分支,要将结果乘以其他常量值(data.w)读取的纹理。专注于v_mul_f32指令,值得呼唤它可以直接与矢量乘以矢量,另一个关于底层硬件的信息。值得注意的是,虽然Float4乘法是HLSL和中间语言的似乎是一个指令,但它实际上是着色器组件中的4个指令,如GCN的设计所示(它与标量架构有关,但我不想要要将其与标量指令和寄存器混为一谈,有很多材料在线描述了它如何为更多细节工作)。
Shader执行现在正在卷绕,所有它仍有待完成的是写出结果。通过恢复程序在程序的开始时恢复存储在Scalars S22和S23中的执行掩码的值,以确保所有必需的线程将写出结果。输出(FLOAT4号)当前存储在向量寄存器V0-V3中。 V_CVT_PKRTZ_F16_F32指令将将2个向量寄存器(例如,V0和V1)的FLOAT32内容包装到一个FLOAT32向量寄存器中。这是两次(V0,V1和V2,V3)中的每次完成两次。最后,我们有2个向量寄存器V0和V1,该寄存器V0和V1将原始FLOAT4以压缩形式输出,以减少内存带宽。最后,exp指令将输出的副本触发到绑定渲染目标。 MRT0参数意味着该指令以可能的多个Rendertarget配置(最多8个rendertargets绑定为输出到像素着色器),下一步遵循保存压缩输出值的向量寄存器,完成意味着这是着色器中的最后一个导出,CLIC表示数据处于压缩形式,并且VM标志表示执行掩码可以用于通知颜色缓冲器有效的颜色缓冲器有效并且已被丢弃。有了这个,着色器停止执行。
我之前提到了如何阅读和理解着色器组件可以帮助在着色器创作期间做出更好的决定。虽然我提供的着色器示例是微不足道的,但不是很有用,但仍然很难看出,在没有内在知识的情况下,仍然可以改进它的编译器将与提供的代码有关。稍微调整着色器代码以获取返回; IF-Matchene Brankes之外,例如,我们可以在程序集中看到编译器完全删除分支,使用4 v_cndmask_b32基于比较指令v_cmp_lt_f32的结果选择输出值。
虽然在这种情况下,它可能不会产生太大的性能差异,因为所有线程都将始终遵循if-statege的一个分支,如果它增加了所使用的矢量寄存器的数量,这是良好的知识,适用于其他场景。底线是,一个人无法轻易判断HLSL着色器如何更改将如何影响最终的着色器组件而不检查它。
我在此着色器装配故障中使用的大多数信息都记录在Vega的ISA参考文档中。如果您有兴趣了解更多GPU,还有一大批低级GPU指南值得研究,以及其他GPU,也是Emil Persson在低级着色器优化上的出色演示。